6 生态假设的经典检验方法
6.1 引言
在生态学研究的广阔领域中,我们常常面临这样的困境:当我们观察到某种现象时,如何判断这是真实的生态规律还是偶然的随机波动?当我们实施某种保护措施后,如何确定它确实产生了预期的效果?这些问题正是统计假设检验所要回答的核心问题。
本章内容概览:本章将系统介绍经典假设检验方法,包括参数检验和传统非参数检验。这些方法是生态统计学的基础,为生态学家提供了在不确定性中做出科学判断的严谨框架。我们将从假设检验的基本概念开始,逐步深入到各种具体的检验方法,包括单样本检验、双样本检验、多样本检验,以及功效分析等关键技术。
这些经典方法构成了生态学研究中统计推断的基石,为后续学习更现代的统计方法奠定坚实基础。假设检验作为生态统计学的基石,是连接生态学理论与实证数据的桥梁。它为我们提供了一套严谨的数学框架,帮助我们在充满不确定性的自然系统中做出科学的判断。
对于生态学本科生而言,掌握假设检验不仅意味着学会一种统计技术,更意味着获得了一种科学的思维方式,一种在复杂生态系统中识别真实信号的能力。
生态学研究本质上是在噪声中寻找信号的过程。自然系统充满了变异——季节变化、随机事件、测量误差等等。假设检验帮助我们区分哪些模式是真实的生态过程,哪些只是随机波动的产物。例如,在研究不同森林类型对鸟类多样性的影响时,我们可能会观察到阔叶林中的鸟类种类似乎比针叶林更多。但这是真实的生态差异,还是抽样偶然性的结果?通过设定零假设(两种森林类型的鸟类多样性无差异)和备择假设(阔叶林中的鸟类多样性更高),然后收集数据并进行\(t\)检验或方差分析,我们可以基于统计证据得出科学结论。这种基于证据而非直觉的判断方式,是现代生态学研究的核心特征。
假设检验的应用贯穿生态学的各个领域。在物种保护中,我们需要检验保护措施是否真的提高了濒危物种的存活率;在入侵生态学中,我们需要判断外来物种是否对本地群落产生了显著影响;在污染生态学中,我们需要评估污染物排放对水生生物多样性的影响程度;在气候变化研究中,我们需要检验温度升高是否确实改变了物种的物候期。每一个生态学问题的背后,都隐藏着一个或多个需要检验的假设。
更重要的是,假设检验不仅仅是数据分析的工具,它在科研的整个过程中都发挥着指导作用。从研究设计阶段开始,假设检验帮助我们明确研究目标,量化科学问题,并制定合理的实验方案。通过功效分析,我们可以在研究开始前评估检测预期效应的可能性,从而优化样本量的选择——既避免样本过小导致无法检测真实效应,也避免样本过大造成资源浪费。例如,在设计一个检验施肥对草地生产力影响的实验时,我们可以基于预期的效应大小、可接受的错误率和期望的统计功效,计算出所需的重复样方数量。这种基于假设检验的前瞻性设计,不仅提高了研究的科学性和效率,还确保了研究结果的可靠性和生态学意义。
在现代生态学的学术交流中,假设检验已经成为一种标准语言。无论是撰写科研论文、参加学术会议,还是评审他人研究,对假设检验的理解都是必不可少的。生态学期刊要求研究者明确陈述他们的科学假设,选择适当的统计检验方法,正确解释p值、置信区间等统计概念,并对多重比较进行必要的校正。这些要求不仅确保了研究的科学严谨性,也促进了生态学知识的积累和进步。
学习假设检验的过程,实际上是在培养一种批判性的科学思维方式。它教会我们如何评估证据的强度,如何区分相关性和因果关系,如何理解统计结论的概率性质。当我们看到“p < 0.05”的结果时,我们学会的不仅仅是如何解释这个数字,更重要的是理解这意味着什么——我们有证据反对零假设,但这种证据不是绝对的,而是基于概率的。这种对不确定性的认识,对“显著”结果保持合理怀疑的态度,是优秀生态学家的重要品质。就像一位经验丰富的生态学家在观察自然现象时既保持开放又保持谨慎一样,统计假设检验教会我们在数据海洋中航行时既要有发现的勇气,也要有质疑的智慧。
让我们通过一个完整的生态学实例来体会假设检验的实际应用。假设我们要研究施肥对草地生产力的影响,我们设计了一个随机化实验:随机分配一半样方接受施肥处理,另一半作为对照。经过一个生长季的观测,我们测量了所有样方的生物量。使用独立样本\(t\)检验比较两组的生物量差异,如果得到p < 0.05的结果,我们有统计证据表明施肥确实提高了草地生产力。但优秀的生态学家不会止步于此——他们还会考虑效应大小(施肥带来的实际增产幅度)、置信区间(效应估计的不确定性范围),以及这个结果的生态学意义。这种全面的思考方式,正是假设检验训练所要达到的目标。
通过本章的学习,生态学本科生将逐步掌握假设检验的核心概念和方法。我们将从经典的参数检验(如\(t\)检验、方差分析)开始,了解它们的基本原理和适用条件;然后探讨非参数检验方法,应对生态数据中常见的非正态分布情况;我们还将学习多重比较校正技术,避免在同时进行多个检验时产生假阳性结果;最后,我们将介绍功效分析的概念,学习如何在研究设计阶段就确保我们的研究有足够的检测力。
假设检验不仅是一套统计工具,更是一种科学的思维方式。它帮助我们在复杂的自然系统中发现规律,在充满不确定性的生态过程中做出明智的判断。掌握假设检验,意味着你不仅学会了如何分析数据,更重要的是学会了如何像生态学家一样思考——严谨、批判、基于证据。这种能力将伴随你的整个科学生涯,无论你将来从事生态研究、环境保护还是资源管理,都将受益无穷。
在接下来的章节中,我们将深入探讨各种假设检验方法的具体应用,通过丰富的生态学实例,帮助你建立起运用统计工具解决实际生态问题的能力。让我们开始这段探索统计推断与生态规律交汇之处的旅程吧——这是一段从直觉走向证据、从猜测走向确信的科学探索之旅。
为了帮助读者更好地理解各种假设检验方法在实际生态研究中的应用,本章将围绕一个贯穿始终的生态学案例——梅花鹿保护研究,系统介绍从单样本检验到多样本检验的各种统计方法。这个案例将为我们提供一个统一的框架,帮助我们理解不同检验方法如何解决具体的生态学问题。
6.2 梅花鹿保护与假设检验
让我们通过一个贯穿本章的生态学案例——梅花鹿保护研究,来深入理解假设检验在生态学中的应用。这个案例将帮助我们直观地理解各种假设检验方法如何解决具体的生态学问题。
梅花鹿保护研究的背景:某自然保护区为了恢复梅花鹿种群,实施了严格的禁猎保护措施。经过5年的保护,研究人员观察到梅花鹿种群数量从保护前的平均每平方公里2.5只增加到保护后的平均每平方公里4.8只。但这是保护措施的真实效果,还是种群自然波动的结果?这个看似简单的问题,实际上包含了多个需要检验的统计假设。
单样本检验的应用:首先,我们需要检验当前梅花鹿种群密度是否达到了保护目标。假设保护目标是每平方公里4只梅花鹿,我们可以使用单样本\(t\)检验来检验观测均值(4.8只/平方公里)是否显著高于目标值(4只/平方公里)。零假设\(H_0\):当前种群密度等于目标值;备择假设\(H_1\):当前种群密度高于目标值。如果p值小于0.05,我们有证据表明种群确实达到了保护目标。
双样本检验的应用:更重要的是,我们需要检验保护措施是否真的有效。由于我们有保护前和保护后的数据,可以使用配对样本\(t\)检验来比较两个时间点的种群密度。零假设\(H_0\):保护前后种群密度无差异;备择假设\(H_1\):保护后种群密度更高。这种检验考虑了同一区域在不同时间的相关性,比独立样本检验更敏感。
多样本检验的应用:如果保护区实施了多种保护措施(如禁猎、栖息地恢复、人工投食),我们需要比较不同措施的效果。这时可以使用方差分析(ANOVA)来检验不同处理组的梅花鹿种群密度是否存在显著差异。如果ANOVA显示总体差异显著,我们还需要进行多重比较(如Tukey HSD检验)来确定具体哪些措施更有效。
非参数检验的应用:生态数据常常不满足正态分布假设。如果梅花鹿种群分布呈现明显的偏态(如少数区域密度极高,多数区域密度较低),我们可以使用非参数检验方法,如Wilcoxon符号秩检验(配对数据)或Kruskal-Wallis检验(多组比较)。这些方法不依赖于严格的正态分布假设,为生态数据提供了更稳健的统计工具。
多重比较校正的必要性:当我们同时比较多种保护措施时,直接进行多个\(t\)检验会增加假阳性风险。例如,比较3种措施需要进行3次两两比较,第一类错误率会从5%膨胀到14%。多重比较校正方法(如Bonferroni校正、Tukey HSD检验)帮助我们控制这种风险,确保统计结论的可靠性。
功效分析的重要性:在研究设计阶段,我们需要确定足够的样本量来检测预期的效应。如果保护措施预期能将梅花鹿密度从2.5只提高到4只,通过功效分析我们可以计算出需要监测多少个样区才能有80%的概率检测到这个差异。这避免了样本过小导致无法发现真实效应,也避免了样本过大造成资源浪费。
生态学意义与统计显著性:即使统计检验显示保护措施显著提高了梅花鹿密度,我们还需要考虑生态学意义。效应大小告诉我们保护措施带来的实际改善程度,置信区间提供了效应估计的不确定性范围。这些信息与统计显著性一起,构成了完整的科学证据。
这个梅花鹿保护案例将贯穿本章的各个部分,帮助我们理解不同假设检验方法如何应用于具体的生态学问题。通过这个连贯的案例,我们将看到统计方法如何从不同角度回答同一个生态学问题,以及如何整合多种证据得出全面的科学结论。
6.2.1 假设检验的基本步骤
假设检验虽然在不同情境下使用不同的统计方法,但都遵循一个通用的基本流程。理解这个通用流程有助于我们从更宏观的角度把握假设检验的本质,无论面对何种统计检验方法,都能保持清晰的思路。
假设检验的通用流程:
明确研究问题与假设设定
- 将生态学问题转化为统计问题(例如:梅花鹿保护措施是否有效?)
- 设定零假设(\(H_0\))和备择假设(\(H_1\))(详见下文零假设与备择假设小节)
- 确定检验类型(单侧或双侧)(详见下文零假设与备择假设小节)
选择适当的统计检验方法
- 经典参数检验:基于理论分布(如\(t\)检验、F检验、\(\chi^2\)检验)(详见下文单样本检验、双样本检验、多样本检验小节)
- 非参数检验:不依赖分布假设(如符号检验、秩和检验)(详见下文非参数检验方法小节)
- 模拟方法:基于随机化或重抽样(如置换检验、蒙特卡洛检验)(详见下文蒙特卡洛检验小节)
例如,在梅花鹿保护研究中,由于我们有保护前和保护后的配对数据,应该选择配对样本\(t\)检验。
设定显著性水平(\(\alpha\))
- 通常设定为0.05,表示愿意接受5%的第一类错误风险(详见下文显著性水平小节)
- 在某些高风险研究中可能使用更严格的水平(如0.01)
在梅花鹿保护研究中,我们设定\(\alpha\)=0.05,表示愿意接受5%的错误宣称保护措施有效的风险。
收集数据并计算检验统计量
- 确保数据质量(独立性、代表性等)
- 计算适当的检验统计量(详见下文检验统计量与p值小节)
在梅花鹿研究中,我们收集保护前和保护后的种群密度数据,计算配对差异的均值和标准差,进而计算\(t\)统计量。
确定p值或临界值
- 经典方法:基于理论分布计算p值(详见下文检验统计量与p值小节)
- 模拟方法:通过随机化构建零分布,计算经验p值(详见下文蒙特卡洛检验小节)
在梅花鹿研究中,我们基于\(t\)分布计算p值,评估在零假设下观测到当前种群增长的概率。
做出统计决策
- 如果p值 < \(\alpha\),拒绝零假设
- 如果p值 ≥ \(\alpha\),不拒绝零假设
例如,如果梅花鹿研究的p值小于0.05,我们拒绝零假设,有统计证据表明保护措施确实有效。
解释结果并考虑生态学意义
- 统计显著性 \(\neq\) 生态学重要性
- 结合效应大小、置信区间和专业知识(详见下文效应大小与置信区间小节)
- 考虑研究的局限性和潜在偏差
在梅花鹿研究中,即使统计上显著,我们还需要评估种群增长的生态学意义:这种增长是否足以维持种群的长期生存?是否达到了保护目标?
模拟方法在假设检验中的特殊步骤:
对于基于模拟的检验方法(如置换检验、蒙特卡洛检验),第5步需要特别处理:
- 构建零模型:根据零假设生成随机数据或重排观测值
- 重复模拟:多次重复模拟过程(通常1000-10000次)
- 构建经验分布:基于模拟结果构建检验统计量的零分布
- 计算经验p值:比较观测统计量与经验分布的位置
生态学意义:这个通用流程体现了科学研究的严谨性。它帮助生态学家在复杂的自然系统中做出基于证据的判断,避免将随机波动误认为生态规律,也避免错过真实的生态效应。无论使用经典检验方法还是模拟方法,这个基本框架都适用,确保我们的统计推断既严谨又具有生态学意义。例如,在梅花鹿保护研究中,这个流程帮助我们科学地评估保护措施的真实效果,避免将种群的自然波动误认为保护成效。
6.2.2 零假设与备择假设
在生态学研究中,我们常常需要回答这样的问题:某种生态干预是否产生了真实效应?不同生境中的物种多样性是否存在显著差异?某个环境因子是否与物种丰度相关?这些问题的核心都可以通过假设检验来回答。
零假设(\(H_0\))是统计检验的起点,它通常表示”无效应”、“无差异”或”无关联”的状态。在生态学语境中,零假设可以理解为:
- 保护措施对种群数量没有影响(例如:梅花鹿保护措施对种群密度没有影响)
- 不同森林类型的鸟类多样性没有差异
- 污染物浓度与水生生物死亡率无关
- 气候变化对物候期没有显著影响
零假设代表了”维持现状”或”没有新发现”的保守立场。在科学研究中,我们倾向于保守,要求有充分的证据才能推翻零假设。这种保守性体现了科学研究的严谨性——我们不会轻易接受新的发现,除非有强有力的证据支持。就像在生态调查中,我们不会因为看到几只鸟就断言整个种群发生了变化一样,统计检验要求我们保持谨慎和怀疑的态度。
为什么零假设通常是“无效应”状态?
零假设通常设定为“无效应”状态,这背后有着深刻的统计学和科学哲学原因。首先,从科学哲学的角度来看,可证伪性原则要求科学理论必须能够被潜在的证据所证伪。卡尔·波普尔强调的这一原则意味着,零假设作为”无效应”状态具有明确的证伪标准——如果我们观察到足够强的证据表明存在效应,就可以拒绝零假设。相比之下,复杂的零假设往往难以明确证伪,缺乏清晰的证伪标准。
其次,简约性原则(奥卡姆剃刀)在科学推理中起着重要作用。科学倾向于选择最简单的解释,除非有充分的证据支持更复杂的解释。“无效应”是最简单的假设,它不需要引入额外的参数或机制。只有当数据强烈支持时,我们才接受更复杂的备择假设。这种保守的态度有助于防止过度解释和假阳性发现。
从统计检验的逻辑结构来看,假设检验遵循“无罪推定”的逻辑框架。我们首先假设没有效应存在,然后寻找证据来反驳这个假设。这种结构确保了明确的决策标准——我们可以基于p值做出统计决策;可控的错误率——我们能够精确控制第一类错误的概率;以及可计算的概率——在零假设下,检验统计量的分布是已知的,便于计算p值。
数学上的便利性也是重要考量因素。“无效应”的零假设通常对应着已知的概率分布:均值差异为零对应\(t\)分布,方差比值为1对应F分布,观测频数等于期望频数对应卡方分布。这些已知分布使得我们可以精确计算p值和临界值,为统计推断提供了坚实的数学基础。
设定“无效应”的零假设还体现了科学的保守精神。我们不会轻易接受新的理论或发现,新理论必须通过严格的证据检验。这种保守性有助于防止假阳性发现和科学研究的过度解读,确保科学知识的稳健积累。
在生态学研究的实际考虑中,自然系统本身就充满了变异和噪声。设定“无效应”的零假设帮助我们区分真实的生态模式与随机波动,避免将偶然的相关性误认为因果关系,确保我们的发现具有统计稳健性。
虽然理论上可以设定更复杂的零假设(如“效应大小为0.5”而非“效应大小为0”),但这会带来诸多问题:难以确定合适的复杂零假设值,检验统计量的分布可能未知,难以解释p值的实际意义,增加了统计检验的主观性。
在某些特殊情况下,我们确实会使用非零的零假设,如等效性检验(检验效应是否小于某个有意义的阈值)、非劣效性检验(在医学试验中检验新疗法是否不劣于标准疗法)或基于先验知识的生物学零假设。然而,在大多数生态学研究中,“无效应”的零假设仍然是最常用和最合适的选择,因为它提供了清晰的统计框架、可解释的结果和稳健的科学推断。
备择假设(\(H_1\))则是我们想要证明的假设,它表示存在“有效应”、“有差异”或“有关联”。备择假设可以是:
- 保护措施提高了种群数量(例如:梅花鹿保护措施提高了种群密度)
- 阔叶林的鸟类多样性高于针叶林
- 污染物浓度与水生生物死亡率正相关
- 气候变化导致物候期提前
备择假设可以是单侧的(directional)或双侧的(non-directional)。单侧备择假设指定了效应的方向(如施肥提高了生产力),而双侧备择假设只关心是否存在差异,不指定方向(如施肥改变了生产力)。选择单侧还是双侧检验取决于研究问题的具体性质。
生态学意义:零假设和备择假设的设定直接反映了我们要检验的生态学问题。它们将模糊的生态学疑问转化为明确的统计问题,为后续的数据收集和分析提供了清晰的框架。正确的假设设定是生态学研究成功的关键第一步。
在梅花鹿保护研究中,我们设定: - 零假设(\(H_0\)):保护前后梅花鹿种群密度无差异(\(\mu_{\text{保护后}} = \mu_{\text{保护前}}\)) - 备择假设(\(H_1\)):保护后梅花鹿种群密度高于保护前(\(\mu_{\text{保护后}} > \mu_{\text{保护前}}\))
这是一个单侧检验,因为我们预期保护措施会提高种群密度。这种明确的假设设定为后续的统计分析提供了清晰的方向。
让我们再次通过一个具体的生态学实例来理解假设设定:
实例:施肥对草地生产力的影响
假设我们研究施肥对草地生态系统生产力的影响。我们随机分配20个样方,其中10个接受施肥处理,10个作为对照。经过一个生长季,我们测量每个样方的地上生物量。
- 零假设(\(H_0\)):施肥组和对照组的平均生物量没有差异(\(\mu_{\text{施肥}} = \mu_{\text{施肥}}\))
- 备择假设(\(H_1\)):施肥组和对照组的平均生物量存在差异(\(\mu_{\text{施肥}} \neq \mu_{\text{施肥}}\))
这是一个双侧检验的例子,因为我们没有预设施肥一定会提高生产力(在某些情况下,过度施肥可能反而抑制生长)。
为了更好地理解零假设与备择假设的分布关系,让我们生成一个可视化图表:
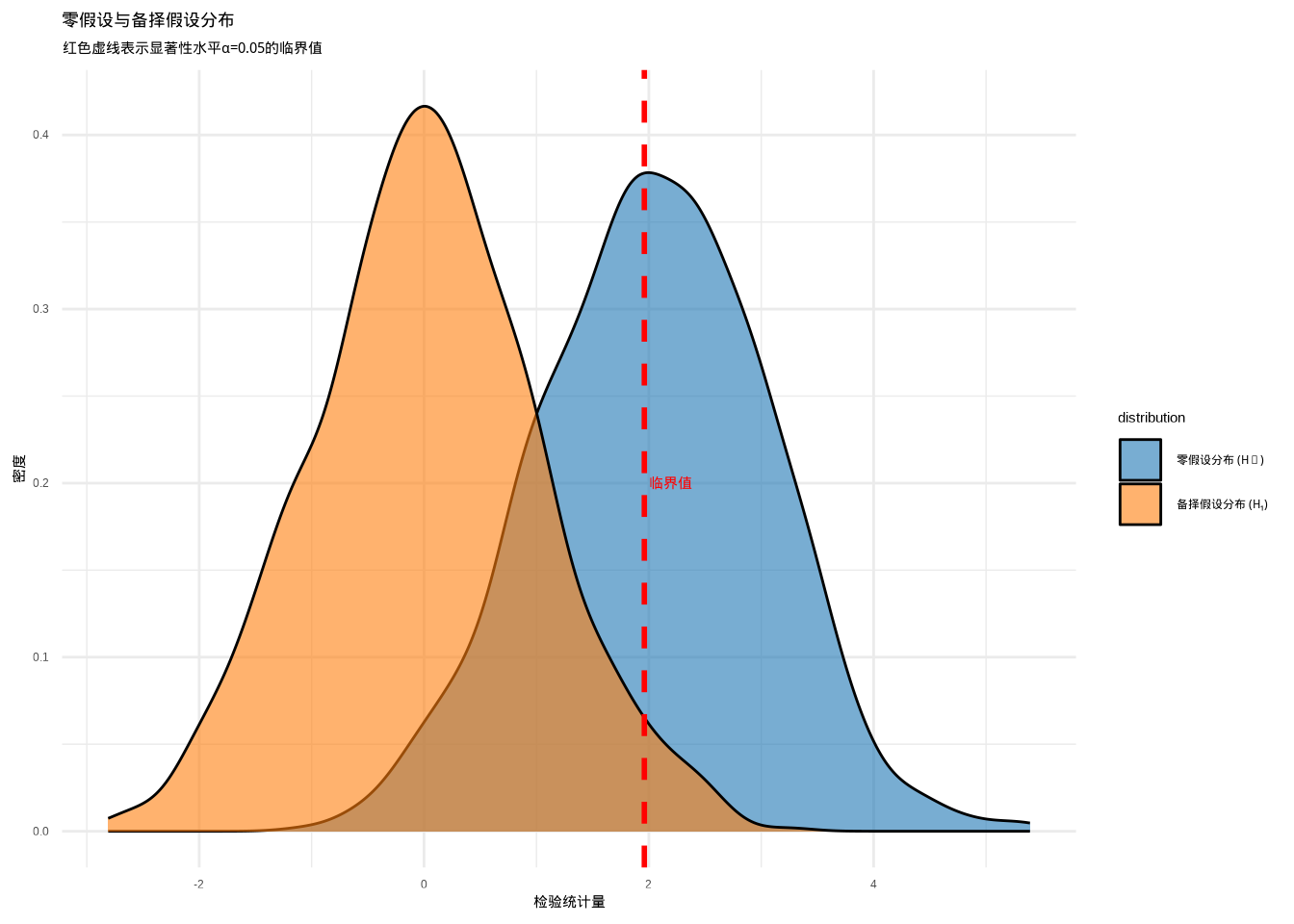
图6.1: 零假设与备择假设分布比较:展示在零假设(蓝色)和备择假设(橙色)下检验统计量的概率分布,以及显著性水平的临界值。通过颜色和分布形状的组合,确保在彩色显示和黑白打印时都能清晰区分不同类型的统计分布。
这个图表直观展示了在零假设(蓝色)和备择假设(橙色)下的检验统计量分布。红色虚线表示显著性水平\(\alpha\)=0.05的临界值,当检验统计量超过这个临界值时,我们就有足够的证据拒绝零假设。
6.2.3 检验统计量与p值
一旦设定了假设,我们就需要收集数据并计算检验统计量。检验统计量是一个基于样本数据计算的数值,它量化了观测数据与零假设的偏离程度。不同的统计检验使用不同的检验统计量:
- \(t\)检验:使用\(t\)统计量,衡量样本均值与理论值(或两个样本均值)的差异相对于抽样误差的大小
- 方差分析(ANOVA):使用F统计量,衡量组间变异与组内变异的比值
- 卡方检验:使用\(\chi^2\)统计量,衡量观测频数与期望频数的差异
检验统计量的计算公式考虑了样本大小、变异程度等因素,使得不同研究的结果可以进行比较。
p值是假设检验中最核心的概念之一。p值定义为:在零假设为真的前提下,观测到当前检验统计量值或更极端值的概率。换句话说,p值告诉我们,如果零假设成立,我们有多大可能看到实际观测到的数据(或更极端的数据)。
在梅花鹿保护研究中,p值表示:如果保护措施实际上没有效果(零假设为真),我们观测到当前种群增长(或更大增长)的概率有多大。
p值的解释需要特别注意:
- p值不是零假设为真的概率
- p值不是备择假设为真的概率
- p值不是效应大小的度量
- p值是在零假设下观测到当前证据强度的概率
生态学意义:p值为我们提供了量化证据强度的工具。一个很小的p值(如p < 0.05)表明,如果零假设成立,我们观测到的数据是非常不可能的。这为我们拒绝零假设提供了统计依据。然而,p值的大小并不直接反映生态学重要性——一个统计上显著的结果可能在生态学上微不足道,反之亦然。
在梅花鹿保护研究中,即使我们得到p < 0.05的结果,表明保护措施统计上显著,我们还需要考虑这种种群增长的生态学意义:这种增长是否足以维持种群的长期生存?是否达到了保护目标?同样,如果p值不显著,我们也不能简单地认为保护措施无效,而应该考虑样本量是否足够、效应大小是否具有生态学意义等问题。
为了更直观地理解p值的概念,让我们通过R代码生成一个可视化图表:
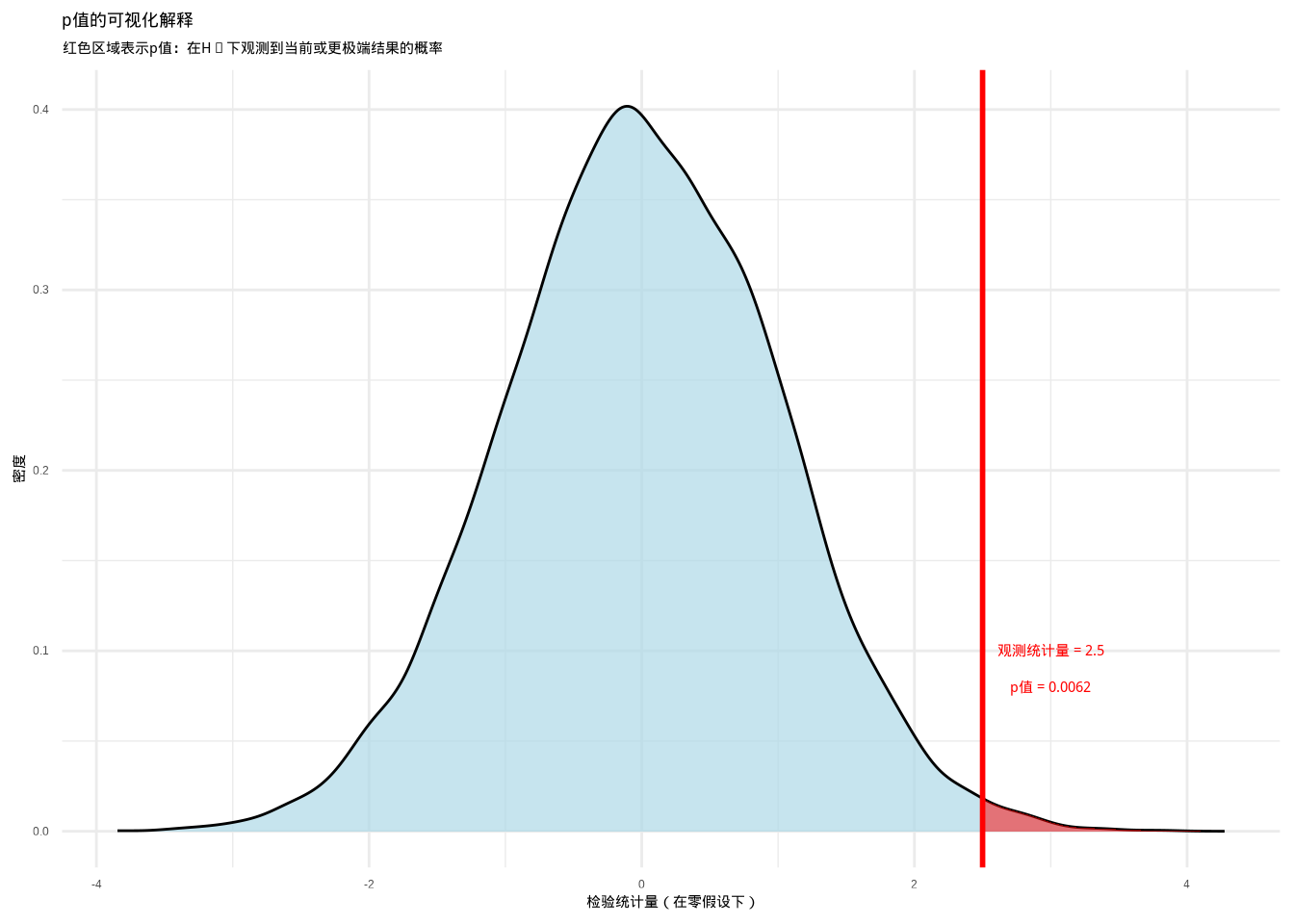
图6.2: p值的可视化解释:通过概率密度函数展示p值作为在零假设下观测到当前或更极端检验统计量的概率。红色区域表示p值区域,通过颜色和填充纹理的组合增强可辨识度。
这个图表通过红色区域直观展示了p值的概念,即在零假设下观测到当前检验统计量值(红色垂直线)或更极端值的概率。p值越小,表明观测到的数据在零假设下越不可能发生,从而为我们拒绝零假设提供了更强的证据。
6.2.4 显著性水平
显著性水平(\(alpha\))是我们在检验开始前设定的阈值,用于决定何时拒绝零假设。常用的显著性水平是\(alpha\) = 0.05,这意味着我们愿意接受5%的错误拒绝零假设的风险。在某些更严格的研究中,也可能使用\(alpha\) = 0.01或更小的值。
显著性水平的选择涉及第一类错误和第二类错误的权衡,这是假设检验中最容易混淆但至关重要的概念。
第一类错误,也称为假阳性错误,即零假设实际上为真时我们却错误地拒绝了它。这相当于“冤枉好人”的情况——我们错误地宣称存在某种效应或差异,而实际上这种效应或差异并不存在。第一类错误的概率由显著性水平\(alpha\)直接控制。当我们设定\(alpha\) = 0.05时,意味着即使零假设为真,我们也有5%的概率会错误地拒绝它。
在梅花鹿保护研究中,第一类错误意味着:实际上保护措施没有效果,但我们错误地宣称它有效。这可能导致我们继续投入资源实施无效的保护措施,浪费有限的保护资金。
第二类错误,也称为假阴性错误,即备择假设实际上为真时,我们却错误地没有拒绝零假设。这相当于“放过坏人”的情况——我们未能检测到真实存在的效应或差异。第二类错误的概率用\(\beta\)表示,其补数1-\(\beta\)就是统计功效,即正确拒绝错误零假设(或正确检测到真实效应)的概率。
在梅花鹿保护研究中,第二类错误意味着:实际上保护措施有效果,但我们未能检测到这种效应。这可能导致我们放弃有效的保护措施,让梅花鹿种群继续面临威胁,错失重要的保护机会。
这两类错误在生态学研究中具有不同的后果和重要性。第一类错误的后果往往是浪费资源——我们可能基于错误的发现投入大量人力物力去实施无效的保护措施,或者制定不必要的环境管制政策。例如,如果我们错误地宣称某种农药对非靶标昆虫有害(第一类错误),可能导致农民放弃使用有效的害虫控制方法,造成经济损失。
相比之下,第二类错误的后果往往是错失机会——我们可能因为未能检测到真实效应而错过重要的保护机会,或者忽视真实的环境风险。例如,如果我们未能检测到某种污染物对水生生物的真实毒性(第二类错误),可能导致生态系统持续受到损害,甚至造成不可逆的生态破坏。
在保护生物学研究中,第二类错误的后果往往比第一类错误更为严重。错过一个真实的保护效应意味着濒危物种可能继续面临威胁,生态系统可能持续退化。因此,在保护生物学中,我们可能愿意接受更高的\(\alpha\)水平(如0.10)来降低第二类错误的风险,确保不会错过重要的保护机会。
相反,在涉及重大政策决策或资源分配的研究中,第一类错误的后果可能更为严重。例如,在评估某种新型农药的环境安全性时,错误地宣称其安全(第二类错误)可能导致广泛的生态破坏,而错误地宣称其有害(第一类错误)可能只是造成一些经济损失。在这种情况下,我们可能选择更严格的\(\alpha\)水平(如0.01)来减少假阳性的风险。
让我们通过决策矩阵来系统理解这两类错误:
| 统计决策 真实情况 | 零假设为真 | 备择假设为真 |
|---|---|---|
| 拒绝零假设 | 第一类错误(\(\alpha\)) | 正确决策(1-\(\beta\)) |
| 不拒绝零假设 | 正确决策(1-\(\alpha\)) | 第二类错误(\(\beta\)) |
这个矩阵清晰地展示了统计决策与真实情况之间的关系,帮助我们理解在什么情况下我们的决策是正确的,在什么情况下会犯错误。在实际的生态学研究中,我们需要根据具体研究问题的性质在这两类错误之间进行权衡。这种权衡不仅涉及统计考量,还涉及生态学、经济学和社会学的多方面因素。优秀的生态学家会综合考虑这些因素,选择适当的显著性水平,并在解释研究结果时充分考虑两类错误的潜在影响。
让我们通过几个具体的生态学案例来进一步理解这两类错误的实际意义:
案例一:入侵物种风险评估
假设我们研究某种外来植物是否会对本地生态系统造成危害。零假设是该植物不会对本地生态系统产生显著影响。如果我们错误地拒绝这个零假设(第一类错误),我们可能会投入大量资源去控制一个实际上无害的物种,造成不必要的经济损失。如果我们错误地没有拒绝这个零假设(第二类错误),我们可能会忽视一个真正的生态威胁,导致本地生态系统遭受不可逆的破坏。在这种情况下,第二类错误的后果通常更为严重,因此我们可能愿意接受较高的第一类错误风险来确保不会错过真正的威胁。
案例二:保护措施效果评估
假设我们评估梅花鹿保护措施对种群密度的影响。零假设是保护措施没有效果。如果我们错误地拒绝这个零假设(第一类错误),我们可能会继续投入资源实施无效的保护措施,浪费有限的保护资金。如果我们错误地没有拒绝这个零假设(第二类错误),我们可能会放弃一个真正有效的保护方法,导致梅花鹿种群继续面临威胁。在保护生物学中,第二类错误的后果往往更为严重,因为错过一个有效的保护机会可能意味着物种的持续衰退。
案例三:污染物生态毒性研究
假设我们研究某种工业废水对水生生物的影响。零假设是废水对水生生物没有毒性。如果我们错误地拒绝这个零假设(第一类错误),我们可能会要求企业投入大量资金建设不必要的污水处理设施,增加生产成本。如果我们错误地没有拒绝这个零假设(第二类错误),我们可能会允许有毒废水继续排放,导致水生生态系统遭受长期损害。在这种情况下,两类错误的后果都需要认真权衡,通常需要综合考虑生态风险和经济成本。
理解第一类错误和第二类错误的区别对于正确解释统计结果至关重要。当我们看到“p < 0.05”的结果时,我们不仅要知道这提供了拒绝零假设的证据,还要意识到这个结论可能有5%的概率是错误的(第一类错误)。同样,当我们看到“p > 0.05”的结果时,我们不能简单地认为“没有效应”,而应该考虑第二类错误的可能性——也许效应确实存在,但我们的研究没有足够的统计功效来检测它。
为什么第一类错误通常控制在0.05水平?
第一类错误水平\(\alpha\) = 0.05的选择有着深厚的历史和科学传统。这个标准可以追溯到20世纪早期统计学家罗纳德·费舍尔的工作,他建议使用5%作为判断统计显著性的经验法则。这个选择并非基于严格的数学推导,而是基于实践考虑:5%提供了一个合理的平衡点,既不会过于宽松导致过多假阳性,也不会过于严格导致难以发现真实效应。在生态学中,这个标准已经被广泛接受,因为它提供了一个相对保守但又不是过于保守的决策阈值。
为什么第二类错误往往控制得相对更高?
第二类错误水平\(\beta\)通常设定在0.20左右,对应的统计功效为0.80。这意味着我们愿意接受20%的概率错过真实存在的效应。这个选择主要基于以下几个原因:
首先,从实际可行性考虑,要达到更高的统计功效(如0.90或0.95)通常需要极大的样本量,这在生态学研究中往往难以实现。生态学研究常常受到时间、经费和可行性的限制,过高的功效要求可能导致研究无法实施。
其次,从错误后果的权衡来看,在许多生态学情境中,第二类错误的后果虽然严重,但通常不像第一类错误那样会立即导致错误的决策。第一类错误可能直接导致我们实施无效的措施或制定错误的政策,而第二类错误更多是错失机会,这种后果往往可以通过后续研究来弥补。
此外,统计功效为0.80被认为是一个合理的折中点。这意味着我们有80%的概率检测到真实存在的效应,这个水平在大多数研究情境下被认为是足够的。当然,在特定的高风险研究中(如涉及濒危物种保护或重大环境风险评估),我们可能需要更高的功效(如0.90或0.95)。
最后,从资源分配的角度看,将功效从0.80提高到0.90通常需要不成比例地增加样本量。例如,在某些情况下,功效从0.80提高到0.90可能需要样本量增加50%甚至更多,这种投入产出比往往不被认为是合理的。
在生态学研究中,避免这两类错误的最佳策略包括:进行充分的功效分析来确定合适的样本量,使用适当的统计方法,考虑多重比较校正,以及结合效应大小和置信区间来全面评估研究结果。通过这种全面的方法,我们可以在统计严谨性和生态学实用性之间找到平衡,为生态保护和管理决策提供更可靠的科学依据。
为了更好地理解第一类错误和第二类错误的概念,让我们生成一个可视化图表:
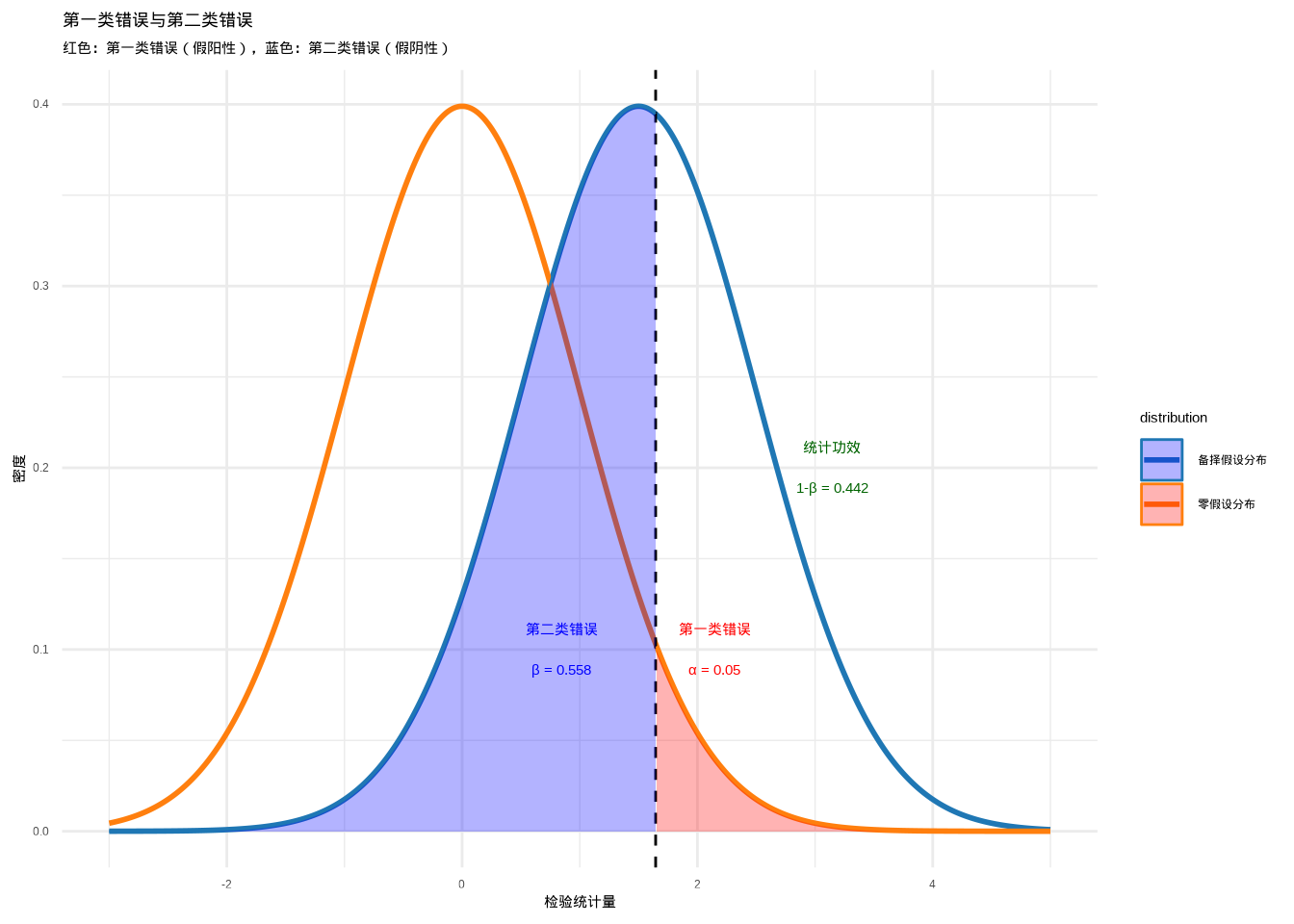
图6.3: 第一类错误与第二类错误的可视化:展示假阳性(第一类错误,红色区域)和假阴性(第二类错误,蓝色区域)在统计决策中的概率分布。通过颜色和填充纹理的组合区分不同类型的统计错误。
这个图表清晰地显示了第一类错误(红色区域,假阳性)和第二类错误(蓝色区域,假阴性)的概念,以及统计功效(1-\(\beta\))作为正确检测真实效应的概率。在生态学研究中,我们需要在这两类错误之间进行权衡,根据研究的具体目的选择合适的显著性水平。
统计功效受到多个因素的影响,其中样本量是一个关键因素。让我们图表来展示样本量如何影响统计功效:
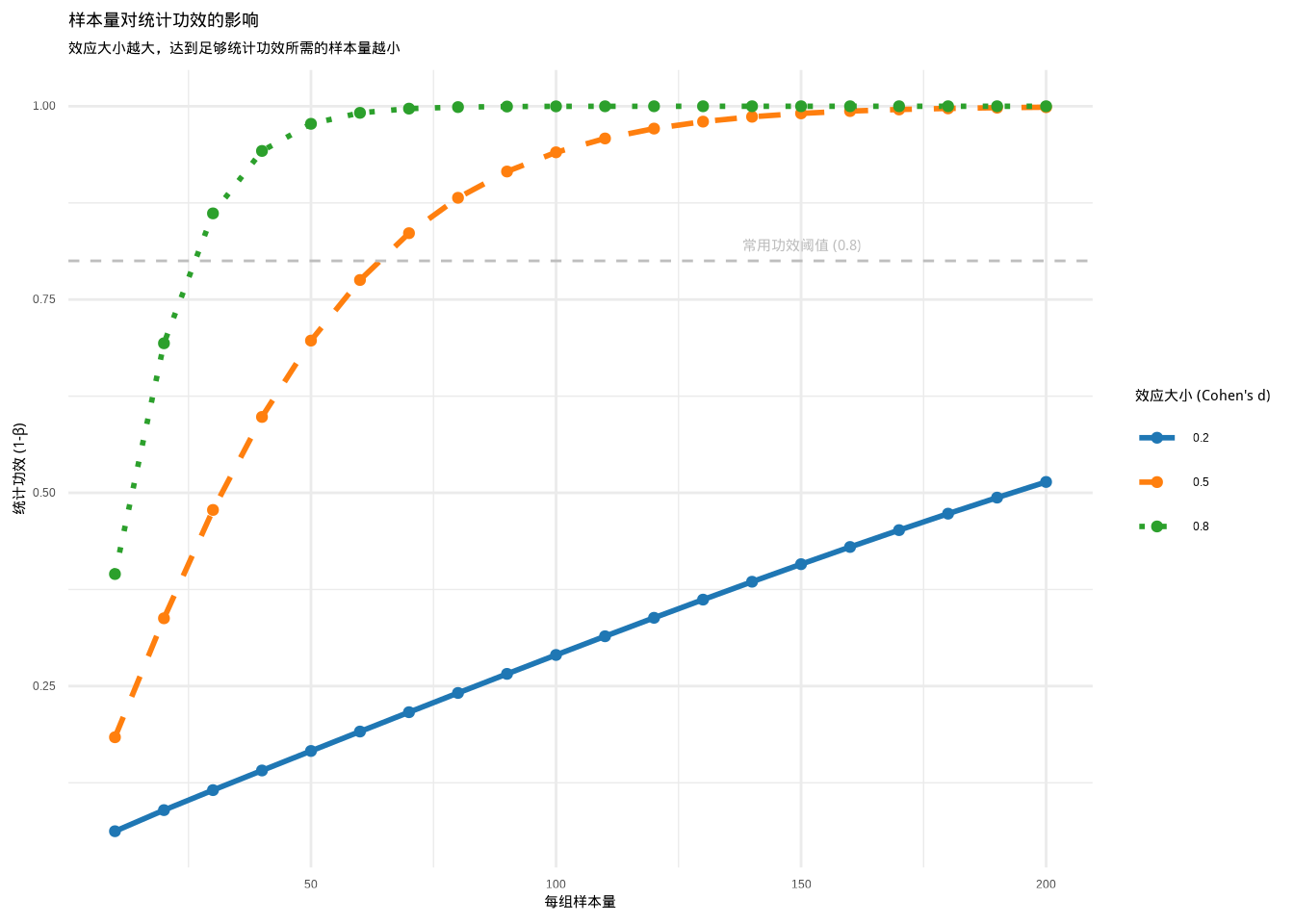
图6.4: 样本量对统计功效的影响:展示在不同效应大小(蓝色、橙色、绿色线条)下,样本量增加如何提高统计功效。通过颜色和线条类型的组合区分不同效应大小。
这个图表展示了不同效应大小下,样本量如何影响统计功效。通常我们期望统计功效达到0.8以上(灰色虚线),这意味着我们有80%的概率正确检测到真实存在的效应。从图表可以看出,效应大小越大,达到足够统计功效所需的样本量越小。
在生态学研究中,我们不仅要关注统计显著性,更要考虑生态学显著性。一个统计上显著但效应大小很小的结果可能在生态学上并不重要。因此,优秀的生态学家会同时报告p值、效应大小和置信区间,为读者提供全面的信息来评估研究结果的实际意义。
6.2.5 效应大小与置信区间
在生态学研究中,仅仅知道某个效应是否统计显著是不够的。我们还需要了解这个效应有多大(效应大小)以及我们对这个效应的估计有多精确(置信区间)。这两个概念为我们提供了比p值更丰富的信息,帮助我们评估研究结果的生态学重要性。
效应大小(Effect Size)
效应大小是衡量研究结果实际重要性的量化指标,它描述了自变量对因变量的影响程度。与p值不同,效应大小不受样本量的影响,因此能够更直接地反映生态学重要性。
常见的效应大小指标包括:
Cohen’s d:用于\(t\)检验,表示标准化均值差异 \[d = \frac{\bar{x}_1 - \bar{x}_2}{s_{pooled}}\] 其中\(s_{pooled}\)是合并标准差
\(\eta^2\)(eta平方):用于方差分析,表示方差解释比例 \[\eta^2 = \frac{SS_{between}}{SS_{total}}\]
\(R^2\)(决定系数):用于回归分析,表示模型解释的变异比例
Cramér’s V:用于卡方检验,表示分类变量间的关联强度
在生态学研究中,效应大小的解释需要结合具体情境。例如,一个d = 0.2的效应在保护生物学中可能具有重要意义,而在某些生理学研究中可能微不足道。
在梅花鹿保护研究中,Cohen’s d可以衡量保护措施带来的标准化种群增长。如果d=0.8(大效应),表明保护措施产生了显著的生态效应;如果d=0.2(小效应),即使统计上显著,其生态学意义也需要谨慎评估。
置信区间(Confidence Interval)
置信区间提供了效应估计的不确定性范围(在之前章节中详细介绍过)。一个95%的置信区间意味着,如果我们重复进行同样的研究100次,大约有95次的置信区间会包含真实的总体参数。
置信区间的生态学意义:
- 估计精度:窄的置信区间表示估计更精确
- 效应方向:置信区间是否包含零值(无效应)
- 生态学重要性:置信区间是否包含有生态学意义的阈值
例如,在研究梅花鹿保护措施的效果时,我们可能得到平均种群增长为2.3只/平方公里,95%置信区间为[1.5, 3.1]只/平方公里。这个结果告诉我们:
- 保护效应是统计显著的(置信区间不包含0)
- 真实的保护效应可能在1.5-3.1只/平方公里之间
- 这个效应大小在生态学上具有重要意义,因为从2.5只增加到4.8只意味着种群密度几乎翻倍
让我们用一个图来理解效应大小和置信区间的概念:
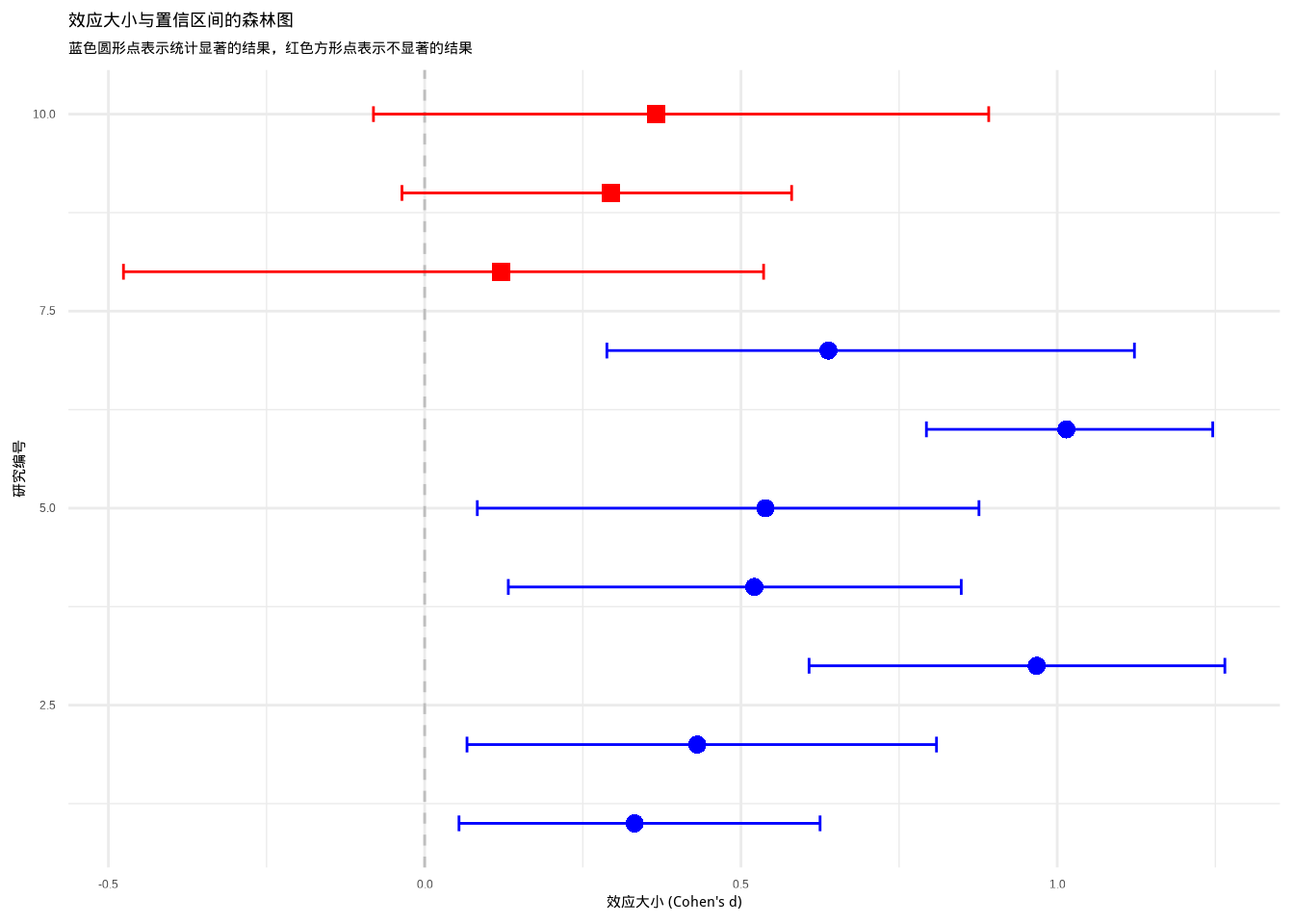
图6.5: 效应大小与置信区间的可视化:通过森林图展示多个研究的效应大小估计及其不确定性范围。蓝色圆形点表示统计显著的结果,红色方形点表示不显著的结果,通过颜色和形状的组合增强可辨识度。
这个图表展示了多个研究的效应大小估计及其置信区间。我们可以清楚地看到哪些研究的结果是统计显著的(置信区间不包含0),以及不同研究的效应大小估计。
生态学意义:在生态学研究中,同时报告效应大小和置信区间有助于:
- 避免过度解读p值:一个很小的p值可能对应很小的效应大小
- 促进结果比较:不同研究的效应大小可以直接比较
- 指导实践决策:基于效应大小评估干预措施的生态学重要性
- 支持元分析:为后续的综述研究提供必要信息
优秀的生态学研究应该同时关注统计显著性和生态学重要性。通过结合p值、效应大小和置信区间,我们能够对研究结果做出更全面、更合理的解释,为生态保护和管理决策提供更可靠的科学依据。
在掌握了假设检验的基本概念后,让我们开始探讨具体的检验方法。我们将从最简单的单样本检验开始,逐步深入到更复杂的双样本和多样本检验。这种渐进式的学习路径将帮助我们建立坚实的统计基础,为后续更复杂的分析做好准备。
6.3 种群基准:单样本检验
在生态保护实践中,我们常常需要评估某个生态指标是否达到特定的基准水平。例如,检验梅花鹿种群密度是否达到保护目标、河流pH值是否偏离中性标准、或者土壤重金属浓度是否超过环境安全阈值。单样本检验方法正是为此类生态基准验证问题提供了科学的统计工具。
6.3.1 单样本\(t\)检验
在生态学研究中,我们常常需要检验某个样本的均值是否与特定的理论值或期望值存在显著差异。单样本\(t\)检验就是用于这种目的的参数检验方法。
单样本\(t\)检验的基本思想是比较样本均值与理论值之间的差异是否具有统计显著性。其零假设和备择假设通常设定为:
- 零假设(\(H_0\)):样本均值等于理论值(\(\mu = \mu_0\))
- 备择假设(\(H_1\)):样本均值不等于理论值(\(\mu \neq \mu_0\)),或者根据研究问题设定为单侧检验
检验统计量\(t\)的计算公式为:
\[t = \frac{\bar{x} - \mu_0}{s/\sqrt{n}}\]
其中\(\bar{x}\)是样本均值,\(\mu_0\)是理论值,\(s\)是样本标准差,\(n\)是样本量。这个统计量服从自由度为\(n-1\)的\(t\)分布。
为什么\(t\)统计量服从\(t\)分布?
要理解为什么\(t\)统计量服从\(t\)分布,我们需要从统计理论的角度来分析这个公式的构成。
首先,考虑分子部分\(\bar{x} - \mu_0\)。根据中心极限定理,样本均值\(\bar{x}\)的抽样分布近似正态分布,其均值为总体均值\(\mu\),标准差为\(\sigma/\sqrt{n}\)(其中\(\sigma\)是总体标准差)。在零假设\(H_0: \mu = \mu_0\)下,我们有:
\[\frac{\bar{x} - \mu_0}{\sigma/\sqrt{n}} \sim N(0,1)\]
也就是说,如果我们知道总体标准差\(\sigma\),这个标准化统计量就服从标准正态分布。
然而,在实际研究中,我们通常不知道总体标准差\(\sigma\),只能用样本标准差\(s\)来估计它。当我们用\(s\)代替\(\sigma\)时,统计量的分布就发生了变化。具体来说:
- 分子\(\bar{x} - \mu_0\)服从正态分布
- 分母\(s/\sqrt{n}\)是样本标准误的估计
- 这两个量是相关的,因为\(s\)也是从样本中计算出来的
统计学家威廉·戈塞特(笔名”Student”)在1908年证明了,当总体服从正态分布时,这个统计量服从\(t\)分布:
\[t = \frac{\bar{x} - \mu_0}{s/\sqrt{n}} \sim t_{n-1}\]
其中\(t_{n-1}\)表示自由度为\(n-1\)的\(t\)分布。
自由度\(n-1\)的来源
自由度\(n-1\)的出现是因为我们在计算样本标准差\(s\)时损失了一个自由度。样本标准差的计算公式为:
\[s = \sqrt{\frac{\sum_{i=1}^n (x_i - \bar{x})^2}{n-1}}\]
分母使用\(n-1\)而不是\(n\)是为了使\(s^2\)成为总体方差\(\sigma^2\)的无偏估计。这个\(n-1\)就是自由度的来源。
\(t\)分布与正态分布的关系
\(t\)分布与正态分布形状相似,都是钟形曲线,但\(t\)分布的尾部更厚。这意味着在相同的显著性水平下,\(t\)分布的临界值比正态分布更大。当样本量\(n\)增大时,\(t\)分布逐渐接近正态分布:
- 当\(n \to \infty\)时,\(t\)分布趋近于标准正态分布
- 对于小样本(如\(n < 30\)),\(t\)分布与正态分布的差异比较明显
- 对于大样本(如\(n > 30\)),\(t\)分布与正态分布非常接近
这种性质使得\(t\)检验特别适用于小样本情况,而大样本时\(t\)检验与\(z\)检验的结果会非常接近。
在生态学研究中,由于样本量往往有限,\(t\)检验提供了比\(z\)检验更准确的推断。当我们使用样本标准差\(s\)代替未知的总体标准差\(\sigma\)时,\(t\)分布恰当地考虑了这种估计带来的不确定性,使得我们的统计推断更加保守和可靠。
生态学意义:单样本\(t\)检验在生态学中有广泛的应用。例如,我们可以检验:
- 某个湖泊的pH值是否偏离中性(pH = 7)
- 某种鸟类的平均体重是否与文献记载的标准值一致
- 某个保护区内的物种丰富度是否达到预期的保护目标
- 某种污染物的浓度是否超过环境安全标准
- 梅花鹿种群密度是否达到保护目标(如每平方公里4只)
让我们通过一个具体的生态学实例来理解单样本\(t\)检验的应用:
实例:检验梅花鹿种群密度是否达到保护目标
假设我们研究某自然保护区内的梅花鹿种群,想要检验其密度是否达到保护目标(每平方公里4只)。我们在保护区的不同区域采集了15个样方,测量梅花鹿密度。
- 零假设(\(H_0\)):当前梅花鹿的平均密度等于4只/平方公里(\(\mu = 4\))
- 备择假设(\(H_1\)):当前梅花鹿的平均密度大于4只/平方公里(\(\mu > 4\))
这是一个单侧检验,因为我们只关心种群密度是否达到或超过保护目标。如果检验结果显示p < 0.05,我们有统计证据表明梅花鹿种群确实达到了保护目标。
单样本\(t\)检验的使用需要满足一些前提条件:数据应该近似正态分布,观测值之间相互独立。如果数据严重偏离正态分布,或者样本量很小,我们可能需要考虑使用非参数检验方法。
为了更好地理解单样本\(t\)检验的原理,让我们通过一个图来理解:
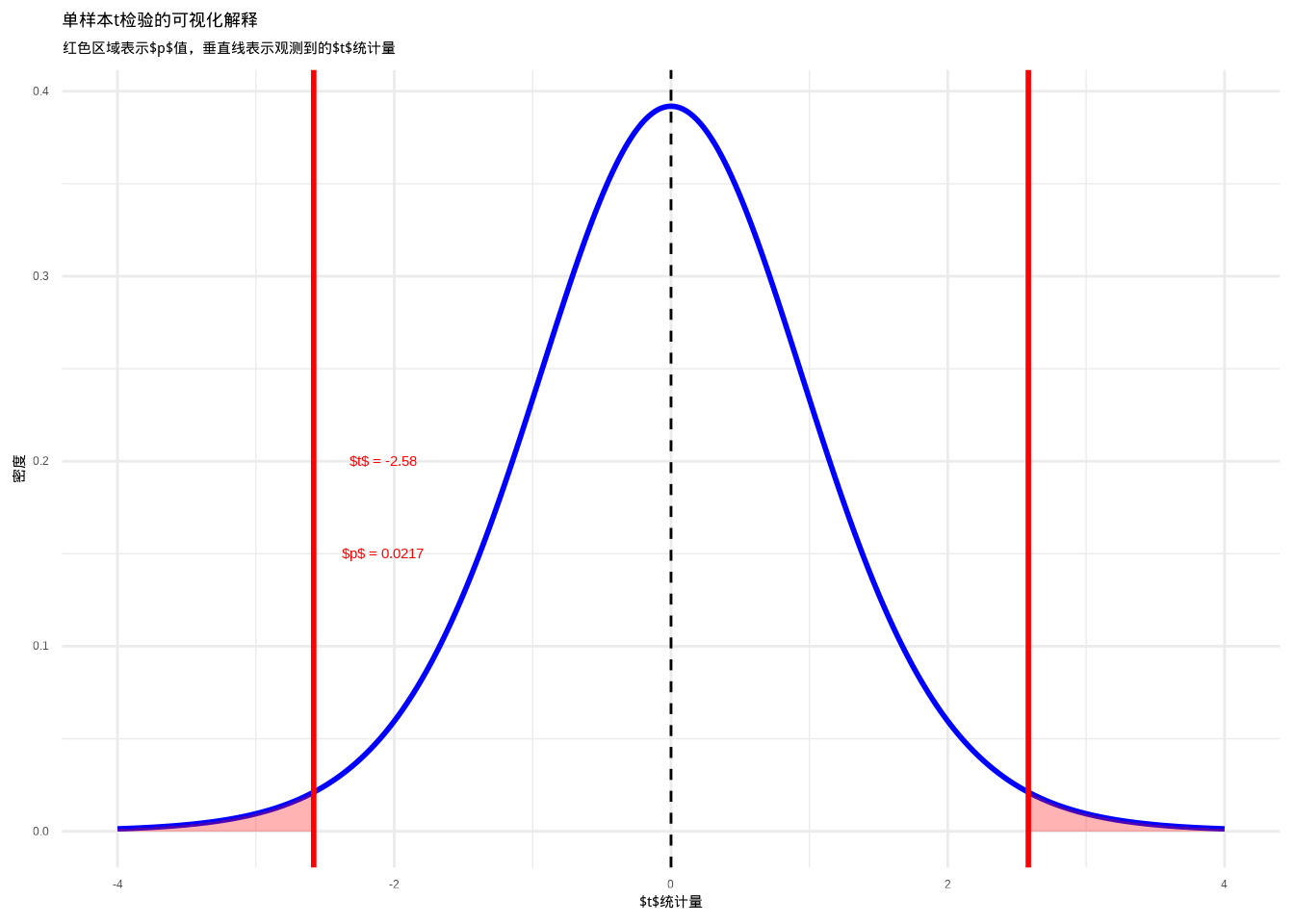
图6.6: 单样本t检验的可视化解释:展示t分布、观测t统计量以及对应的p值区域。红色区域表示p值区域,通过颜色和填充纹理的组合增强可辨识度。
这个图表直观展示了单样本\(t\)检验的原理。蓝色曲线表示在零假设下的\(t\)分布,红色垂直线表示我们观测到的\(t\)统计量,红色区域表示\(p\)值——在零假设下观测到当前或更极端\(t\)值的概率。
6.3.2 单样本符号检验
当数据不满足正态分布假设,或者我们想要检验中位数而不是均值时,单样本符号检验提供了一个强大的非参数替代方法。与\(t\)检验不同,符号检验不依赖于数据的分布形态,而是基于观测值与理论值之间差异的符号(正负号)来进行统计推断。
单样本符号检验的基本思想很简单:对于每个观测值,我们计算其与理论值的差异,然后只关注这些差异的符号(正号或负号),忽略差异的大小。检验统计量通常是正号(或负号)的数量。
其零假设和备择假设通常设定为:
- 零假设(\(H_0\)):样本中位数等于理论值(\(M = M_0\))
- 备择假设(\(H_1\)):样本中位数不等于理论值(\(M \neq M_0\)),或者根据研究问题设定为单侧检验
在零假设下,正号和负号应该以相等的概率出现,因此检验统计量服从二项分布\(B(n, 0.5)\),其中\(n\)是有效样本量(排除等于理论值的观测)。
生态学意义:单样本符号检验在生态学中特别适用于以下情况:
- 数据严重偏离正态分布,存在极端值或偏态分布
- 样本量很小,无法可靠地检验正态性
- 测量尺度是序数的,或者数据只包含相对大小信息
- 我们更关心中位数而不是均值,因为中位数对极端值不敏感
例如,我们可以使用符号检验来:
- 检验某种污染物的中位浓度是否超过环境标准
- 比较某个物种在不同年份的个体大小中位数是否有变化
- 检验某个生态指标的中位数是否达到管理目标
让我们通过一个具体的生态学实例来理解单样本符号检验的应用:
实例:检验土壤重金属中位浓度是否超标
假设我们研究某工业区附近的土壤重金属污染情况。环境标准规定铅的中位浓度不应超过50 mg/kg。我们在该区域采集了12个土壤样品,测量铅浓度。
- 零假设(\(H_0\)):土壤铅的中位浓度等于50 mg/kg(\(M = 50\))
- 备择假设(\(H_1\)):土壤铅的中位浓度大于50 mg/kg(\(M > 50\))
这是一个单侧检验,因为我们只关心浓度是否超标。如果检验结果显示p < 0.05,我们有统计证据表明土壤铅污染确实超过了环境标准。
符号检验的主要优点是它对分布形态没有要求,对极端值不敏感。然而,它的缺点是统计功效通常低于对应的参数检验,因为它忽略了差异的大小信息。
为了更好地理解单样本符号检验的原理,让我们通过一个图来理解:
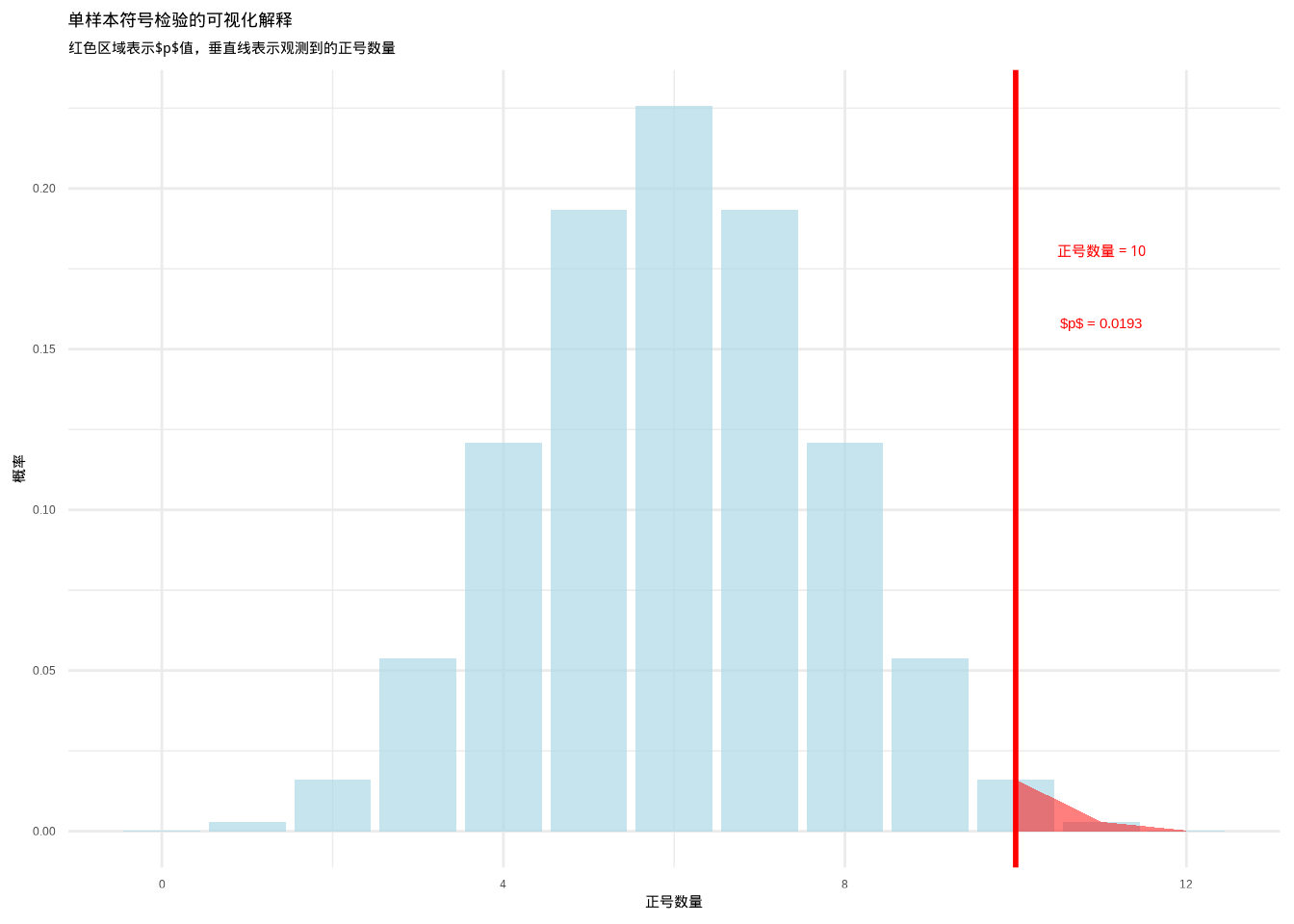
图6.7: 单样本符号检验的可视化解释:展示二项分布下正号数量的概率分布以及观测到的正号数量。红色区域表示p值区域,通过颜色和填充纹理的组合增强可辨识度。
这个图表直观展示了单样本符号检验的原理。蓝色柱状图表示在零假设下(正号和负号以相等概率出现)正号数量的二项分布,红色垂直线表示我们观测到的正号数量,红色区域表示\(p\)值——在零假设下观测到当前或更多正号的概率。
在实际的生态学研究中,选择使用单样本\(t\)检验还是符号检验应该基于数据的特性和研究问题的性质。如果数据近似正态分布且没有极端值,\(t\)检验通常更有效。如果数据严重偏离正态分布或存在极端值,符号检验提供了更稳健的替代方法。
单样本检验为我们提供了评估生态指标是否达到特定基准的工具。然而,在生态保护研究中,我们更常遇到的是比较不同处理或不同时间点的生态效应。例如,评估保护措施实施前后的种群变化,或者比较不同管理策略的效果。这就需要我们掌握更复杂的双样本检验方法。
6.4 保护前后对比:双样本检验
生态保护措施的效果评估常常需要比较不同时间点或不同处理条件下的生态指标变化。例如,评估梅花鹿保护措施实施前后的种群变化、比较施肥处理与对照处理的草地生产力差异、或者分析污染区域与清洁区域的生物多样性对比。双样本检验方法为这类生态对比研究提供了可靠的统计基础。
6.4.1 独立样本\(t\)检验
在生态学研究中,我们常常需要比较两个独立样本的均值是否存在显著差异。独立样本\(t\)检验就是用于这种目的的参数检验方法,特别适用于比较来自不同处理、不同生境或不同群体的生态数据。
独立样本\(t\)检验的基本思想是比较两个独立样本的均值差异是否具有统计显著性。其零假设和备择假设通常设定为:
- 零假设(\(H_0\)):两个样本的总体均值相等(\(\mu_1 = \mu_2\))
- 备择假设(\(H_1\)):两个样本的总体均值不相等(\(\mu_1 \neq \mu_2\)),或者根据研究问题设定为单侧检验
检验统计量\(t\)的计算公式为:
\[t = \frac{\bar{x}_1 - \bar{x}_2}{s_p \sqrt{\frac{1}{n_1} + \frac{1}{n_2}}}\]
其中\(\bar{x}_1\)和\(\bar{x}_2\)分别是两个样本的均值,\(n_1\)和\(n_2\)是样本量,\(s_p\)是合并标准差,计算公式为:
\[s_p = \sqrt{\frac{(n_1 - 1)s_1^2 + (n_2 - 1)s_2^2}{n_1 + n_2 - 2}}\]
这个统计量服从自由度为\(n_1 + n_2 - 2\)的\(t\)分布。
为什么使用合并标准差?
使用合并标准差\(s_p\)而不是单独使用\(s_1\)或\(s_2\)是基于一个重要的假设:两个样本来自具有相同方差的总体。这个假设称为方差齐性。在方差齐性的前提下,合并标准差提供了对共同总体方差的更好估计,因为它结合了两个样本的信息。
如果方差齐性假设不成立,我们需要使用Welch’s \(t\)检验,它不假设两个样本具有相同的方差,其自由度的计算也更加复杂。
生态学意义:独立样本\(t\)检验在生态学中有广泛的应用。例如,我们可以检验:
- 施肥处理和对照处理的草地生产力是否存在显著差异
- 不同森林类型中的鸟类多样性是否存在显著差异
- 污染区域和清洁区域的土壤微生物丰度是否存在显著差异
- 保护区内外的物种丰富度是否存在显著差异
- 实施不同保护措施区域的梅花鹿种群密度是否存在显著差异
让我们通过一个具体的生态学实例来理解独立样本\(t\)检验的应用:
实例:比较不同保护措施对梅花鹿种群的影响
假设我们研究两种不同保护措施(禁猎保护 vs 栖息地恢复)对梅花鹿种群的影响。我们随机选择20个区域,其中10个实施禁猎保护,10个实施栖息地恢复。经过一年保护,我们测量每个区域的梅花鹿密度。
- 零假设(\(H_0\)):两种保护措施的平均梅花鹿密度没有差异
- 备择假设(\(H_1\)):两种保护措施的平均梅花鹿密度存在差异
如果检验结果显示p < 0.05,我们有统计证据表明两种保护措施对梅花鹿种群产生了不同的影响。
独立样本\(t\)检验的使用需要满足一些前提条件:数据应该近似正态分布,两个样本的方差应该相等(方差齐性),观测值之间相互独立。如果这些条件不满足,我们可能需要考虑使用非参数检验方法。
为了更好地理解独立样本\(t\)检验的原理,让我们通过一个图来理解:
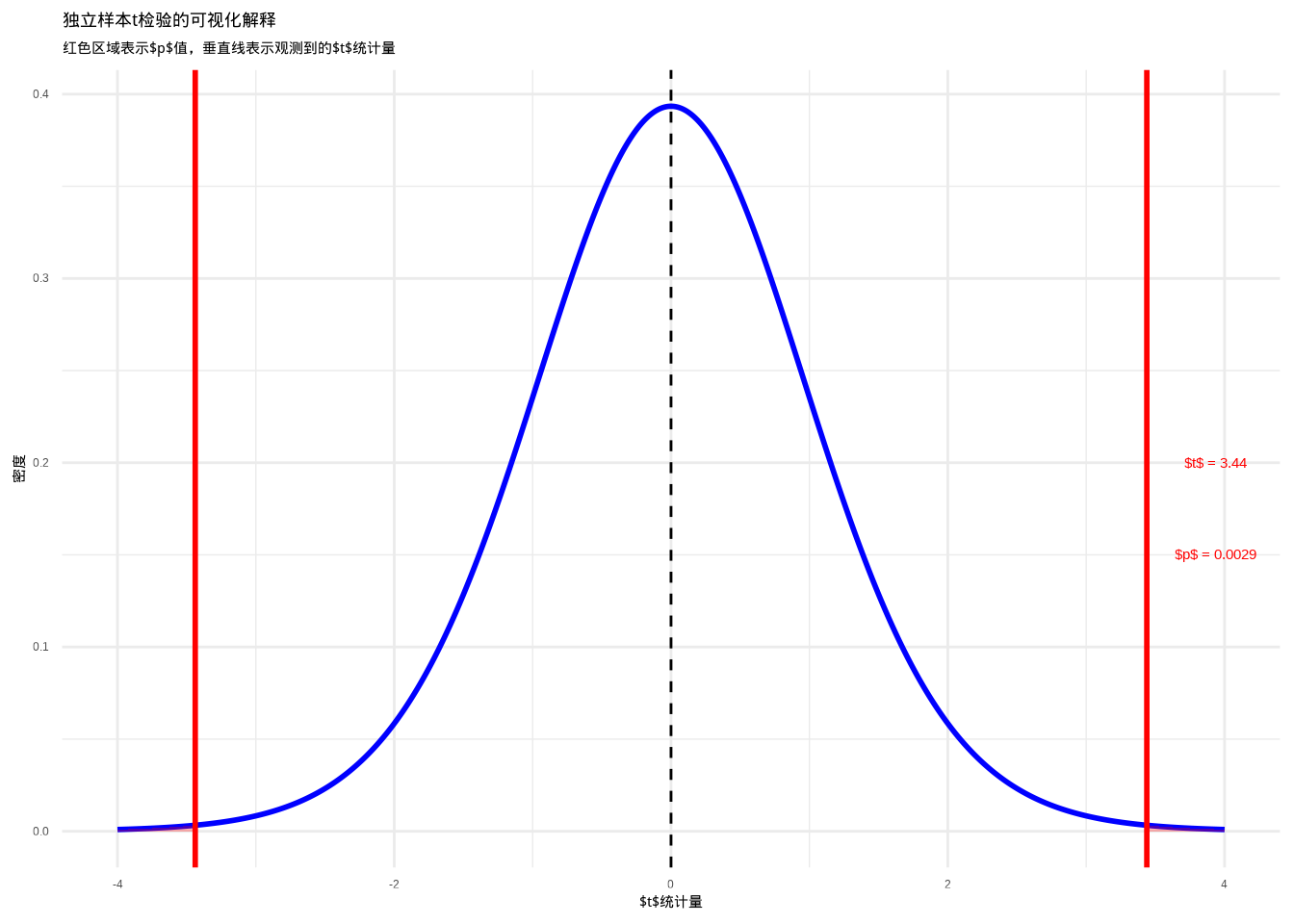
图6.8: 独立样本t检验的可视化解释:展示在零假设下t分布、观测t统计量以及对应的p值区域。红色区域表示p值区域,通过颜色和填充纹理的组合增强可辨识度。
这个图表直观展示了独立样本\(t\)检验的原理。蓝色曲线表示在零假设下的\(t\)分布,红色垂直线表示我们观测到的\(t\)统计量,红色区域表示\(p\)值——在零假设下观测到当前或更极端\(t\)值的概率。
6.4.2 配对样本\(t\)检验
在生态学研究中,我们常常需要比较同一研究对象在不同时间点或不同条件下的测量值。配对样本\(t\)检验就是专门用于这种配对设计数据的参数检验方法。
配对样本\(t\)检验的基本思想不是直接比较两个样本的均值,而是比较配对差异的均值是否显著不同于零。其零假设和备择假设通常设定为:
- 零假设(\(H_0\)):配对差异的总体均值等于零(\(\mu_d = 0\))
- 备择假设(\(H_1\)):配对差异的总体均值不等于零(\(\mu_d \neq 0\)),或者根据研究问题设定为单侧检验
检验统计量\(t\)的计算公式为:
\[t = \frac{\bar{d}}{s_d / \sqrt{n}}\]
其中\(\bar{d}\)是配对差异的均值,\(s_d\)是配对差异的标准差,\(n\)是配对数。这个统计量服从自由度为\(n-1\)的\(t\)分布。
为什么配对样本\(t\)检验通常更有效?
配对样本\(t\)检验通过考虑个体间的变异,通常比独立样本\(t\)检验具有更高的统计功效。这是因为配对设计消除了个体间变异对检验的影响,使得我们能够更精确地检测处理效应。
生态学意义:配对样本\(t\)检验在生态学中特别适用于以下情况:
- 同一地块在不同年份的物种丰富度比较
- 同一动物个体在不同季节的体重变化
- 同一植物在不同处理前后的生理指标测量
- 同一水域在不同污染事件前后的水质参数
- 同一区域在保护措施实施前后的梅花鹿种群密度比较
让我们通过一个具体的生态学实例来理解配对样本\(t\)检验的应用:
实例:检验保护措施对梅花鹿种群的影响
假设我们研究梅花鹿保护措施对种群密度的影响。我们在10个保护区实施保护措施前和实施一年后分别调查梅花鹿数量。
- 零假设(\(H_0\)):保护措施实施前后的梅花鹿密度没有差异(\(\mu_d = 0\))
- 备择假设(\(H_1\)):保护措施实施后的梅花鹿密度高于实施前(\(\mu_d > 0\))
这是一个单侧检验,因为我们预期保护措施会提高梅花鹿密度。如果检验结果显示p < 0.05,我们有统计证据表明保护措施确实产生了积极效果。
配对样本\(t\)检验的使用需要满足一些前提条件:配对差异应该近似正态分布。如果这个条件不满足,我们可能需要考虑使用非参数检验方法,如Wilcoxon符号秩检验。
为了更好地理解配对样本\(t\)检验的原理,让我们通过一个图理解:
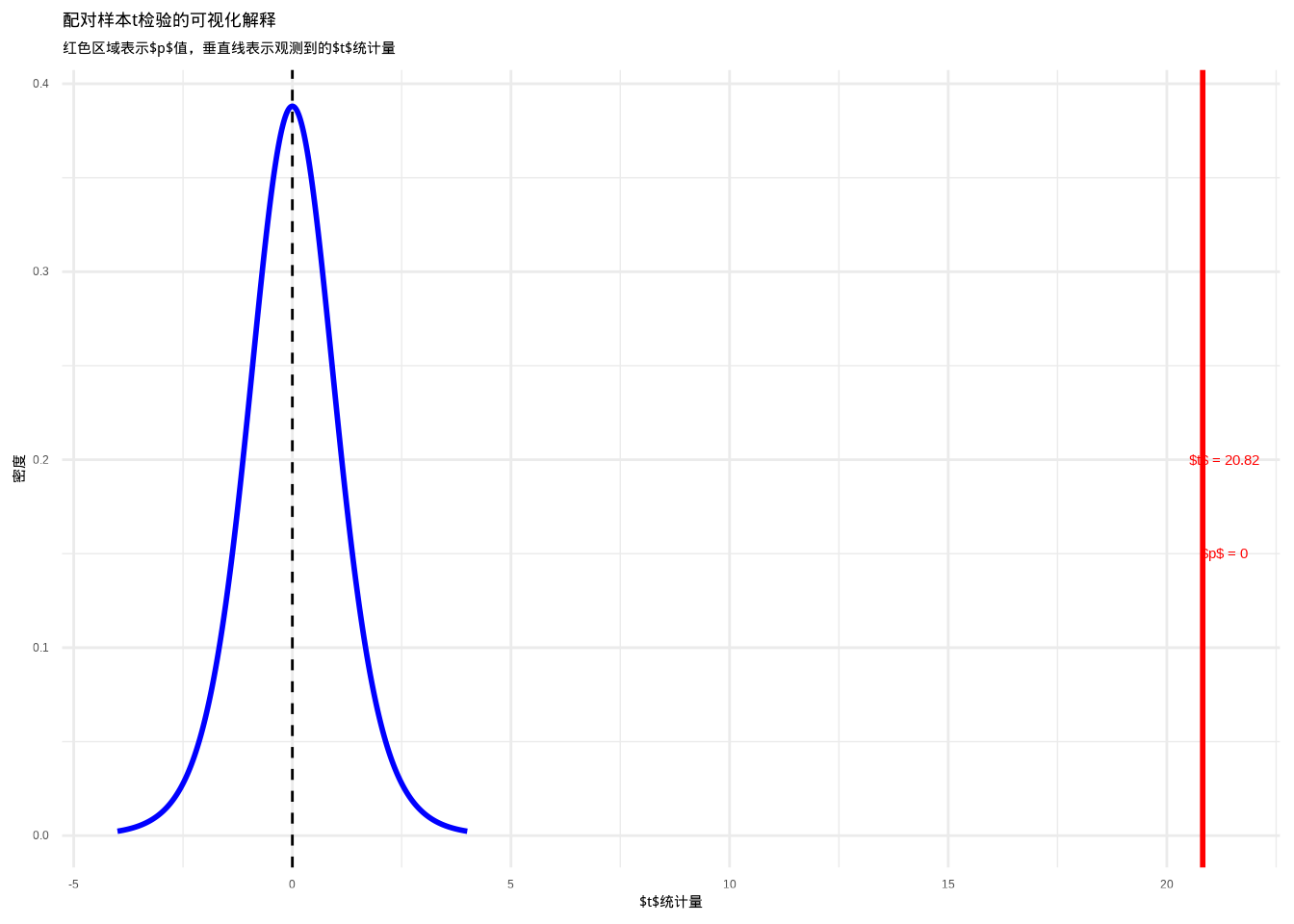
图6.9: 配对样本t检验的可视化解释:展示配对差异均值的t分布、观测t统计量以及对应的p值区域。红色区域表示p值区域,通过颜色和填充纹理的组合增强可辨识度。
这个图表直观展示了配对样本\(t\)检验的原理。蓝色曲线表示在零假设下的\(t\)分布(差异为0),红色垂直线表示我们观测到的\(t\)统计量,红色区域表示\(p\)值——在零假设下观测到当前或更极端\(t\)值的概率。
6.4.3 Mann-Whitney U检验
当数据不满足正态分布假设,或者我们想要比较两个独立样本的中位数而不是均值时,Mann-Whitney U检验提供了一个强大的非参数替代方法。这个检验也被称为Wilcoxon秩和检验。
Mann-Whitney U检验的基本思想是将两个样本的所有观测值合并排序,然后基于秩次来检验两个样本是否来自相同的分布。其零假设和备择假设通常设定为:
- 零假设(\(H_0\)):两个样本来自相同的分布
- 备择假设(\(H_1\)):两个样本来自不同的分布,或者一个样本倾向于产生更大的值
检验统计量\(U\)的计算基于秩次:
\[U = n_1 n_2 + \frac{n_1(n_1 + 1)}{2} - R_1\]
其中\(n_1\)和\(n_2\)是两个样本的样本量,\(R_1\)是第一个样本的秩和。
为什么使用秩次而不是原始值?
使用秩次而不是原始值使得检验对极端值不敏感,也不依赖于数据的分布形态。这使得Mann-Whitney U检验特别适用于偏态分布、存在极端值或测量尺度是序数的情况。
生态学意义:Mann-Whitney U检验在生态学中特别适用于以下情况:
- 数据严重偏离正态分布
- 样本量很小,无法可靠地检验正态性
- 存在极端值或异常值
- 测量尺度是序数的,或者数据只包含相对大小信息
例如,我们可以使用Mann-Whitney U检验来:
- 比较不同污染程度区域的生物指标中位数
- 检验不同管理措施对物种丰富度的影响
- 比较不同生境类型中的个体大小分布
让我们通过一个具体的生态学实例来理解Mann-Whitney U检验的应用:
实例:比较不同污染区域的生物指标
假设我们研究工业污染对河流底栖动物群落的影响。我们在污染区域和清洁区域各采集了8个样品,测量底栖动物的生物量。由于数据存在极端值且分布偏态,我们选择使用Mann-Whitney U检验。
- 零假设(\(H_0\)):污染区域和清洁区域的底栖动物生物量来自相同的分布
- 备择假设(\(H_1\)):污染区域的底栖动物生物量倾向于低于清洁区域
这是一个单侧检验,因为我们预期污染会降低生物量。如果检验结果显示p < 0.05,我们有统计证据表明污染确实对底栖动物群落产生了负面影响。
Mann-Whitney U检验的主要优点是它对分布形态没有要求,对极端值不敏感。然而,它的缺点是统计功效通常低于对应的参数检验(\(t\)检验),因为它忽略了数据的数值信息,只使用秩次信息。
为了更好地理解Mann-Whitney U检验的原理,让我们通过一个图来理解:
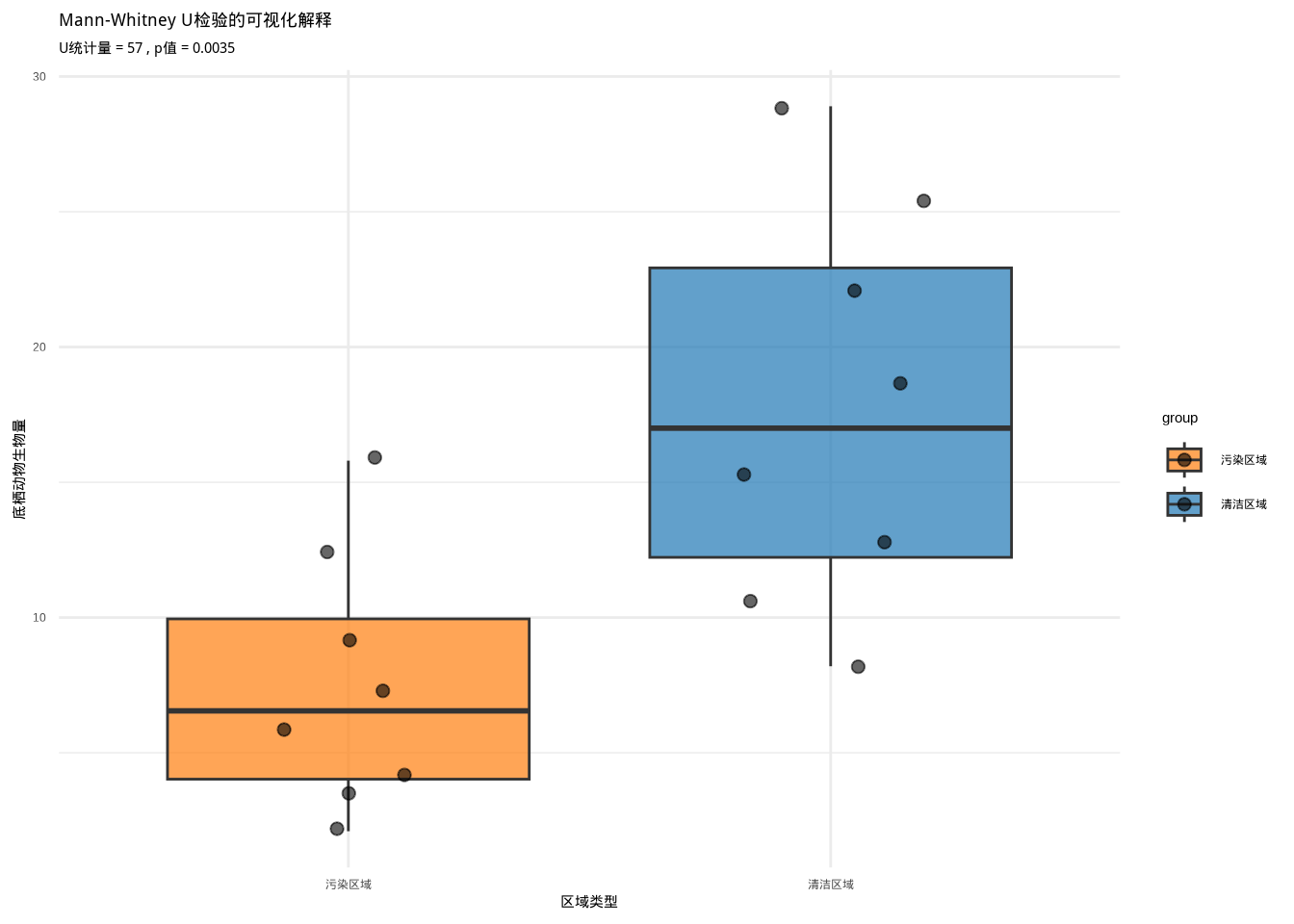
图6.10: Mann-Whitney U检验的可视化解释:通过箱线图展示污染区域(橙色)和清洁区域(蓝色)底栖动物生物量的分布比较。通过颜色和填充纹理的组合区分不同区域类型。
这个图表直观展示了Mann-Whitney U检验的原理。箱线图显示了两个样本的分布情况,点表示各个观测值。检验基于这些观测值的秩次(排序位置)而不是原始数值来进行统计推断。
在实际的生态学研究中,选择使用独立样本\(t\)检验、配对样本\(t\)检验还是Mann-Whitney U检验应该基于数据的特性、研究设计和研究问题的性质。如果数据满足正态分布和方差齐性假设,\(t\)检验通常更有效。如果数据严重偏离正态分布或存在极端值,Mann-Whitney U检验提供了更稳健的替代方法。配对样本\(t\)检验则专门用于配对设计的数据,通常具有更高的统计功效。
双样本检验为我们提供了比较两个处理或两个时间点生态效应的工具。然而,在实际的生态保护和管理中,我们常常需要同时评估多种保护措施或多种管理策略的效果。例如,比较禁猎保护、栖息地恢复和人工投食三种不同保护措施对梅花鹿种群的影响。这就需要我们掌握更复杂的多样本检验方法。
6.5 不同保护区的比较:多样本检验
在生态管理实践中,我们常常需要同时比较多个处理、多个生境或多个保护区的生态效应。例如,评估不同森林类型对鸟类多样性的影响、比较多种施肥水平对作物产量的效果、或者分析不同污染程度水域的水生生物群落差异。多样本检验方法为这类复杂的生态比较提供了系统的统计框架。
6.5.1 方差分析(ANOVA)
在生态学研究中,我们常常需要比较三个或更多组别的均值是否存在显著差异。方差分析(ANOVA)就是用于这种目的的参数检验方法,它通过分析组间变异与组内变异的比值来检验多个总体均值是否相等。
方差分析的基本思想是将总变异分解为组间变异和组内变异,然后比较这两种变异的相对大小。其零假设和备择假设通常设定为:
- 零假设(\(H_0\)):所有组的总体均值相等(\(\mu_1 = \mu_2 = \cdots = \mu_k\))
- 备择假设(\(H_1\)):至少有一对组的总体均值与其他组的总体均值不相等
检验统计量\(F\)的计算基于方差分解:
\[F = \frac{MS_{between}}{MS_{within}} = \frac{SS_{between} / df_{between}}{SS_{within} / df_{within}}\]
其中:
- \(SS_{between}\)是组间平方和,\(MS_{between}\)是组间均方,衡量组间变异
- \(SS_{within}\)是组内平方和,\(MS_{within}\)是组内均方,衡量组内变异
- \(df_{between} = k - 1\)是组间自由度
- \(df_{within} = N - k\)是组内自由度
- \(k\)是组数,\(N\)是总样本量
这个统计量服从自由度为\((k-1, N-k)\)的\(F\)分布。
为什么使用F统计量而不是多个\(t\)检验?
使用多个\(t\)检验来比较所有组对会导致第一类错误率膨胀,这是一个在生态统计学中非常重要的概念。让我们通过数学计算和可视化来深入理解这个问题。
第一类错误率膨胀的数学原理
假设我们有\(k\)个组,需要进行\(m\)次两两比较,其中:
\[m = \frac{k(k-1)}{2}\]
如果每次\(t\)检验的显著性水平设为\(\alpha = 0.05\),那么:
- 单次检验的第一类错误概率:\(\alpha = 0.05\)
- 单次检验的正确决策概率:\(1 - \alpha = 0.95\)
- 所有\(m\)次检验都正确决策的概率:\((1 - \alpha)^m\)
- 至少犯一次第一类错误的概率:\(1 - (1 - \alpha)^m\)
让我们计算不同组数下的累积第一类错误率:
| 组数 (\(k\)) | 比较次数 (\(m\)) | 累积第一类错误率 |
|---|---|---|
| 2 | 1 | 5.0% |
| 3 | 3 | 14.3% |
| 4 | 6 | 26.5% |
| 5 | 10 | 40.1% |
| 6 | 15 | 53.7% |
| 7 | 21 | 65.9% |
| 8 | 28 | 76.2% |
从表中可以看出,当组数增加到5个时,累积第一类错误率已经达到40.1%,这意味着即使所有组实际上没有差异,我们也有40.1%的概率至少得到一个”显著”的假阳性结果。
方差分析的解决方案
方差分析通过一次检验同时比较所有组,将第一类错误率控制在预设的\(\alpha\)水平(通常是5%)。其零假设是:
\[H_0: \mu_1 = \mu_2 = \cdots = \mu_k\]
备择假设是:
\[H_1: \text{至少有一对组的均值不相等}\]
通过F检验,我们可以在保持第一类错误率不变的情况下,检验所有组间是否存在显著差异。
生态学意义
在生态学研究中,我们经常需要比较多个处理、多个生境或多个物种群体。如果使用多个\(t\)检验:
- 我们可能会错误地宣称某些处理有效果,而实际上这些差异只是随机波动
- 研究结论的可靠性会大大降低
- 后续的保护决策或管理措施可能基于错误的发现
让我们通过一个图来直观理解这个问题:
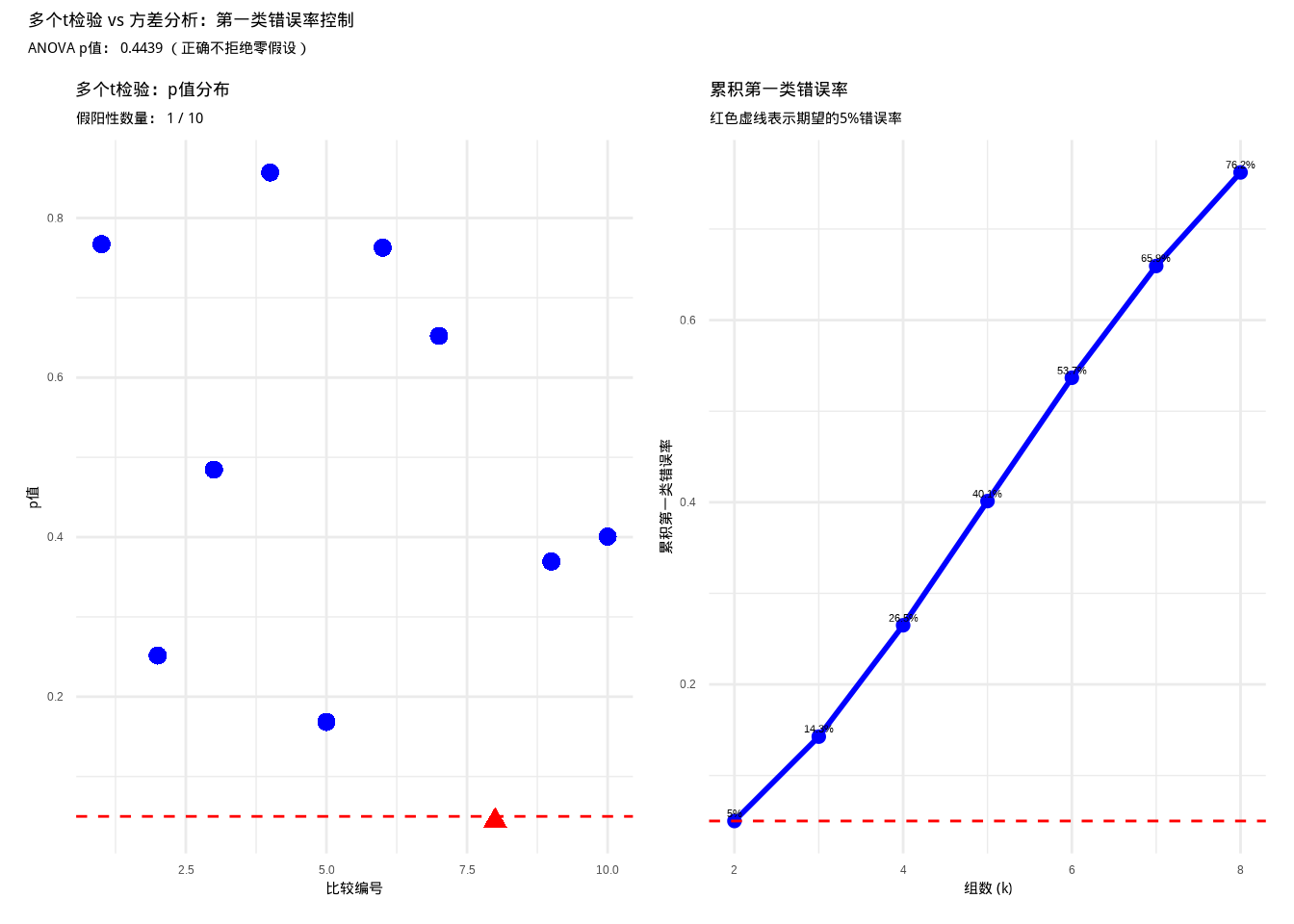
图6.11: 多个t检验与方差分析的比较:展示多重比较导致的第一类错误率膨胀问题以及方差分析的解决方案
图表解释
- 左图:多个\(t\)检验的p值分布
- 每个点代表一次两两比较的p值
- 红色点表示”显著”结果(p < 0.05)
- 即使所有组实际上来自相同的分布(零假设为真),由于进行了多次检验,我们仍然可能得到一些”显著”的假阳性结果
- 右图:累积第一类错误率
- 随着组数增加,需要进行的两两比较次数急剧增加
- 累积第一类错误率迅速上升,远超过期望的5%水平
- 当组数达到8个时,累积第一类错误率高达76.2%
实际生态学应用建议
在生态学研究中,我们应该:
首选方差分析:当比较三个或更多组时,使用方差分析而不是多个\(t\)检验
如果方差分析显著,再进行事后检验:
- 使用Tukey HSD检验进行所有两两比较
- 使用Bonferroni校正调整p值
- 使用Scheffé方法进行复杂的对比
报告完整的分析流程:
- 先报告方差分析的总体结果
- 如果显著,再报告具体哪些组间存在差异
- 说明使用的多重比较校正方法
考虑研究设计:
- 在实验设计阶段就考虑使用方差分析
- 确保样本量足够检测预期的效应大小
- 考虑使用重复测量方差分析处理时间序列数据
通过使用方差分析而不是多个\(t\)检验,我们能够在保持统计严谨性的同时,得出更可靠的生态学结论,为生态保护和管理决策提供更坚实的科学依据。
单因素方差分析与多因素方差分析
- 单因素方差分析:只有一个分类自变量,用于比较不同处理、不同生境或不同群体的效应
- 多因素方差分析:有多个分类自变量,可以同时检验主效应和交互效应
生态学意义:方差分析在生态学中有广泛的应用。例如,我们可以检验:
- 不同施肥水平对作物产量的影响
- 不同森林类型中的鸟类多样性差异
- 不同污染程度水域的水生生物群落差异
- 不同管理措施对草地生产力的影响
- 不同保护措施(禁猎、栖息地恢复、人工投食)对梅花鹿种群密度的影响
让我们通过一个具体的生态学实例来理解方差分析的应用:
实例:比较不同保护措施对梅花鹿种群的影响
假设我们研究三种不同保护措施(禁猎保护、栖息地恢复、人工投食)对梅花鹿种群的影响。我们在每种保护措施区域随机选择10个样点,调查梅花鹿密度。
- 零假设(\(H_0\)):三种保护措施的平均梅花鹿密度相等
- 备择假设(\(H_1\)):至少有一种保护措施的平均梅花鹿密度与其他不同
如果方差分析结果显示p < 0.05,我们有统计证据表明不同保护措施对梅花鹿种群产生了显著影响。
方差分析的使用需要满足一些前提条件:数据应该近似正态分布,各组方差应该相等(方差齐性),观测值之间相互独立。如果这些条件不满足,我们可能需要考虑使用非参数检验方法。
为了更好地理解方差分析的原理,让我们通过一个图来理解:
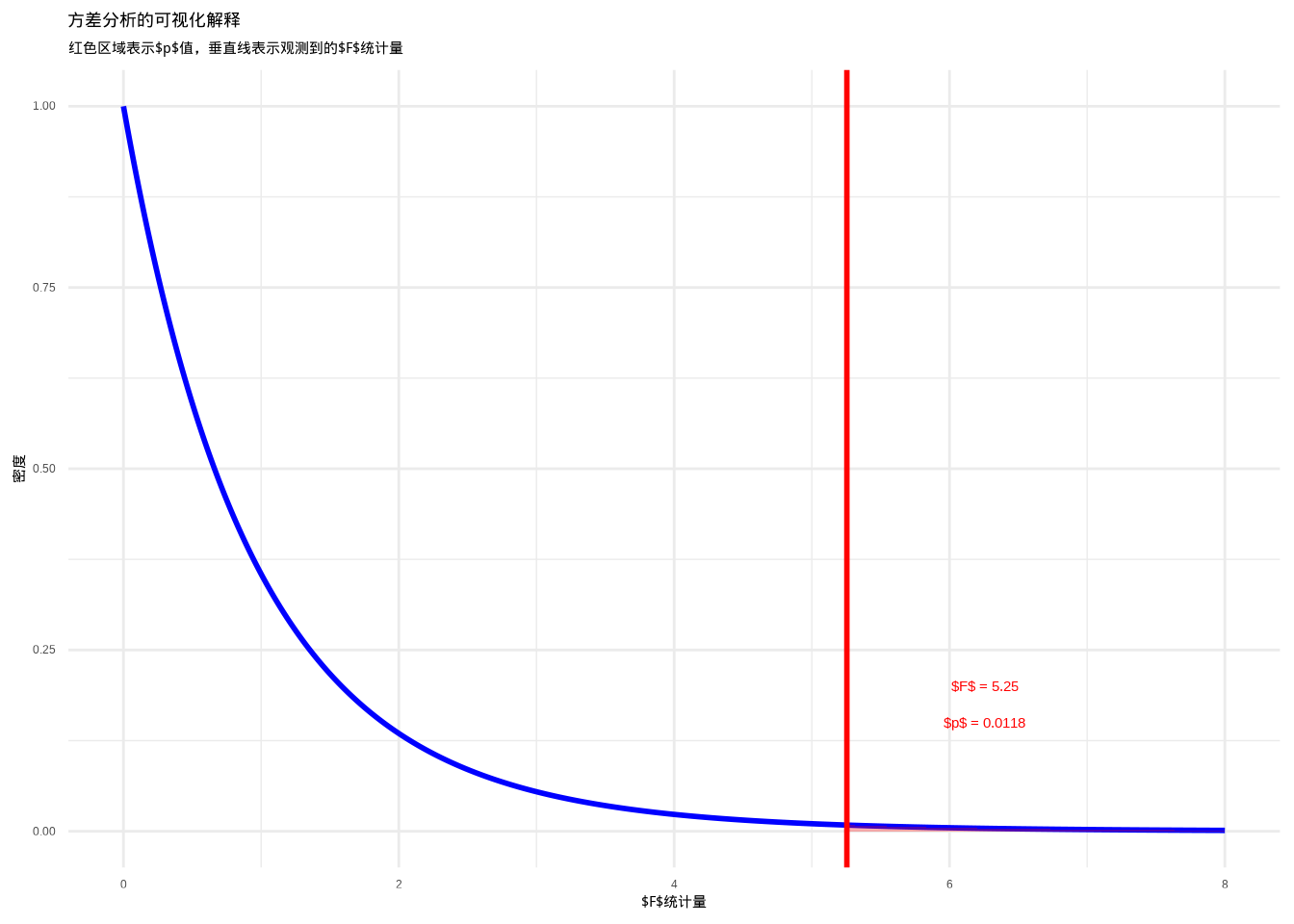
图6.12: 方差分析的可视化解释:展示F分布、观测F统计量以及对应的p值区域
这个图表直观展示了方差分析的原理。蓝色曲线表示在零假设下的\(F\)分布,红色垂直线表示我们观测到的\(F\)统计量,红色区域表示\(p\)值——在零假设下观测到当前或更极端\(F\)值的概率。
6.5.2 Kruskal-Wallis检验
当数据不满足正态分布假设,或者我们想要比较多个独立样本的中位数而不是均值时,Kruskal-Wallis检验提供了一个强大的非参数替代方法。这个检验是Mann-Whitney U检验在多个样本情况下的扩展。
Kruskal-Wallis检验的基本思想是将所有样本的观测值合并排序,然后基于秩次来检验多个样本是否来自相同的分布。其零假设和备择假设通常设定为:
- 零假设(\(H_0\)):所有样本来自相同的分布
- 备择假设(\(H_1\)):至少有一个样本来自不同的分布
检验统计量\(H\)的计算基于秩次:
\[H = \frac{12}{N(N+1)} \sum_{i=1}^k \frac{R_i^2}{n_i} - 3(N+1)\]
其中:
- \(k\)是组数
- \(n_i\)是第\(i\)组的样本量
- \(R_i\)是第\(i\)组的秩和
- \(N\)是总样本量
在大样本情况下,\(H\)统计量近似服从自由度为\(k-1\)的卡方分布。
为什么使用秩次而不是原始值?
使用秩次而不是原始值使得检验对极端值不敏感,也不依赖于数据的分布形态。这使得Kruskal-Wallis检验特别适用于偏态分布、存在极端值或测量尺度是序数的情况。
生态学意义:Kruskal-Wallis检验在生态学中特别适用于以下情况:
- 数据严重偏离正态分布
- 样本量很小,无法可靠地检验正态性
- 存在极端值或异常值
- 测量尺度是序数的,或者数据只包含相对大小信息
例如,我们可以使用Kruskal-Wallis检验来:
- 比较不同污染程度区域的多个生物指标
- 检验不同管理措施对多个物种丰富度的影响
- 比较不同生境类型中的多个个体大小分布
- 比较不同保护措施对梅花鹿种群密度的影响(当数据不满足正态分布时)
让我们通过一个具体的生态学实例来理解Kruskal-Wallis检验的应用:
实例:比较不同保护措施对梅花鹿种群的影响(非参数方法)
假设我们研究三种不同保护措施(禁猎保护、栖息地恢复、人工投食)对梅花鹿种群的影响。我们在每种保护措施区域各采集了8个样点,测量梅花鹿密度。由于数据存在极端值且分布偏态,我们选择使用Kruskal-Wallis检验。
- 零假设(\(H_0\)):三种保护措施区域的梅花鹿密度来自相同的分布
- 备择假设(\(H_1\)):至少有一种保护措施区域的梅花鹿密度分布与其他不同
如果检验结果显示p < 0.05,我们有统计证据表明不同保护措施确实对梅花鹿种群产生了显著影响。
Kruskal-Wallis检验的主要优点是它对分布形态没有要求,对极端值不敏感。然而,它的缺点是统计功效通常低于对应的参数检验(方差分析),因为它忽略了数据的数值信息,只使用秩次信息。
为了更好地理解Kruskal-Wallis检验的原理,让我们通过一个图来理解:
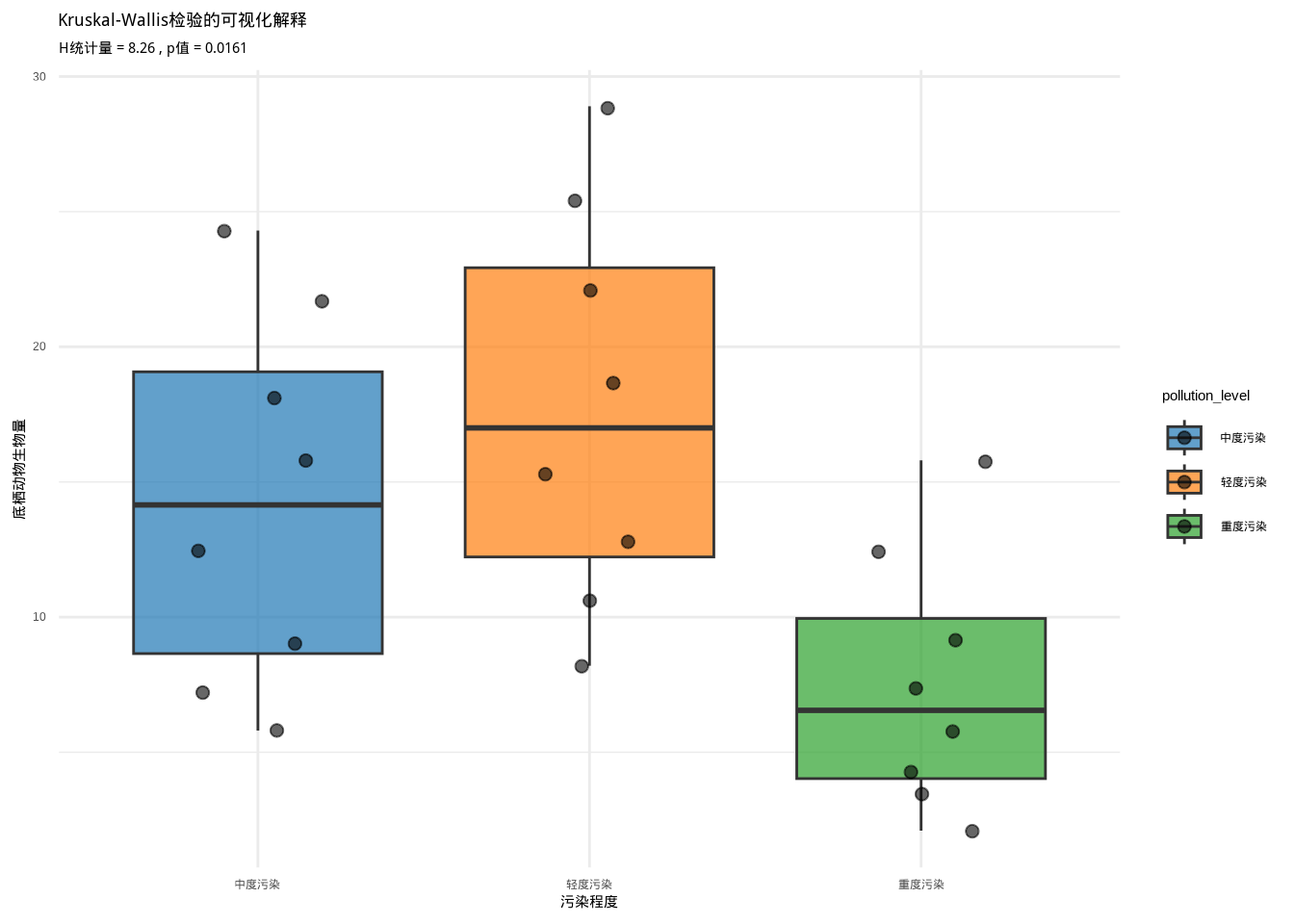
图6.13: Kruskal-Wallis检验的可视化解释:通过箱线图展示不同污染程度区域底栖动物生物量的分布比较
这个图表直观展示了Kruskal-Wallis检验的原理。箱线图显示了三个样本的分布情况,点表示各个观测值。检验基于这些观测值的秩次(排序位置)而不是原始数值来进行统计推断。
在实际的生态学研究中,选择使用方差分析还是Kruskal-Wallis检验应该基于数据的特性、研究设计和研究问题的性质。如果数据满足正态分布和方差齐性假设,方差分析通常更有效。如果数据严重偏离正态分布或存在极端值,Kruskal-Wallis检验提供了更稳健的替代方法。
多样本检验方法为我们提供了比较多个处理或生境生态效应的工具。然而,生态数据常常呈现出复杂的分布特征,如偏态分布、极端值、序数尺度等,这些情况使得传统的参数检验方法不再适用。为了应对这些复杂情况,我们需要掌握非参数检验方法,它们不依赖于严格的正态分布假设,为处理复杂生态数据提供了稳健的统计工具。
6.6 生态复杂数据的非参数检验
生态数据常常呈现出复杂的分布特征,如偏态分布、极端值、序数尺度等,这些情况使得传统的参数检验方法不再适用。例如,梅花鹿种群的空间分布可能呈现明显的聚集模式,或者污染物浓度数据可能存在检测限问题。非参数检验方法为处理这类复杂生态数据提供了稳健的统计工具,它们不依赖于严格的正态分布假设,而是基于数据的排序或符号信息进行统计推断。
符号检验:
- 基于符号的非参数检验
- 生态学意义:适用于序数数据
Wilcoxon符号秩检验:
- 考虑排序的非参数检验
- 生态学意义:比符号检验更有效
卡方检验:
- 检验分类变量的关联性
- 拟合优度检验:检验观测分布与理论分布的拟合
- 独立性检验:检验两个分类变量的独立性
- 生态学意义:分析物种分布、生境偏好等
方法学发展脉络说明:本章介绍的非参数检验方法虽然不依赖于严格的正态分布假设,但它们仍然是基于经典统计理论的传统方法。这些方法为生态学家提供了处理非正态数据的重要工具。然而,随着生态学研究的深入和复杂化,我们越来越多地遇到这样的情况:我们感兴趣的统计量根本没有现成的理论分布可以参照,或者数据的复杂性超出了传统方法的处理能力。在这种情况下,我们需要转向更灵活的现代统计方法——基于模拟的假设检验。这些方法将在下一章中详细介绍,它们通过计算机模拟来构建统计量的经验分布,为处理复杂的生态学问题提供了全新的解决方案。从经典的非参数检验到现代的基于模拟方法,体现了统计方法学从理论驱动到数据驱动的演进,为生态学家应对日益复杂的生态问题提供了更强大的工具包。
在掌握了各种假设检验方法后,我们需要关注一个在生态学研究中经常被忽视但极为重要的问题——多重比较校正。当我们同时进行多个统计检验时,如果不进行适当的校正,会导致假阳性发现的风险显著增加。这种统计陷阱可能使我们将随机波动误认为真实的生态效应,从而做出错误的保护决策。
6.7 生态多重比较的校正方法
在生态保护决策中,我们常常需要同时比较多个处理、多个生境或多个时间点的生态效应。例如,比较不同保护措施对梅花鹿种群的影响、分析多个污染区域的环境质量差异、或者评估不同管理策略的生态效果。然而,这种多重比较会显著增加假阳性发现的风险,可能导致错误的保护决策。多重比较校正方法为我们提供了控制这种统计陷阱的严谨工具。
6.7.1 多重比较问题的本质
在生态学研究中,当我们使用方差分析发现多个组间存在总体差异后,一个自然的问题随之而来:具体哪些组之间存在差异? 要回答这个问题,我们需要进行两两比较。然而,直接进行多个\(t\)检验会导致第一类错误率膨胀,这是一个在生态统计学中必须重视的问题。
为什么需要多重比较校正?
假设我们有\(k\)个组,需要进行\(m\)次两两比较,其中:
\[m = \frac{k(k-1)}{2}\]
如果每次检验的显著性水平设为\(\alpha = 0.05\),那么累积的第一类错误率为:
\[\alpha_{family} = 1 - (1 - \alpha)^m\]
这意味着即使所有组实际上没有差异,我们也有很高的概率至少得到一个”显著”的假阳性结果。多重比较校正的目的就是控制这个族错误率,确保我们的统计结论更加可靠。
生态学意义:在生态保护和管理决策中,错误的统计结论可能导致资源浪费或错失保护机会。多重比较校正帮助我们避免将随机波动误认为真实的生态效应,为科学决策提供更可靠的依据。
让我们通过文字描述来理解完整的分析流程:
多重比较分析遵循一个清晰的逻辑流程,确保统计结论的可靠性。首先,我们执行方差分析(ANOVA)来检验多个组间的总体差异。如果方差分析结果显示总体差异不显著,我们停止分析,因为这意味着各组之间没有系统性的差异,继续进行多重比较只会增加第一类错误的风险。
只有当方差分析显示总体差异显著时,我们才进入多重比较校正阶段。在这一步,我们需要根据研究目的选择适当的校正方法。常用的方法包括Tukey HSD(适用于所有组对比较)、Bonferroni校正(适用于预先指定的比较)和FDR控制(适用于探索性分析)。选择合适的方法后,我们进行多重比较校正,最终解释具体的组间差异,识别哪些组对存在统计上显著的差异。
这个流程强调了一个重要原则:只有在总体差异显著的前提下,才需要进行多重比较校正来识别具体的差异组对。这样的分析策略既保证了统计结论的可靠性,又避免了不必要的多重检验带来的错误率膨胀。
6.7.2 Bonferroni校正
在生态保护决策中,当我们需要严格控制假阳性风险时,Bonferroni校正提供了最保守的多重比较校正方法。例如,在评估多种保护措施对梅花鹿种群的影响时,我们需要确保不会错误地宣称无效的措施有效。
Bonferroni校正是最简单也最保守的多重比较校正方法。其基本思想是将显著性水平\(\alpha\)除以比较次数\(m\):
\[\alpha_{adjusted} = \frac{\alpha}{m}\]
其中\(\alpha\)是期望的族错误率(通常为0.05),\(m\)是比较次数。
数学原理:
Bonferroni校正基于Bonferroni不等式,该不等式指出:
\[P(\bigcup_{i=1}^m A_i) \leq \sum_{i=1}^m P(A_i)\]
其中\(A_i\)表示第\(i\)次检验犯第一类错误的事件。通过将每次检验的显著性水平设为\(\alpha/m\),我们确保族错误率不超过\(\alpha\)。
优缺点:
- 优点:简单易用,计算方便
- 缺点:过于保守,统计功效较低,特别是当比较次数很多时
适用场景:
- 检验次数较少的情况(\(m < 10\))
- 预先计划的比较(而非探索性分析)
- 需要严格控制第一类错误的研究
生态学意义:在生态风险评估或保护决策等高风险研究中,Bonferroni校正的保守性可能是有益的,因为它减少了假阳性发现的风险。
6.7.3 Tukey HSD检验
在生态学研究中,当我们发现不同森林类型对鸟类多样性存在总体差异后,需要进一步确定具体哪些森林类型之间存在显著差异。Tukey HSD(Honestly Significant Difference)检验是专门为方差分析后的事后比较设计的多重比较方法。它基于学生化极差分布,同时考虑所有可能的组对比较。
原理:
Tukey HSD检验计算每个组对均值差异的置信区间:
\[\bar{x}_i - \bar{x}_j \pm q_{\alpha,k,df} \cdot \sqrt{\frac{MS_{within}}{n}}\]
其中:
- \(q_{\alpha,k,df}\)是学生化极差分布的临界值
- \(k\)是组数
- \(df\)是组内自由度
- \(MS_{within}\)是组内均方
- \(n\)是每组样本量(假设平衡设计)
生态学应用: Tukey HSD检验是生态学中最常用的多重比较方法之一,特别适用于: - 比较不同处理对生物指标的影响 - 分析不同生境类型的生态差异 - 检验不同管理措施的效果
6.7.4 FDR(错误发现率)控制
在生态基因组学研究中,我们常常需要同时检验数千个基因的表达差异,传统的多重比较校正方法可能过于保守。FDR(False Discovery Rate)控制是一种相对较新的多重比较校正方法,特别适用于大规模检验。与传统的族错误率控制不同,FDR控制的是被拒绝的零假设中错误拒绝的比例。
Benjamini-Hochberg程序:
- 将\(m\)个检验的p值从小到大排序:\(p_{(1)} \leq p_{(2)} \leq \cdots \leq p_{(m)}\)
- 找到最大的\(i\)使得:\(p_{(i)} \leq \frac{i}{m} \cdot \alpha\)
- 拒绝所有\(p_{(1)}, p_{(2)}, \ldots, p_{(i)}\)对应的零假设
适用场景:
- 大规模检验(如基因表达分析、宏基因组学)
- 探索性研究,希望在发现力和错误控制之间取得平衡
- 生态基因组学和环境DNA研究
生态学意义:在生态基因组学研究中,我们常常需要同时检验数千个基因的表达差异。FDR控制方法允许我们识别更多真实的生物学信号,同时控制假阳性发现的比例。
6.7.5 生态学实例:不同保护措施对梅花鹿种群的影响
让我们通过一个完整的生态学实例来理解多重比较校正的实际应用。假设我们研究三种不同保护措施(禁猎保护、栖息地恢复、人工投食)对梅花鹿种群密度的影响。
研究设计:
- 在每种保护措施区域中随机选择12个样点
- 调查每个样点的梅花鹿密度(只/平方公里)
- 使用方差分析检验总体差异
- 如果显著,使用多重比较校正识别具体差异
R代码实现:
# 设置参数
set.seed(123)
# 模拟三种保护措施区域的梅花鹿种群密度数据
hunting_ban <- rnorm(12, mean = 5.2, sd = 1.2) # 禁猎保护
habitat_restoration <- rnorm(12, mean = 4.8, sd = 1.1) # 栖息地恢复
artificial_feeding <- rnorm(12, mean = 6.1, sd = 1.3) # 人工投食
# 创建数据框
protection_data <- data.frame(
density = c(hunting_ban, habitat_restoration, artificial_feeding),
protection_measure = rep(c("禁猎保护", "栖息地恢复", "人工投食"), each = 12)
)# 第一步:执行方差分析
anova_result <- aov(density ~ protection_measure, data = protection_data)
cat("=== 方差分析结果 ===\n")## === 方差分析结果 ===library(dplyr) # 加载dplyr包以使用管道操作符
knitr::kable(summary(anova_result)[[1]],
caption = "方差分析结果",
booktabs = TRUE) %>%
kableExtra::kable_styling(latex_options = c("hold_position"))| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| protection_measure | 2 | 18.84531 | 9.422654 | 7.322486 | 0.0023345 |
| Residuals | 33 | 42.46475 | 1.286811 | NA | NA |
# 提取F统计量和p值
f_stat <- summary(anova_result)[[1]]["protection_measure", "F value"]
p_value <- summary(anova_result)[[1]]["protection_measure", "Pr(>F)"]
cat("\nF统计量 =", round(f_stat, 2), ",p值 =", round(p_value, 4), "\n")##
## F统计量 = 7.32 ,p值 = 0.0023# 第二步:多重比较校正(仅在方差分析显著时执行)
# 重新执行方差分析以获取p值 - 确保使用正确的数据
anova_result <- aov(density ~ protection_measure, data = protection_data)
anova_summary <- summary(anova_result)
# 提取保护措施因子的p值
p_value <- anova_summary[[1]]["protection_measure", "Pr(>F)"]
# 检查方差分析是否显著 - 只有在总体差异显著时才进行多重比较
if (p_value < 0.05) {
cat("方差分析显著,进行多重比较校正...\n\n")
# 方法1:Tukey HSD检验 - 专门为方差分析后的事后比较设计
cat("=== Tukey HSD检验结果 ===\n")
# Tukey HSD检验提供所有组对比较的调整后p值和置信区间
tukey_result <- TukeyHSD(anova_result)
print(tukey_result)
# 方法2:Bonferroni校正 - 最保守的多重比较校正方法
cat("\n=== Bonferroni校正结果 ===\n")
# 使用pairwise.t.test函数进行所有两两比较,应用Bonferroni校正
pairwise_result <- pairwise.t.test(protection_data$density,
protection_data$protection_measure,
p.adjust.method = "bonferroni"
)
print(pairwise_result)
# 方法3:FDR控制 - 错误发现率控制方法
cat("\n=== FDR控制结果 (Benjamini-Hochberg) ===\n")
# 使用Benjamini-Hochberg程序控制错误发现率
fdr_result <- pairwise.t.test(protection_data$density,
protection_data$protection_measure,
p.adjust.method = "BH"
)
print(fdr_result)
} else {
# 如果方差分析不显著,说明没有总体差异,无需进行多重比较
cat("方差分析不显著,无需进行多重比较校正。\n")
}## 方差分析显著,进行多重比较校正...
##
## === Tukey HSD检验结果 ===
## Tukey multiple comparisons of means
## 95% family-wise confidence level
##
## Fit: aov(formula = density ~ protection_measure, data = protection_data)
##
## $protection_measure
## diff lwr upr p adj
## 栖息地恢复-人工投食 -1.7720983 -2.9084687 -0.6357279 0.0015524
## 禁猎保护-人工投食 -0.9063992 -2.0427695 0.2299712 0.1389354
## 禁猎保护-栖息地恢复 0.8656992 -0.2706712 2.0020695 0.1635626
##
##
## === Bonferroni校正结果 ===
##
## Pairwise comparisons using t tests with pooled SD
##
## data: protection_data$density and protection_data$protection_measure
##
## 人工投食 栖息地恢复
## 栖息地恢复 0.0016 -
## 禁猎保护 0.1765 0.2114
##
## P value adjustment method: bonferroni
##
## === FDR控制结果 (Benjamini-Hochberg) ===
##
## Pairwise comparisons using t tests with pooled SD
##
## data: protection_data$density and protection_data$protection_measure
##
## 人工投食 栖息地恢复
## 栖息地恢复 0.0016 -
## 禁猎保护 0.0705 0.0705
##
## P value adjustment method: BH# 加载可视化包
library(ggplot2)
library(dplyr)
# 计算均值和标准误
summary_stats <- protection_data %>%
group_by(protection_measure) %>%
summarise(
mean_density = mean(density),
se_density = sd(density) / sqrt(n())
)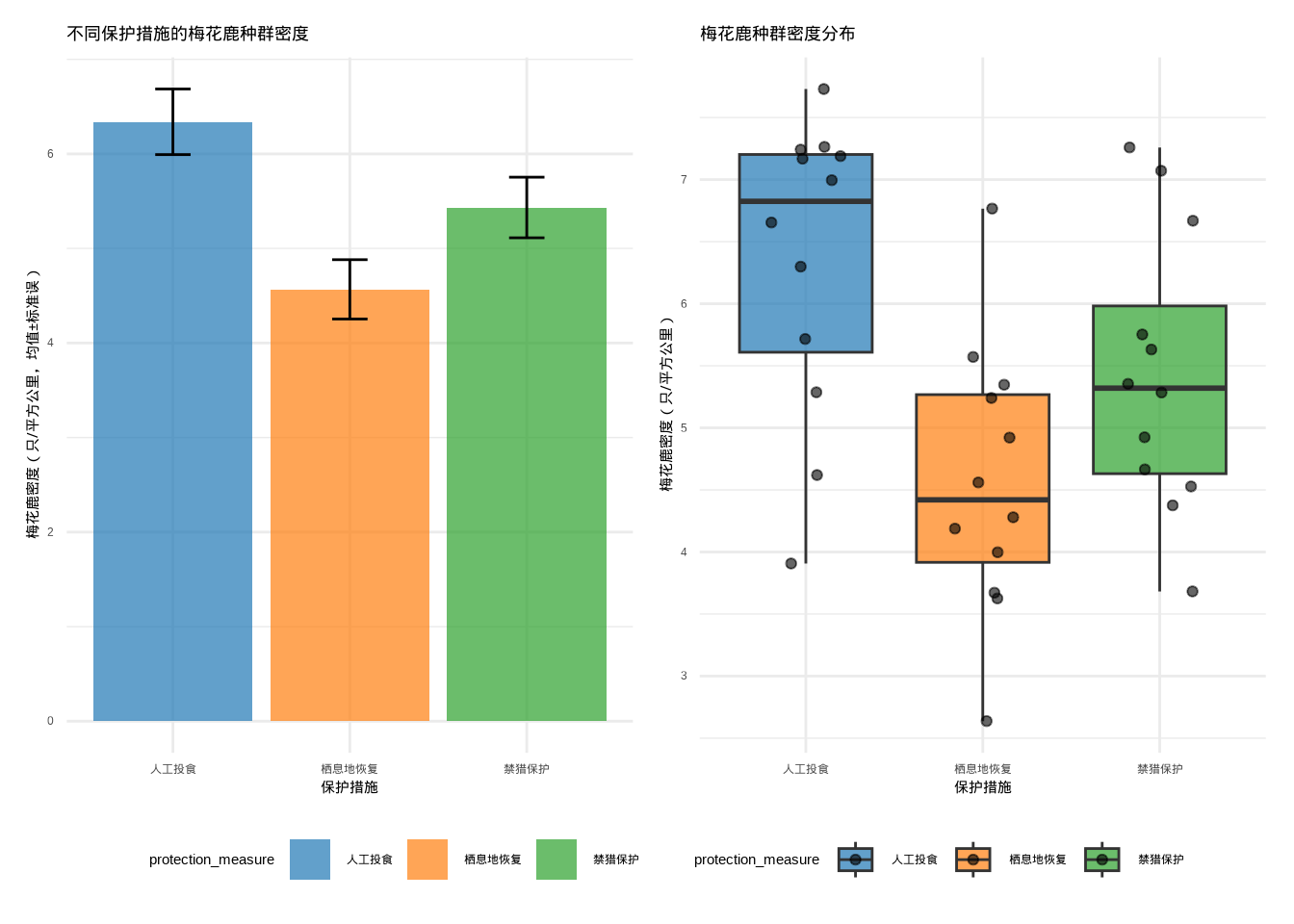
图6.14: 多重比较校正实例分析:展示不同保护措施梅花鹿种群密度的多重比较结果及其可视化
图 6.14 展示了多重比较校正的综合可视化结果。该组合图形将均值图(左侧)和箱线图(右侧)并排显示,便于直观比较三种保护措施下梅花鹿种群密度的统计特征。均值图显示各组的平均密度及其标准误,箱线图则展示了数据的分布特征和个体观测值。这种组合可视化方式有助于全面理解多重比较分析的结果。
结果解释:
在这个实例中,我们首先使用方差分析检验三种保护措施下梅花鹿种群密度是否存在总体差异。如果方差分析显著(p < 0.05),我们接着使用三种不同的多重比较校正方法:
- Tukey HSD检验:提供所有组对比较的调整后p值和置信区间
- Bonferroni校正:最保守的方法,适用于预先计划的比较
- FDR控制:在发现力和错误控制之间取得平衡
通过比较不同校正方法的结果,我们可以更全面地理解组间差异的模式,并选择最适合研究目的的方法。
6.7.6 多重比较校正效果的可视化
让我们通过另一个可视化来理解多重比较校正如何影响p值的解释:
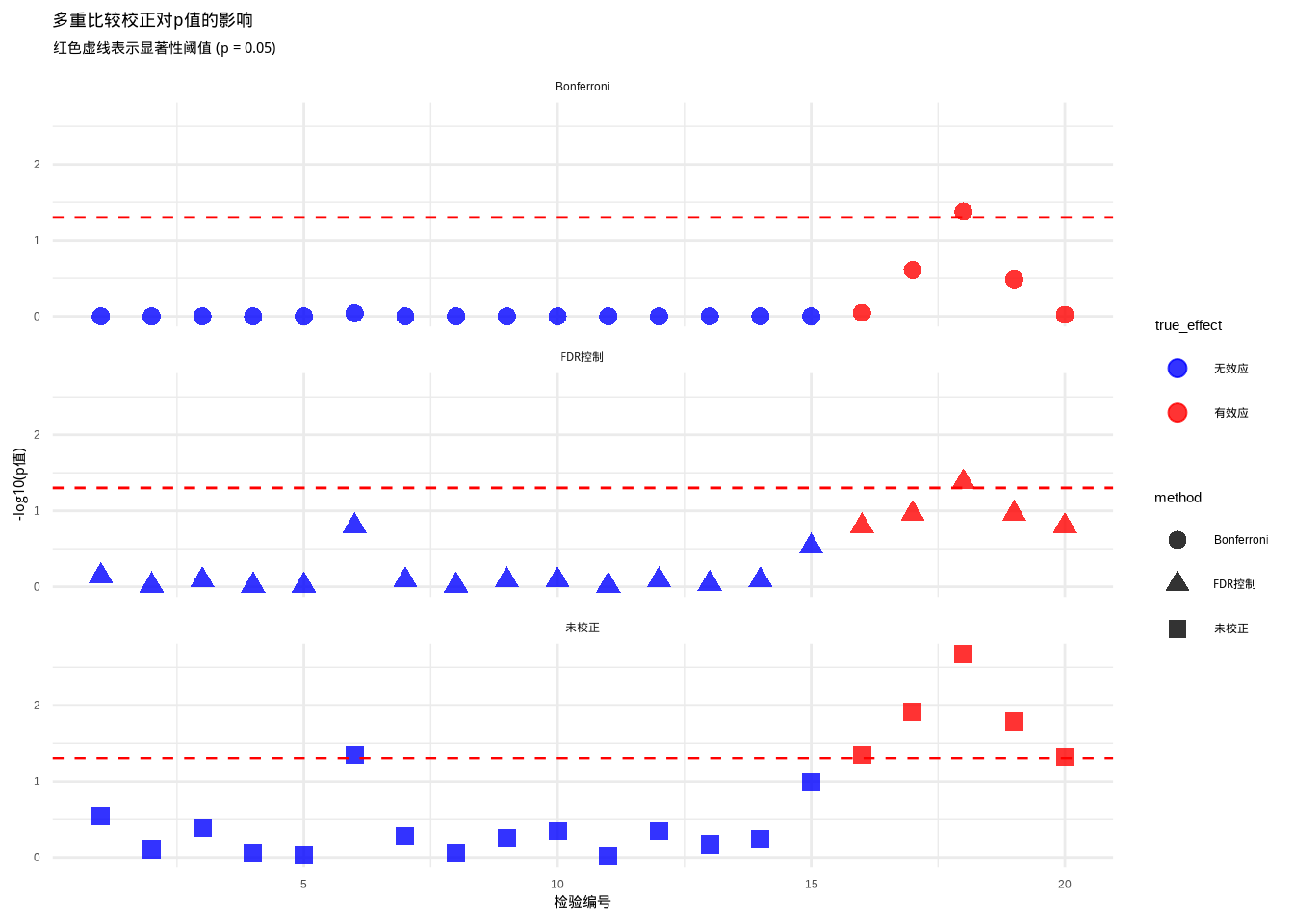
图6.15: 多重比较校正效果的可视化:比较未校正、Bonferroni校正和FDR控制三种方法对p值的影响。通过颜色和形状的组合区分不同效应类型和校正方法。
图 6.15 展示了多重比较校正效果的直观可视化。该图形模拟了20个假设检验的情景,其中15个来自零假设(无真实效应,蓝色点),5个来自备择假设(有真实效应,红色点)。图形采用三面板布局,分别显示未校正、Bonferroni校正和FDR控制三种方法处理后的p值。通过比较各面板中超过红色虚线(显著性阈值)的点数,可以直观理解不同校正方法在错误控制和发现力之间的权衡。
图表解释:
这个图表展示了三种情况下的p值:
- 未校正:直接使用原始p值,可能产生多个假阳性
- Bonferroni校正:p值被严格调整,减少了假阳性但可能错过一些真实效应
- FDR控制:在控制假阳性比例的同时,保留了更多的真实效应
通过这个可视化,我们可以直观地理解不同校正方法如何在错误控制和发现力之间进行权衡。
6.7.7 实用建议与最佳实践
在生态学研究中正确应用多重比较校正至关重要。以下是一些实用的建议:
1. 选择合适的校正方法
| 研究情境 | 推荐方法 | 理由 |
|---|---|---|
| 预先计划的少量比较 | Bonferroni | 简单保守,严格控制第一类错误 |
| 方差分析后的事后比较 | Tukey HSD | 专门设计,考虑所有组对比较 |
| 大规模探索性研究 | FDR控制 | 平衡发现力和错误控制 |
| 生态风险评估 | Bonferroni | 保守性有助于避免假阳性 |
| 生态基因组学 | FDR控制 | 处理大量基因表达数据 |
2. 分析流程的最佳实践
- 先总体,后具体:先进行方差分析检验总体差异,只有在总体差异显著时才进行多重比较
- 明确研究目的:根据研究是验证性还是探索性选择校正方法
- 报告完整信息:在论文中报告使用的校正方法、调整后的p值和置信区间
- 考虑样本量:确保样本量足够检测预期的效应大小
3. 常见错误与避免方法
- 错误:直接进行多个\(t\)检验而不校正
- 避免方法:始终使用适当的校正方法
- 错误:在方差分析不显著时仍进行多重比较
- 避免方法:只有在总体差异显著时才进行事后检验
- 错误:不报告使用的校正方法
- 避免方法:在方法部分明确说明统计分析方法
- 错误:过度依赖单一校正方法
- 避免方法:根据研究目的和数据特性选择合适的方法
4. 生态学研究中的特殊考虑
在生态学研究中,多重比较校正的选择还应考虑:
- 保护生物学:在濒危物种保护研究中,可能更倾向于保守的方法(如Bonferroni)来避免假阳性
- 生态系统管理:在管理决策中,需要平衡统计严谨性和实际应用价值
- 长期监测:在时间序列数据分析中,考虑重复测量方差分析和相应的事后检验
5. R语言实现技巧
# 常用的多重比较校正函数
# Tukey HSD检验
# 假设已经执行了方差分析:aov_result <- aov(response ~ group, data = data)
TukeyHSD(aov_result)
# Bonferroni校正
pairwise.t.test(data$response, data$group, p.adjust.method = "bonferroni")
# FDR控制 (Benjamini-Hochberg)
pairwise.t.test(data$response, data$group, p.adjust.method = "BH")
# 其他校正方法
p.adjust(p_values, method = "holm") # Holm校正
p.adjust(p_values, method = "fdr") # FDR控制
p.adjust(p_values, method = "BY") # Benjamini-Yekutieli生态学意义:通过正确应用多重比较校正,生态学家能够:
- 得出更可靠的统计结论
- 避免将随机波动误认为生态规律
- 为生态保护和管理决策提供更坚实的科学依据
- 促进生态学研究的严谨性和可重复性
记住,多重比较校正不是统计“魔术”,而是基于概率理论的严谨方法。理解其原理并正确应用,将使你的生态学研究更加科学和可信。
在掌握了如何避免多重比较导致的假阳性问题后,我们需要关注另一个同样重要的统计问题——统计功效。即使我们使用了正确的统计检验和多重比较校正,如果研究设计本身缺乏足够的检测能力,我们仍然可能错过真实的生态效应。功效分析正是为此目的而设计的统计工具,它帮助我们在研究设计阶段就评估检测预期效应的可能性。
6.8 生态保护效果的功效分析
在生态学研究中,我们不仅关心统计显著性,更关心研究是否有足够的能力检测到真实存在的生态效应。功效分析正是为此目的而设计的统计工具,它帮助我们在研究设计阶段就评估检测预期效应的可能性,从而确保我们的研究既不会因为样本过小而错过真实效应,也不会因为样本过大而浪费宝贵的科研资源。
6.8.1 统计功效的概念与生态学意义
统计功效定义为正确拒绝错误零假设的概率,即1-\(\beta\),其中β是第二类错误的概率。在生态学语境中,统计功效可以理解为:当某种生态效应确实存在时,我们的研究能够检测到这种效应的概率。例如,如果某种保护措施确实能够提高濒危物种的存活率,统计功效就是我们的研究能够正确发现这种保护效果的概率。
统计功效的生态学意义极为重要。一个功效不足的研究就像使用分辨率不足的望远镜观察星空——我们可能错过真实存在的天体,却误以为天空空无一物。在生态保护领域,功效不足的研究可能导致我们错过有效的保护措施,让濒危物种继续面临威胁;在环境风险评估中,功效不足可能让我们低估污染物的生态毒性,导致生态系统持续受损。因此,进行充分的功效分析不仅是统计严谨性的要求,更是生态伦理的体现。
6.8.2 功效分析的核心要素
功效分析涉及四个相互关联的核心要素,理解这些要素之间的关系对于合理设计生态学研究至关重要。这四个要素——效应大小、样本量、显著性水平和统计功效——构成了一个紧密相连的系统,任何一个要素的变化都会影响其他要素。在生态学研究中,我们需要在这些要素之间找到最优的平衡点,既要确保研究有足够的检测能力,又要考虑实际的资源约束和伦理考量。
效应大小是衡量生态效应实际重要性的量化指标,它反映了自变量对因变量影响的实际幅度。与统计显著性不同,效应大小关注的是生态学意义上的实际差异,而非统计概率。在生态学研究中,效应大小的概念具有多重维度:它可以是均值差异、方差解释比例、相关系数,或者是分类变量间的关联强度。
效应大小的生态学解释需要结合具体的研究情境和生态学背景。一个在生理学研究中微不足道的效应可能在保护生物学中具有决定性意义。例如,某种农药导致非靶标昆虫死亡率增加3%的效应,在农业生产的经济效益评估中可能被认为是可接受的副作用,但在保护濒危传粉昆虫物种时,这个微小的死亡率增加可能意味着整个种群的崩溃。同样,在气候变化研究中,年平均温度升高0.5℃的效应在短期气象观测中可能不显著,但对于高山生态系统的物种分布和物候期却可能产生深远影响。
效应大小的估计需要基于多方面的信息来源:文献回顾可以提供类似研究的效应大小范围;预实验数据可以提供初步的效应估计;专家经验可以基于生态学理论提供合理的预期;最小生态学重要差异(Minimum Ecologically Important Difference)的概念可以帮助确定具有实际生态意义的效应阈值。在缺乏可靠信息时,可以使用Cohen提出的效应大小标准作为参考:小效应(d=0.2)、中效应(d=0.5)、大效应(d=0.8),但这些标准在生态学中的应用需要谨慎,因为生态系统的复杂性和敏感性往往要求我们重新定义什么构成”重要”的效应。
样本量是研究中最直接可控的因素,也是连接统计理论与生态实践的桥梁。样本量直接影响统计功效的核心机制在于其对抽样误差的控制——样本量越大,样本统计量对总体参数的估计越精确,抽样误差越小,从而检测真实效应的能力越强。这种关系遵循平方根法则:标准误与样本量的平方根成反比,这意味着要将标准误减半,需要将样本量增加四倍。
然而,生态学研究在样本量选择上面临着独特的挑战和约束。野外调查往往受制于时间、经费和可行性的限制:在偏远地区进行生物多样性调查可能需要数周甚至数月的野外工作;保护生物学研究可能涉及数量极其有限的濒危物种个体;长期生态监测需要考虑研究的可持续性和对生态系统的干扰最小化。此外,生态系统的空间异质性和时间变异性也增加了确定合适样本量的复杂性。
功效分析在样本量确定中发挥着关键作用,它帮助我们在这些约束条件下找到最优的平衡点。通过功效分析,我们可以回答一系列关键问题:在给定的效应大小和显著性水平下,达到期望统计功效需要多大的样本量?如果实际条件限制了样本量,那么在这种样本量下我们能够检测到多小的效应?这种前瞻性的分析不仅优化了资源利用,也提高了研究的科学价值。
显著性水平(\(\alpha\))是我们愿意接受的第一类错误风险,即在零假设实际上为真时错误地拒绝它的概率。在传统的统计实践中,\(\alpha\)通常设定为0.05,但这个选择在生态学中需要更加细致的考量,因为它涉及到第一类错误和第二类错误之间的根本权衡。
在生态学研究中,显著性水平的选择应该基于对两类错误后果的深入分析。在保护生物学研究中,第二类错误的后果往往更为严重——错过一个真实的保护效应可能意味着濒危物种的继续衰退甚至灭绝。因此,在保护生物学中,我们可能愿意接受较高的\(\alpha\)水平(如0.10)来换取更高的统计功效,确保不会错过重要的保护机会。例如,在评估某种栖息地恢复措施对濒危鸟类的影响时,我们可能更关心不要错过真实的正向效应,即使这意味着有10%的概率错误地宣称无效的措施有效。
相反,在涉及重大政策决策或资源分配的研究中,第一类错误的后果可能更为严重。错误地宣称某种污染物具有生态毒性可能导致不必要的环境管制和经济损失;错误地宣称某种外来物种具有入侵风险可能引发不必要的控制措施。在这种情况下,我们需要更严格的\(\alpha\)水平(如0.01)来减少假阳性的风险。例如,在评估新型农药的环境安全性时,我们可能要求更强的证据来证明其有害性。
统计功效(1-\(\beta\))是我们期望达到的检测能力,即在备择假设实际上为真时正确拒绝零假设的概率。在生态学研究中,统计功效通常设定为0.80,这个标准被认为是在统计严谨性和实际可行性之间的合理折中。
统计功效为0.80意味着我们有80%的概率正确检测到真实存在的效应,同时接受20%的错过真实效应的风险。这个选择主要基于以下几个考虑:首先,从实际可行性来看,要达到更高的统计功效(如0.90或0.95)通常需要极大的样本量增加,这在生态学研究中往往难以实现。其次,从资源分配的角度看,将功效从0.80提高到0.90通常需要不成比例的资源投入。最后,统计功效为0.80在大多数研究情境下被认为是足够的检测能力。
然而,在特定的高风险生态学研究中,我们可能需要更高的功效标准。在涉及濒危物种保护的研究中,错过真实保护效应的后果可能极为严重,因此可能需要0.90甚至0.95的功效水平。在重大环境风险评估中,低估污染物生态毒性的风险可能带来不可逆的生态破坏,同样需要更高的检测能力。在这些情况下,功效分析可以帮助我们理解达到更高功效所需的资源投入,为决策提供依据。
6.8.3 功效分析在生态学研究设计中的应用
功效分析最重要的应用是在研究设计阶段确定合适的样本量。通过功效分析,我们可以在研究开始前就回答一个关键问题:“为了有80%的概率检测到预期大小的效应,我需要多大的样本量?”
让我们通过一个具体的生态学实例来理解功效分析的实际应用:
实例:设计梅花鹿保护措施效果评估的研究
假设我们计划研究禁猎保护对梅花鹿种群密度的影响。基于文献回顾和预实验,我们预期禁猎保护将使梅花鹿密度从保护前的平均2.5只/平方公里提高到保护后的平均4.0只/平方公里(效应大小)。我们设定显著性水平α = 0.05,期望统计功效为0.80。
通过功效分析,我们可以计算出需要的样本量。如果计算结果显示需要监测15个保护区,那么我们就知道:在这个样本量下,如果禁猎保护确实能提高梅花鹿密度,我们有80%的概率能够检测到这种效应。
如果实地条件限制我们只能监测10个保护区,功效分析可以告诉我们:在这个样本量下,统计功效可能只有60%。这意味着即使禁猎保护确实有效,我们也有40%的概率会错过这个效应。这种前瞻性的认识帮助我们做出更明智的决策——要么调整研究设计,要么重新评估研究的可行性。
6.8.4 不同类型检验的功效分析
不同的统计检验需要不同的功效分析方法。在生态学研究中,我们经常遇到的功效分析包括:
\(t\)检验的功效分析适用于比较两个组均值差异的研究。例如,比较禁猎保护区域和未保护区域的梅花鹿密度,或者比较不同保护措施实施前后的种群变化。\(t\)检验的功效分析相对简单,主要考虑效应大小(标准化均值差异)、样本量和显著性水平。
方差分析的功效分析适用于比较三个或更多组均值的研究。例如,比较不同保护措施(禁猎、栖息地恢复、人工投食)对梅花鹿种群密度的影响,或者评估不同管理策略的保护效果。方差分析的功效分析需要考虑组数、效应大小(如η²或f)、样本量和显著性水平。
相关分析和回归的功效分析适用于研究变量间关系的研究。例如,分析温度与物种丰富度的关系,或者建立环境因子与生态指标的预测模型。这类功效分析需要考虑相关系数、样本量和显著性水平。
卡方检验的功效分析适用于分类数据的研究。例如,分析物种在不同生境中的分布差异,或者检验不同处理对生物存活率的影响。卡方检验的功效分析需要考虑效应大小(如Cramér’s V)、样本量和显著性水平。
功效分析的实践建议与注意事项
在进行功效分析时,生态学家需要注意以下几个关键点:
合理估计效应大小是功效分析成功的关键。效应大小的估计可以基于:文献回顾(类似研究的效应大小)、预实验数据、专家经验,或者使用最小生态学重要差异(Minimum Ecologically Important Difference)的概念。在缺乏可靠信息时,可以使用Cohen提出的效应大小标准(小效应:d=0.2,中效应:d=0.5,大效应:d=0.8)作为参考。
考虑研究的实际约束。生态学研究很少能在理想条件下进行,我们需要在统计理想和现实约束之间找到平衡。功效分析应该考虑:野外工作的可行性、经费限制、时间约束、伦理考量(如对濒危物种的干扰最小化)。
进行敏感性分析。由于效应大小的估计往往存在不确定性,进行敏感性分析是明智的做法。我们可以计算不同效应大小假设下所需的样本量,从而了解研究对效应大小估计的敏感程度。
报告完整的功效分析。在论文的方法部分,应该详细报告功效分析的过程:使用的效应大小估计及其依据、设定的显著性水平和统计功效、计算出的样本量、以及任何调整或妥协的考虑。
生态学意义与伦理责任
功效分析不仅仅是一个统计工具,它体现了生态学研究的科学严谨性和伦理责任。一个经过充分功效分析设计的研究:
- 提高了研究的科学价值:确保研究有足够的能力回答科学问题
- 优化了资源利用:避免样本过小导致的资源浪费,也避免样本过大造成的不必要消耗
- 增强了结果的可信度:统计上不显著的结果更可能是真实无效应,而非检测力不足
- 促进了知识的积累:为后续的元分析和综述研究提供可靠的基础
在生态保护和管理决策日益依赖科学证据的今天,功效分析成为了连接生态学理论与保护实践的重要桥梁。通过严谨的功效分析,我们不仅是在进行统计学计算,更是在履行对生态系统和未来世代的责任——确保我们的研究能够为生态保护提供真正有用的知识,而不是在统计迷雾中迷失方向。
R语言实现示例
在生态学研究中,R语言提供了强大的功效分析工具包pwr,可以帮助我们进行各种统计检验的功效分析。下面我们将详细介绍几个关键函数的用法和参数含义,并通过具体的生态学实例演示如何进行功效分析。
1. 安装和加载pwr包
首先需要安装并加载功效分析包:
pwr包提供了多种统计检验的功效分析函数,包括\(t\)检验、方差分析、相关分析、卡方检验等。
2. \(t\)检验的功效分析
pwr.t.test()函数用于\(t\)检验的功效分析,适用于比较两个组均值差异的研究。让我们通过一个具体的生态学实例来理解其用法:
# 实例:禁猎保护对梅花鹿种群密度影响的功效分析
# 研究问题:比较禁猎保护区域和未保护区域的梅花鹿密度
# 计算所需样本量 - 使用pwr.t.test函数进行t检验的功效分析
t_power <- pwr.t.test(
d = 0.5, # 效应大小(Cohen's d)- 标准化均值差异,0.5表示中等效应
sig.level = 0.05, # 显著性水平 - 第一类错误风险,通常设为0.05
power = 0.8, # 期望统计功效 - 正确检测真实效应的概率,通常设为0.80
type = "two.sample", # 检验类型:独立样本t检验 - 比较两个独立组的均值
alternative = "two.sided" # 备择假设:双侧检验 - 检验两个方向的差异
)
# 输出功效分析结果
cat("=== 独立样本t检验功效分析 ===\n")## === 独立样本t检验功效分析 ===##
## Two-sample t test power calculation
##
## n = 63.76561
## d = 0.5
## sig.level = 0.05
## power = 0.8
## alternative = two.sided
##
## NOTE: n is number in *each* group参数解释: - d:效应大小,使用Cohen’s d表示标准化均值差异。在生态学中,d=0.2表示小效应,d=0.5表示中效应,d=0.8表示大效应。 - sig.level:显著性水平,通常设为0.05。 - power:期望的统计功效,通常设为0.80。 - type:检验类型,可以是”two.sample”(独立样本)、“one.sample”(单样本)或”paired”(配对样本)。 - alternative:备择假设类型,可以是”two.sided”(双侧)、“greater”(单侧,组1>组2)或”less”(单侧,组1<组2)。
结果解释: 输出结果会显示达到期望功效所需的每组样本量。在这个例子中,结果显示每组需要约64个样本才能以80%的概率检测到中等效应大小的差异。
3. 方差分析的功效分析
pwr.anova.test()函数用于方差分析的功效分析,适用于比较三个或更多组均值的研究:
# 实例:不同保护措施对梅花鹿种群密度影响的功效分析
# 研究问题:比较禁猎保护、栖息地恢复、人工投食三种保护措施的梅花鹿密度
# 计算所需样本量
anova_power <- pwr.anova.test(
k = 3, # 组数
f = 0.25, # 效应大小(Cohen's f)
sig.level = 0.05, # 显著性水平
power = 0.8 # 期望统计功效
)
cat("\n=== 方差分析功效分析 ===\n")##
## === 方差分析功效分析 ===##
## Balanced one-way analysis of variance power calculation
##
## k = 3
## n = 52.3966
## f = 0.25
## sig.level = 0.05
## power = 0.8
##
## NOTE: n is number in each group参数解释: - k:组数,即要比较的处理水平数量。 - f:效应大小,使用Cohen’s f表示。在方差分析中,f=0.1表示小效应,f=0.25表示中效应,f=0.4表示大效应。 - sig.level和power的含义与\(t\)检验相同。
效应大小f的计算: Cohen’s f可以通过方差分析中的η²(eta平方)来计算: \[f = \sqrt{\frac{\eta^2}{1-\eta^2}}\] 其中η²表示组间方差占总方差的比例。
4. 相关分析的功效分析
pwr.r.test()函数用于相关分析的功效分析,适用于研究两个连续变量之间的关系:
# 实例:温度与物种丰富度关系的功效分析
# 研究问题:检验年平均温度与鸟类物种丰富度的相关性
# 计算所需样本量
cor_power <- pwr.r.test(
r = 0.3, # 预期相关系数
sig.level = 0.05, # 显著性水平
power = 0.8, # 期望统计功效
alternative = "two.sided" # 备择假设:双侧检验
)
cat("\n=== 相关分析功效分析 ===\n")##
## === 相关分析功效分析 ===##
## approximate correlation power calculation (arctangh transformation)
##
## n = 84.07364
## r = 0.3
## sig.level = 0.05
## power = 0.8
## alternative = two.sided参数解释: - r:预期的相关系数。在生态学中,r=0.1表示弱相关,r=0.3表示中等相关,r=0.5表示强相关。
5. 卡方检验的功效分析
pwr.chisq.test()函数用于卡方检验的功效分析,适用于分类数据的分析:
# 实例:物种在不同生境中分布差异的功效分析
# 研究问题:检验物种在三种生境类型中的分布是否存在差异
# 计算所需样本量
chisq_power <- pwr.chisq.test(
w = 0.3, # 效应大小(Cohen's w)
N = NULL, # 总样本量(待计算)
df = 2, # 自由度
sig.level = 0.05, # 显著性水平
power = 0.8 # 期望统计功效
)
cat("\n=== 卡方检验功效分析 ===\n")##
## === 卡方检验功效分析 ===##
## Chi squared power calculation
##
## w = 0.3
## N = 107.0521
## df = 2
## sig.level = 0.05
## power = 0.8
##
## NOTE: N is the number of observations参数解释: - w:效应大小,使用Cohen’s w表示。在卡方检验中,w=0.1表示小效应,w=0.3表示中效应,w=0.5表示大效应。 - df:自由度,计算公式为(行数-1)×(列数-1)。 - N:总样本量。
6. 功效曲线的绘制
功效曲线可以直观地展示样本量与统计功效之间的关系,帮助我们理解样本量选择的权衡:
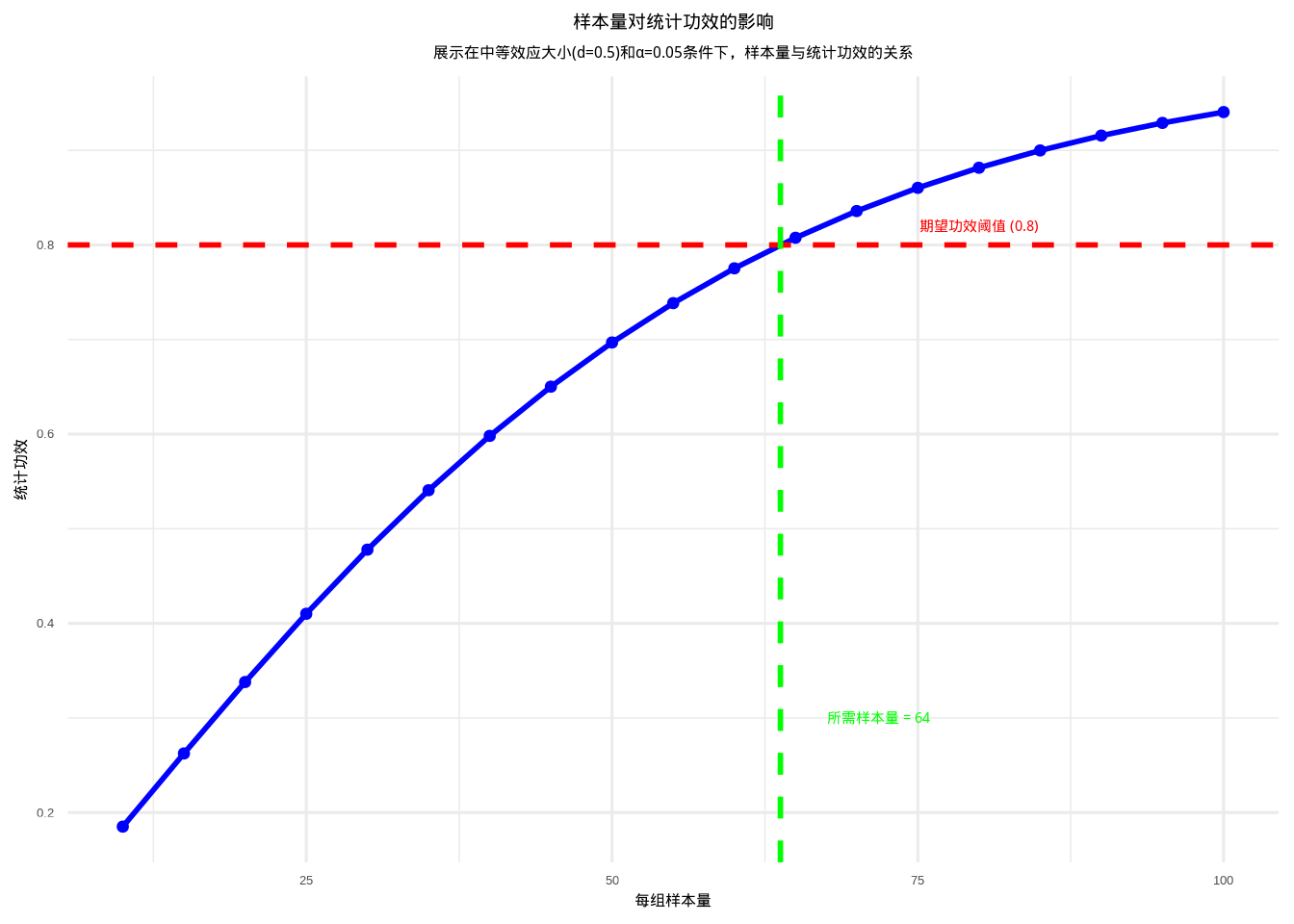
图6.16: 样本量对统计功效的影响:展示在中等效应大小下样本量增加如何提高统计功效。蓝色曲线表示功效变化,红色虚线表示功效阈值,绿色虚线表示所需样本量,通过颜色和线条类型的组合增强可辨识度。
图表解释: - 蓝色曲线显示随着样本量增加,统计功效逐渐提高 - 红色虚线表示常用的功效阈值0.80 - 绿色虚线显示达到0.80功效所需的样本量 - 从曲线可以看出,样本量较小时功效增长较快,样本量较大时增长趋于平缓
7. 敏感性分析
由于效应大小的估计往往存在不确定性,进行敏感性分析是明智的做法:
# 测试不同效应大小下的样本量需求
effect_sizes <- c(0.2, 0.3, 0.5, 0.8) # 小、中小、中、大效应
sample_needs <- sapply(effect_sizes, function(d) {
pwr.t.test(
d = d, sig.level = 0.05, power = 0.8,
type = "two.sample"
)$n
})
# 创建数据框
sensitivity_df <- data.frame(
effect_size = effect_sizes,
sample_need = sample_needs,
effect_label = c(
"小效应(d=0.2)", "中小效应(d=0.3)",
"中效应(d=0.5)", "大效应(d=0.8)"
)
)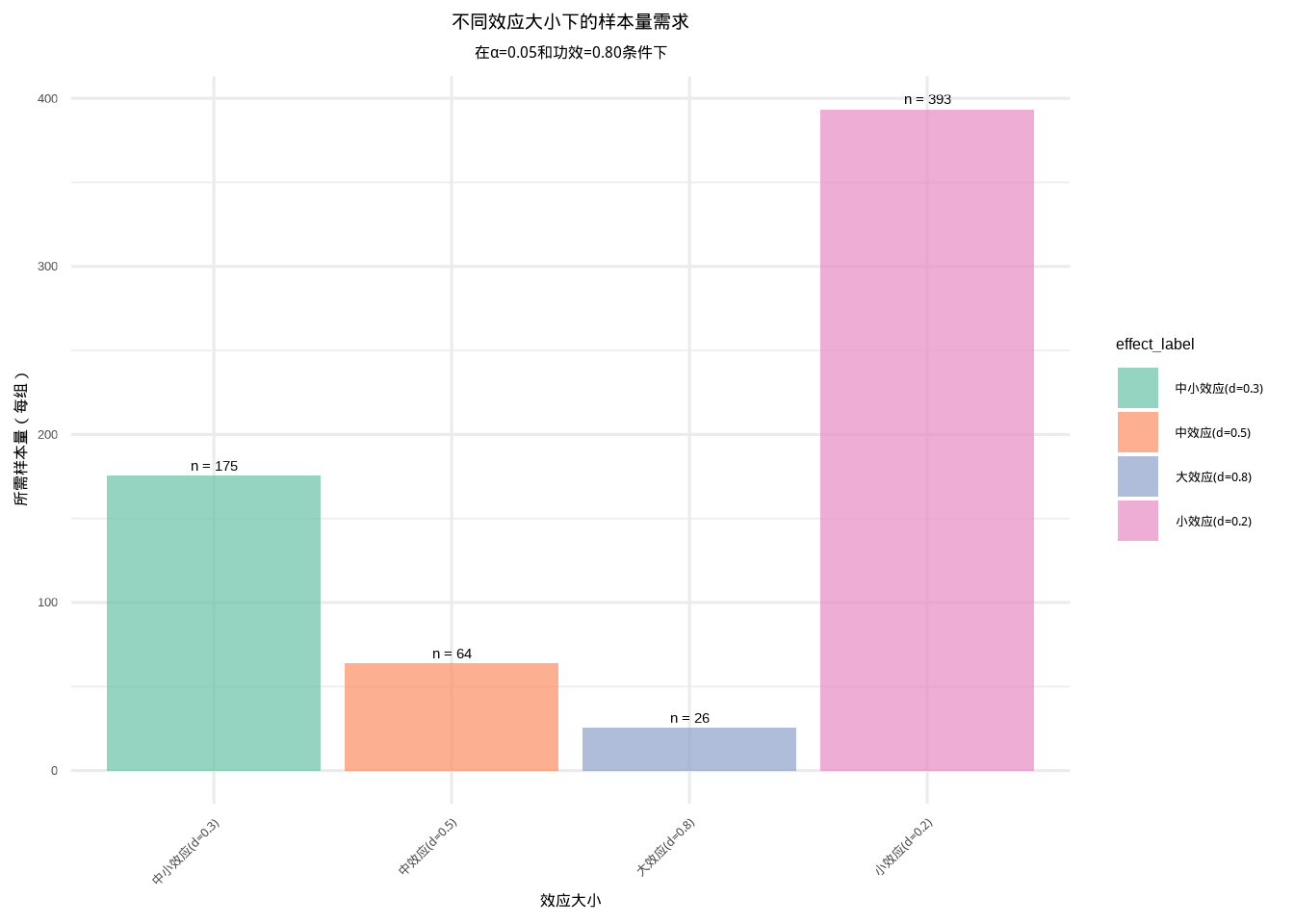
图6.17: 效应大小对所需样本量的影响:展示不同效应大小水平下达到期望统计功效所需的样本量。通过颜色和填充纹理的组合区分不同效应大小类别。
图 6.17 展示了效应大小对样本量需求的敏感性分析结果。该柱状图直观地比较了四种不同效应大小水平(小效应d=0.2、中小效应d=0.3、中效应d=0.5、大效应d=0.8)下达到80%统计功效所需的样本量。从图中可以清晰地看到,随着效应大小的增加,所需的样本量显著减少。例如,检测小效应需要每组约394个样本,而检测大效应仅需每组约26个样本。这种敏感性分析有助于研究者在研究设计阶段根据预期的效应大小合理规划样本量。
实践建议:
在实际应用中,功效分析需要综合考虑多个关键因素。首先,效应大小的合理估计至关重要,这可以基于文献回顾、预实验或专家经验来完成。其次,如果研究计划进行多个检验,需要考虑多重检验校正,采用更严格的显著性水平来控制第一类错误率。同时,研究者需要在功效分析的理想要求与实际资源约束之间找到平衡点,确保研究设计既具有足够的统计检测能力,又在实际条件下可行。最后,在论文中详细报告功效分析的过程和结果,包括效应大小估计的依据、样本量计算的参数设置以及实际达到的功效水平,这对于研究的透明度和可重复性至关重要。
通过这些详细的R语言实现示例,生态学家可以在研究设计阶段就对自己的研究有清晰的预期,确保研究既具有足够的统计检测能力,又在实际资源约束下可行。
6.9 总结
本章系统介绍了经典假设检验方法在生态学研究中的应用,通过贯穿始终的梅花鹿保护案例,构建了一个从基础概念到高级应用的完整学习框架。假设检验作为生态统计学的核心工具,为生态学家在充满不确定性的自然系统中做出科学判断提供了严谨的数学基础。
假设检验的核心在于将生态学问题转化为明确的统计问题,通过设定零假设和备择假设,在证据与不确定性之间建立科学的判断标准。零假设通常设定为”无效应”状态,体现了科学研究的保守性和可证伪性原则;备择假设则代表我们想要证明的生态效应。检验统计量和p值提供了量化证据强度的工具,而显著性水平\(\alpha\)则设定了我们愿意接受的第一类错误风险。
在生态学研究中,假设检验不仅是一种统计技术,更是一种科学的思维方式。它帮助我们在复杂的自然系统中区分真实的生态规律与随机波动,为保护决策、环境评估和生态管理提供基于证据的科学依据。
单样本检验方法为生态基准验证提供了可靠工具。单样本\(t\)检验适用于检验样本均值是否与特定理论值存在显著差异,如检验梅花鹿种群密度是否达到保护目标、河流pH值是否偏离中性标准等。当数据不满足正态分布假设时,单样本符号检验提供了基于中位数比较的稳健替代方法。这些方法在生态保护标准制定、环境质量评估和物种保护目标验证中具有重要应用价值。
双样本检验方法为生态对比研究提供了系统的统计框架。独立样本\(t\)检验适用于比较两个独立样本的均值差异,如比较不同处理对生态指标的影响;配对样本\(t\)检验则专门用于配对设计数据,通过考虑个体间相关性提高了统计功效。当数据存在偏态分布或极端值时,Mann-Whitney U检验提供了基于秩次的非参数替代方法。这些方法在保护措施效果评估、生境差异分析和污染影响研究中发挥着关键作用。
多样本检验方法为同时比较多个处理或生境的生态效应提供了系统框架。方差分析(ANOVA)通过分解总变异为组间变异和组内变异,检验多个总体均值是否相等。当数据不满足正态分布假设时,Kruskal-Wallis检验提供了基于秩次的非参数替代方法。这些方法在比较多种保护措施效果、分析不同生境类型的生态差异以及评估复杂管理策略中具有广泛应用。
多重比较校正是生态统计学中必须重视的问题。当同时进行多个统计检验时,直接使用多个\(t\)检验会导致第一类错误率显著膨胀。Bonferroni校正提供了最保守的校正方法,Tukey HSD检验专门为方差分析后的事后比较设计,而FDR控制则在发现力和错误控制之间取得平衡。正确的多重比较校正确保了统计结论的可靠性,避免了将随机波动误认为真实的生态效应。
功效分析是连接统计理论与生态实践的重要桥梁。通过考虑效应大小、样本量、显著性水平和统计功效四个核心要素,功效分析帮助我们在研究设计阶段就评估检测预期效应的可能性。这不仅优化了资源利用,避免了样本过小导致的检测力不足或样本过大造成的资源浪费,更体现了生态学研究的科学严谨性和伦理责任。
本章的学习不仅传授了具体的统计方法,更重要的是培养了生态学研究的统计思维方式。优秀的生态学家应该深刻理解统计概念的本质,认识到p值是在零假设下观测到当前证据强度的概率,而非零假设为真的概率;能够平衡统计显著性与生态学重要性,结合效应大小、置信区间和专业知识全面评估研究结果;善于考虑两类错误的权衡,根据研究问题的性质在假阳性和假阴性风险之间做出明智选择;重视研究设计的前瞻性,通过功效分析确保研究具有足够的检测能力;始终保持批判性思维,对统计结果保持合理的怀疑,理解统计结论的概率性质。
从经典参数检验到传统非参数检验,本章介绍的假设检验方法构成了生态统计学的基础工具包。这些方法虽然不依赖于严格的正态分布假设,但它们仍然是基于经典统计理论的传统方法。随着生态学研究的深入和复杂化,我们越来越多地遇到这样的情况:我们感兴趣的统计量根本没有现成的理论分布可以参照,或者数据的复杂性超出了传统方法的处理能力。
这种局限性为下一章介绍的基于模拟的假设检验方法提供了逻辑基础。从经典的非参数检验到现代的基于模拟方法,体现了统计方法学从理论驱动到数据驱动的演进,为生态学家应对日益复杂的生态问题提供了更强大的工具包。
经典假设检验方法在生态保护实践中具有广泛的应用价值。在梅花鹿保护研究中,这些方法帮助我们:验证种群是否达到保护目标、评估保护措施的真实效果、比较不同保护策略的优劣、控制多重比较的风险、确保研究设计的科学性。这种系统的统计思维不仅提高了研究的科学价值,更为生态保护决策提供了可靠的科学依据。
通过本章的学习,生态学本科生将建立起运用统计工具解决实际生态问题的能力,培养在数据海洋中发现真实生态规律的敏锐洞察力。这种能力将伴随整个科学生涯,无论从事生态研究、环境保护还是资源管理,都将受益无穷。经典假设检验作为生态统计学的基石,为我们探索统计推断与生态规律交汇之处的旅程奠定了坚实基础。
6.10 综合练习
练习题1:梅花鹿保护措施效果评估
某自然保护区为了评估禁猎保护措施对梅花鹿种群的影响,在保护措施实施前和实施一年后分别调查了15个样点的梅花鹿密度(只/平方公里)。数据如下:
- 保护前:2.1, 2.3, 2.5, 2.8, 3.0, 2.4, 2.6, 2.9, 3.1, 2.7, 2.2, 2.8, 3.0, 2.5, 2.9
- 保护后:3.8, 4.2, 4.5, 4.9, 5.1, 4.3, 4.6, 4.8, 5.2, 4.4, 3.9, 4.7, 5.0, 4.1, 4.6
问题:
(1) 应该使用哪种统计检验方法来分析保护措施的效果?为什么?
(2) 设定适当的零假设和备择假设。
(3) 如果检验结果显示p = 0.003,如何解释这个结果?
(4) 除了统计显著性,还需要考虑哪些因素来全面评估保护措施的效果?
练习题2:不同森林类型鸟类多样性比较
生态学家研究了三种不同森林类型(阔叶林、针叶林、混交林)中的鸟类物种丰富度。在每个森林类型中随机选择了12个样点进行调查,得到以下数据(单位:物种数):
- 阔叶林:18, 20, 22, 19, 21, 23, 17, 20, 22, 19, 21, 24
- 针叶林:12, 14, 15, 13, 16, 14, 11, 13, 15, 12, 14, 16
- 混交林:16, 18, 19, 17, 20, 18, 15, 17, 19, 16, 18, 21
问题:
(1) 应该使用哪种统计检验方法来比较三种森林类型的鸟类多样性?
(2) 如果方差分析结果显示F = 15.8,p < 0.001,如何解释这个结果?
(3) 为什么不能直接使用多个\(t\)检验来比较所有组对?
(4) 如果需要进行事后比较,推荐使用哪种多重比较校正方法?为什么?
练习题3:研究设计与功效分析
某研究团队计划开展一项研究,评估新型栖息地恢复措施对濒危蝴蝶种群的影响。他们预期该措施能将蝴蝶密度从当前的每公顷5只提高到每公顷8只。已知蝴蝶密度的标准差约为2只/公顷。
问题:
(1) 计算Cohen’s d效应大小。
(2) 如果设定α = 0.05,期望功效为0.80,使用独立样本\(t\)检验,需要多大的样本量?
(3) 如果实地条件限制只能调查20个样点(每组10个),实际的统计功效是多少?
(4) 在保护生物学研究中,为什么有时需要接受较高的α水平(如0.10)?