5 生态变量间的关联与相似
5.1 引言
生态学研究的一个核心任务是揭示自然界中各种现象之间的内在联系。在前面的章节中,我们学习了如何描述生态系统的特征,如种群数量、物种多样性等。然而,生态学的真正魅力在于理解这些特征之间的相互关系——环境因子如何影响物种分布?物种之间如何相互作用?群落结构如何响应环境变化?这些问题的答案往往隐藏在变量间的相关性或相似性之中。
相关性与相似性分析是揭示这些生态关系的重要统计工具。本章将带领大家从描述生态系统特征转向理解生态系统关系,这是生态学研究从现象描述到规律发现的关键跨越。对于生态学专业人才生而言,掌握这些分析方法不仅能够提升研究能力,更重要的是培养一种关系思维——学会从相互联系的角度来理解复杂的生态系统。
为什么生态学专业的学生需要学习相关性与相似性?首先,生态系统的本质是一个由无数相互关联的组分构成的复杂网络。从微观的基因表达到宏观的物种分布,从短期的种群动态到长期的气候变化响应,相关性分析为我们提供了量化这些关系的数学语言。例如,通过相关性分析,我们可以确定温度变化与物种丰富度之间的关系强度,或者评估不同环境因子对群落结构的相对重要性。
其次,相似性分析在生态学中具有广泛的应用价值。当我们研究不同群落的物种组成时,需要量化它们之间的相似程度;当我们分析功能性状的协变模式时,需要评估性状间的相似性关系;当我们构建生态网络时,需要基于相似性来识别物种间的相互作用。相似性分析不仅帮助我们理解生态系统的结构特征,还为保护生物学中的优先区识别、生态恢复中的参考系统选择提供了科学依据。
本章的内容安排遵循从基础到应用、从简单到复杂的学习路径。我们将首先介绍相关性统计的基础知识,包括Pearson相关系数、Spearman秩相关、Kendall’s \(\tau\)等常用方法。随后,我们将深入探讨更复杂的相关性概念,如偏相关分析、距离相关和互信息。
自相关分析是本章的另一个重要组成部分,它专门处理具有时间或空间依赖性的生态数据。时间自相关分析帮助我们理解生态过程的时间动态,空间自相关分析则揭示了生态现象的空间格局。此外,我们还将介绍系统发育相关性分析,帮助我们理解性状的系统发育保守性和生态适应机制。
相似性与距离度量构成了本章的后半部分内容。我们将系统介绍常用的相似性系数和距离度量方法,探讨功能性状间相关性的生态学意义,以及经济型谱理论在理解植物功能策略中的应用。
种内相关性和种间相关性分析将帮助我们理解生物个体和物种间的空间分布模式和相互作用关系。最后,群落相似性分析将整合前面学到的各种方法,全面揭示群落结构的空间格局和环境梯度响应。
学习相关性与相似性分析不仅是为了掌握统计工具,更重要的是培养系统思维的能力。在生态学研究中,很少有现象是孤立存在的,理解它们之间的相互关系往往比理解单个现象本身更为重要。通过本章的学习,希望大家能够建立起从关系角度思考生态问题的习惯,为未来的生态学研究和保护实践奠定坚实的统计基础。
5.2 生态变量的线性相关性
在生态学研究中,我们经常需要探索不同变量之间的关系。例如,我们可能想知道:森林中树木的胸径与树高之间是否存在某种关系?降水量与植物多样性之间有何联系?这些问题的答案往往需要通过相关性分析来获得。相关性分析为我们提供了一种量化变量间关系强度和方向的统计工具。
5.2.1 Pearson相关系数:线性关系的度量
假设我们正在研究一片温带森林中树木的胸径与树高的关系。我们测量了50棵树的胸径(cm)和树高(m),想要了解这两个变量之间是否存在线性关系。
Pearson相关系数是统计学中最经典的线性相关性度量方法,由卡尔·皮尔逊于1895年提出。它专门用于量化两个连续变量之间的线性关系强度和方向。其核心思想是通过计算两个变量的协方差与各自标准差的乘积之比来标准化协方差的大小,从而得到一个无量纲的相关系数。
数学定义:对于两个变量\(X\)和\(Y\),Pearson相关系数\(r\)定义为:
\[r = \frac{\sum_{i=1}^{n}(X_i - \bar{X})(Y_i - \bar{Y})}{\sqrt{\sum_{i=1}^{n}(X_i - \bar{X})^2}\sqrt{\sum_{i=1}^{n}(Y_i - \bar{Y})^2}}\]
其中\(n\)是样本量,\(\bar{X}\)和\(\bar{Y}\)分别是\(X\)和\(Y\)的样本均值。
Pearson相关系数的取值范围在-1到1之间。正值表示正相关关系,即当一个变量增加时另一个变量也倾向于增加;负值表示负相关关系,即当一个变量增加时另一个变量倾向于减少;0值则表示两个变量之间不存在线性相关关系。
值得注意的是,Pearson相关系数只能检测线性关系,对于非线性关系可能会给出接近0的值,即使变量间存在强烈的非线性关联。这种方法对异常值比较敏感,且要求数据大致满足正态分布假设。
R代码实现:
# Pearson相关系数示例:树木胸径与树高的关系
set.seed(123)
# 模拟树木数据
n_trees <- 50
dbh <- rnorm(n_trees, mean = 25, sd = 5) # 胸径(cm)
height <- 2 + 0.3 * dbh + rnorm(n_trees, mean = 0, sd = 2) # 树高(m)
# 计算Pearson相关系数
pearson_cor <- cor(dbh, height, method = "pearson")
cat("Pearson相关系数:", round(pearson_cor, 3), "\n")## Pearson相关系数: 0.59# 可视化散点图
plot(dbh, height,
pch = 19, col = "blue",
xlab = "胸径 (cm)", ylab = "树高 (m)",
main = "树木胸径与树高的关系"
)
abline(lm(height ~ dbh), col = "red", lwd = 2)
legend("topleft",
legend = paste("r =", round(pearson_cor, 3)),
bty = "n"
)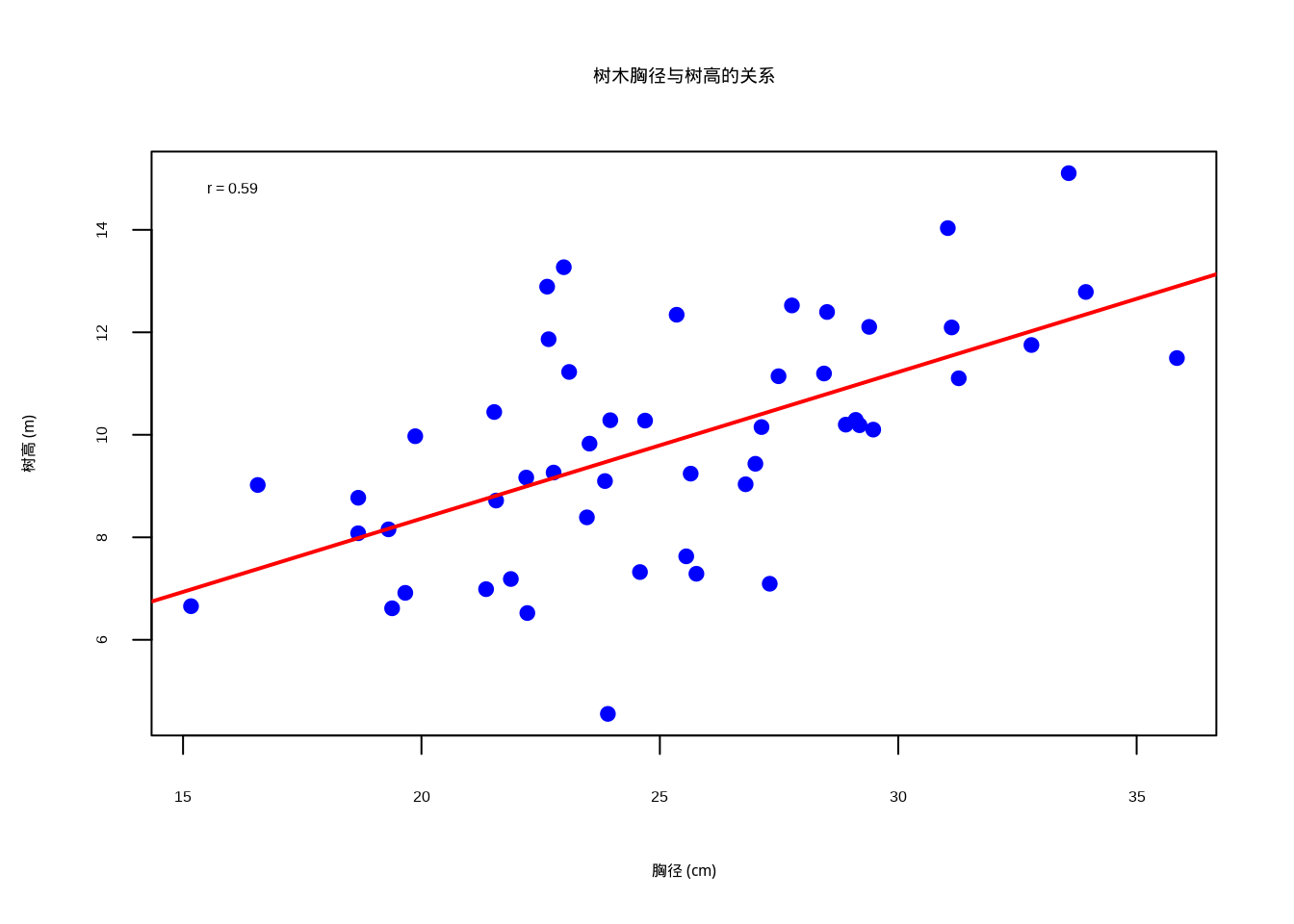
图5.1: 树木胸径与树高的关系散点图,显示线性相关关系。图中蓝色实心圆点表示观测数据,红色实线表示线性回归拟合线,通过颜色和点型的组合确保在彩色显示和黑白打印时都能清晰区分数据点和趋势线
图5.1展示了树木胸径与树高之间的线性相关关系。该散点图使用蓝色实心圆点表示每个观测样本,横轴为树木胸径(单位:厘米),纵轴为树高(单位:米)。图中添加的红色直线是基于线性回归模型lm(height ~ dbh)的拟合线,直观地显示了两个变量间的线性趋势。图例位于左上角,显示计算得到的Pearson相关系数数值,为读者提供了量化的相关强度指标。该可视化清晰地展示了生态学中常见的形态特征相关性,胸径较大的树木通常具有较高的树高,符合树木生长的基本规律。
## 相关性检验结果:
## t统计量:5.068
## p值:6.39e-06
## 95%置信区间:[0.373,0.746]在生态学研究中,Pearson相关系数常用于分析环境梯度与生物响应之间的线性趋势,如温度与物种丰富度的关系、土壤养分与植物生长的关系等。然而,生态学家需要谨慎使用这种方法,因为许多生态关系本质上是非线性的。此外,Pearson相关系数只能反映变量间的统计关联,不能证明因果关系,这在复杂的生态系统中尤为重要。
5.2.2 Spearman秩相关:单调关系的度量
在研究河流水质与底栖动物多样性的关系时,我们发现两者之间的关系可能不是严格的线性关系,但存在明显的单调趋势——水质越好,多样性越高。
Spearman秩相关系数是一种基于秩次的非参数相关性度量方法,由查尔斯·斯皮尔曼于1904年提出。与Pearson相关系数专注于线性关系不同,Spearman相关专门用于检测变量间的单调关系——即当一个变量增加时,另一个变量也倾向于增加(正单调关系)或减少(负单调关系),无论这种关系是线性的还是非线性的。
这种方法的独特之处在于它完全基于变量的秩次信息,而不是原始数值大小,这使得它对异常值具有天然的鲁棒性。在计算Spearman相关系数时,我们首先将每个变量的观测值转换为秩次(即按大小排序后的位置),然后计算这些秩次之间的Pearson相关系数。
数学定义:对于两个变量\(X\)和\(Y\),Spearman相关系数\(\rho\)定义为:
\[\rho = 1 - \frac{6\sum_{i=1}^{n}d_i^2}{n(n^2-1)}\]
其中\(d_i\)是第\(i\)个观测在\(X\)和\(Y\)上的秩次差,\(n\)是样本量。
Spearman相关系数的取值范围在-1到1之间。正值表示正单调关系,负值表示负单调关系,0值表示没有单调关系。值得注意的是,Spearman相关系数度量的是变量间关系的单调性强度,而不是线性强度。这意味着即使两个变量之间存在强烈的非线性单调关系,Spearman相关也能给出接近1或-1的值,而Pearson相关在这种情况下可能给出接近0的值。
R代码实现:
# 加载数据
load("data/spearman.RData")
# 计算Spearman相关系数
spearman_cor <- cor(water_quality, macroinvertebrate_diversity,
method = "spearman")
# 进行相关性检验
spearman_test <- cor.test(water_quality, macroinvertebrate_diversity,
method = "spearman")## Spearman相关系数: 0.991## Spearman检验p值: <2e-16# 可视化关系
plot(water_quality, macroinvertebrate_diversity,
pch = 17, col = "darkgreen",
xlab = "水质指数", ylab = "底栖动物多样性",
main = "河流水质与底栖动物多样性的关系"
)
lines(lowess(water_quality, macroinvertebrate_diversity),
col = "red", lwd = 2, lty = 2)
legend("topleft",
legend = paste("ρ =", round(spearman_cor, 3)),
bty = "n"
)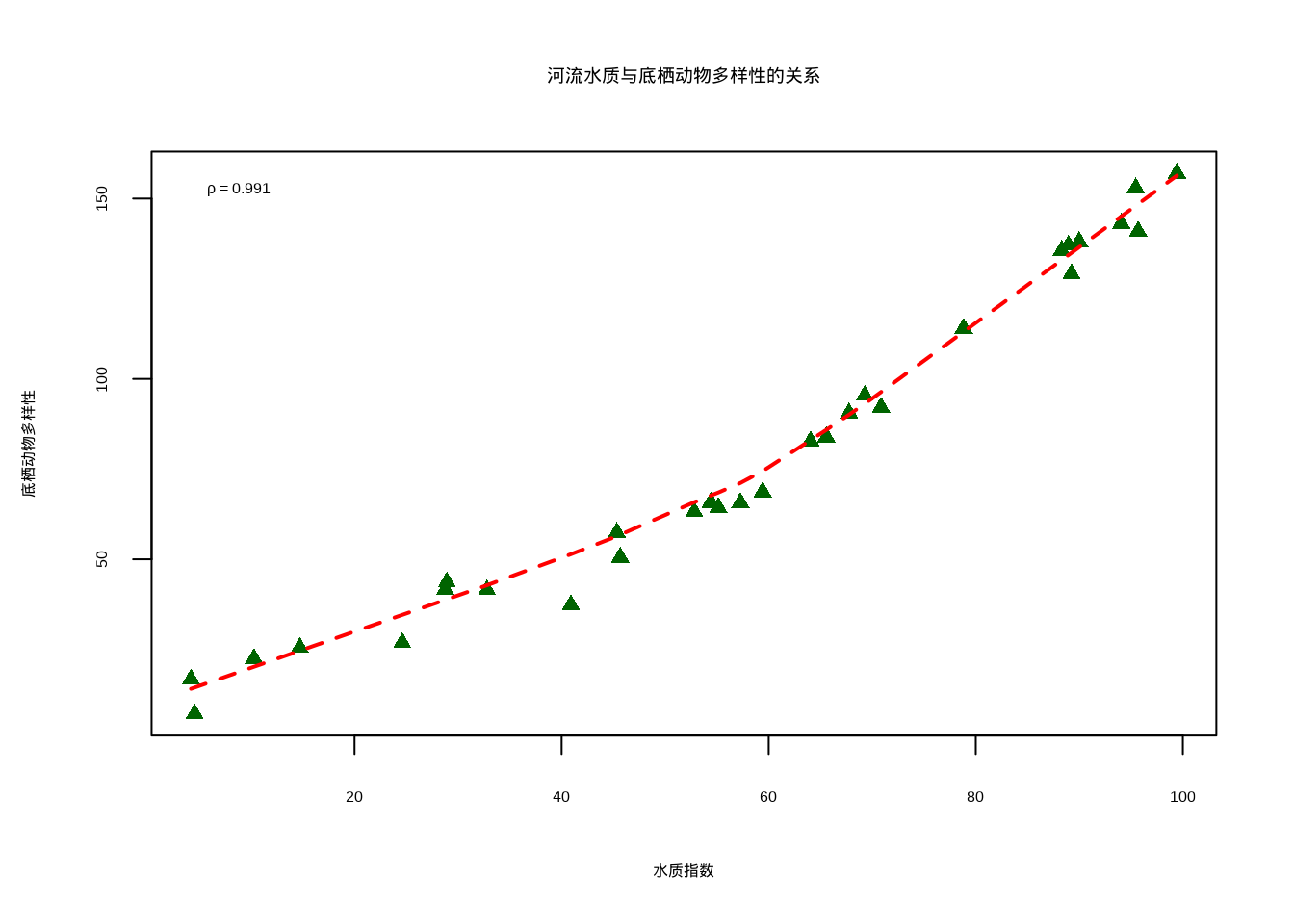
图5.2: 河流水质与底栖动物多样性的关系散点图,显示单调非线性关系。图中深绿色三角形表示观测数据,红色虚线表示局部加权回归拟合线
图5.2展示了河流水质与底栖动物多样性之间的单调非线性关系。该散点图使用深绿色实心圆点表示各观测样本,横轴为水质指数(综合反映水体理化性质),纵轴为底栖动物多样性(反映河流生态系统健康状况)。图中添加的红色曲线是基于局部加权回归平滑(LOWESS)的非参数拟合线,能够更好地捕捉变量间的非线性趋势。图例位于左上角,显示计算得到的Spearman相关系数(ρ),该系数衡量的是变量间的单调相关强度而非线性相关强度。该可视化清晰地展示了水质改善与底栖动物多样性增加之间的正相关关系,体现了Spearman相关在处理生态学中常见非线性关系时的优势。
在生态学研究中,这种特性使得Spearman相关特别适用于分析等级数据、存在异常值的数据、或者分布未知的数据。例如,在分析环境梯度对物种分布的影响时,许多生态响应关系本质上是单调但非线性的,如物种丰富度随海拔或纬度的变化、生物量随养分浓度的变化等。此外,Spearman相关对数据的分布形式没有严格要求,不要求变量满足正态分布假设,这使其在处理生态学中常见的偏态分布数据时具有明显优势。然而,生态学家需要注意,Spearman相关只能检测单调关系,对于非单调的复杂关系(如U型关系、周期性关系)仍然无法有效识别。
5.2.3 Kendall’s \(\tau\):基于一致对的比例
在研究鸟类迁徙时间与气温变化的关系时,我们想要一个对异常值不敏感的相关性度量,因为个别极端天气事件可能影响整体趋势的判断。
Kendall’s \(\tau\)(tau)是另一种基于秩次的非参数相关性度量方法,由英国统计学家莫里斯·肯德尔于1938年提出。与Spearman相关类似,Kendall’s \(\tau\)也用于度量变量间的单调关系,但其计算原理和统计性质有所不同。Kendall’s \(\tau\)的核心思想是基于数据对的一致性来评估变量间的关系强度。具体而言,它考察所有可能的数据对(共\(\frac{1}{2}n(n-1)\)对),统计其中一致对和不一致对的数量。一致对是指两个变量在排序上保持一致,不一致对则是指排序相反的数据对。
数学定义:对于两个变量\(X\)和\(Y\),Kendall’s \(\tau\)定义为:
\[\tau = \frac{(一致对的数量) - (不一致对的数量)}{\frac{1}{2}n(n-1)}\]
其中一致对是指当\(X_i < X_j\)时\(Y_i < Y_j\),或者当\(X_i > X_j\)时\(Y_i > Y_j\)的数据对。
Kendall’s \(\tau\)的计算公式反映了这种一致对与不一致对的净比例,其取值范围在-1到1之间,与Pearson和Spearman相关系数相同。
R代码实现:
## Kendall's τ: -0.54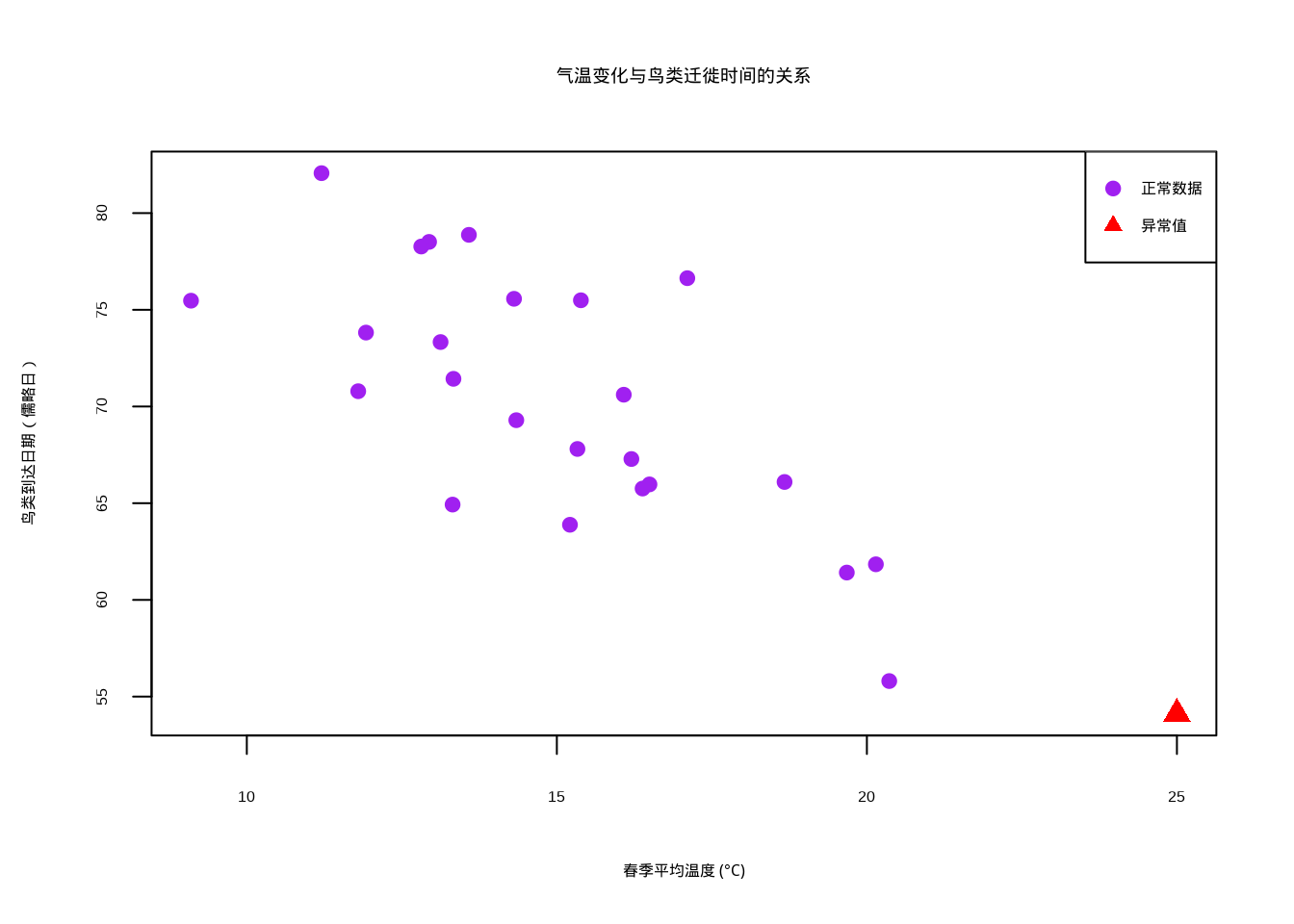
图5.3: 鸟类迁徙时间与气温变化的关系散点图,显示对异常值的稳健性。图中紫色圆点表示正常观测数据,红色三角形标记异常值
图5.3展示了Kendall’s τ在存在异常值情况下的稳健性。该散点图可视化春季平均温度与鸟类迁徙到达日期之间的关系,其中紫色圆点代表正常观测数据,红色三角形标记表示人为添加的异常值(异常温暖的年份)。图中清晰地显示了温度升高与鸟类提前到达之间的负相关趋势,但异常值的存在可能对其他相关性系数产生较大影响。Kendall’s τ基于数据对的排序一致性进行计算,对异常值相对不敏感,因此在生态学时间序列数据分析中具有重要价值,特别是在处理气候变化对物候影响的长期观测数据时,能够提供更加稳健的相关性估计。
## 不同相关性系数的比较:
## Pearson:-0.79
## Spearman:-0.692
## Kendall's τ:-0.54Kendall’s \(\tau\)的一个重要特点是其对异常值的极端稳健性。由于它只关注数据对的相对排序而不关心具体的数值大小,单个异常值对整体估计的影响非常有限。这种特性使得Kendall’s \(\tau\)特别适用于生态学中常见的小样本研究、存在测量误差的数据、或者包含极端观测值的情况。例如,在气候变化对物候影响的研究中,个别异常温暖的年份可能会显著影响Pearson相关系数的估计,但对Kendall’s \(\tau\)的影响相对较小。另一个重要优势是Kendall’s \(\tau\)具有更直观的概率解释:当Kendall’s \(\tau\)等于0.6时,可以理解为任意随机选择的一对观测值,它们在这两个变量上具有一致排序的概率比不一致排序的概率高60%。这种概率解释在生态学应用中往往比相关系数本身更容易理解和传达。此外,Kendall’s \(\tau\)的抽样分布在小样本情况下更加稳定,其标准误的计算也比Spearman相关更为精确。然而,Kendall’s \(\tau\)的计算复杂度较高,对于大样本数据计算时间较长,这是其在实际应用中的一个局限。在生态学研究中,Kendall’s \(\tau\)特别适用于时间序列分析、物种对环境梯度的响应研究、以及需要处理等级数据或存在大量结(ties,即数据中大量出现相同的观测值)的情况。
5.2.4 偏相关分析
在研究森林生产力与降水量的关系时,我们发现温度可能同时影响这两个变量。为了了解降水量对生产力的直接影响,我们需要控制温度的影响。
偏相关分析是一种重要的统计技术,用于在控制其他变量(称为控制变量或协变量)的影响后,评估两个变量之间的净相关关系。在生态学研究中,变量间的关系往往受到多种环境因子的共同影响,简单的双变量相关分析可能无法揭示变量间的真实关系。偏相关分析通过数学方法”剥离”控制变量的影响,使我们能够更准确地评估目标变量间的直接关系。
这种方法的理论基础可以追溯到20世纪初,但直到多元统计方法的发展才在生态学中得到广泛应用。偏相关分析的核心思想是:如果两个变量\(X\)和\(Y\)都与第三个变量\(Z\)相关,那么\(X\)和\(Y\)之间的简单相关可能部分或完全由它们与\(Z\)的共同关系所驱动。通过控制\(Z\)的影响,我们可以得到\(X\)和\(Y\)之间的”纯净”相关,即排除了\(Z\)的混淆效应后的直接关系。
偏相关系数的计算基于残差分析的思想。具体而言,我们首先通过线性回归分别从\(X\)和\(Y\)中去除\(Z\)的影响,得到两个残差序列,然后计算这两个残差序列之间的相关系数。这个相关系数就是\(X\)和\(Y\)在控制\(Z\)后的偏相关系数。不过目前我们还为涉及回归的知识,因此我们来介绍一种计算上更加简单的方式。
数学定义:对于变量\(X\)、\(Y\)和控制变量\(Z\),\(X\)和\(Y\)在控制\(Z\)后的偏相关系数为:
\[r_{XY.Z} = \frac{r_{XY} - r_{XZ}r_{YZ}}{\sqrt{(1-r_{XZ}^2)(1-r_{YZ}^2)}}\]
其中\(r_{XY}\)、\(r_{XZ}\)、\(r_{YZ}\)分别是相应的Pearson相关系数。
从数学上看,偏相关系数可以理解为在保持\(Z\)不变的情况下,\(X\)和\(Y\)之间的条件相关。有兴趣的同学可以自行证明一下,该定义与上述提到的残差定义方法,其实是等价的。
R代码实现:
## 降水量与生产力的简单相关系数: 0.33| precipitation | temperature | productivity | |
|---|---|---|---|
| precipitation | 1.000 | -0.223 | 0.389 |
| temperature | -0.223 | 1.000 | 0.666 |
| productivity | 0.389 | 0.666 | 1.000 |
##
## 控制温度后,降水量与生产力的偏相关系数: 0.389在生态学应用中,偏相关分析具有极其重要的价值。例如,在研究森林生产力与降水量的关系时,温度可能同时影响这两个变量——温度较高时通常降水量也较多,同时温度本身也直接影响植物的光合作用效率。如果不控制温度的影响,我们可能会高估降水量对生产力的直接作用。偏相关分析能够帮助我们识别这种”伪相关”或”间接相关”,从而更准确地理解生态系统的内在机制。此外,偏相关分析在生态网络构建、物种相互作用分析、环境因子筛选等复杂生态学问题中都有广泛应用。然而,生态学家需要注意,偏相关分析仍然基于线性关系的假设,且要求控制变量与目标变量之间的关系大致满足线性模型的前提条件。在高度非线性的生态系统中,偏相关分析的结果需要谨慎解释。
5.3 生态变量的非线性相关
生态系统中许多关系都是非线性的,如物种-面积关系、剂量-响应关系、种群增长模型等。传统的线性相关方法往往无法充分描述这些复杂模式。非线性关系度量包括后面将要介绍的距离相关、互信息等方法,它们不依赖于线性假设,能够捕捉各种复杂的关系模式。在生态学研究中,非线性关系比线性关系更为普遍,因为生态系统中的许多过程都涉及阈值效应、饱和效应、最优区间和反馈机制等非线性动态。例如,物种-面积关系通常呈现幂律形式,种群增长遵循逻辑斯蒂曲线,功能性状间的权衡关系可能呈现U型或S型模式,物种对环境梯度的响应往往存在最优区间。这些复杂的非线性模式无法用传统的线性相关方法来充分描述,因此需要专门的非线性关系度量方法。
距离相关和互信息是两种主要的非线性关系度量方法,它们各有特点和适用场景。距离相关基于变量在距离空间中的协方差来度量依赖关系,能够检测任何形式的统计依赖,包括线性和非线性关系。它的一个重要性质是当且仅当两个变量相互独立时,距离相关系数等于零,这使其成为检验变量独立性的有力工具。距离相关对变量的分布形式没有要求,适用于连续变量和混合类型的数据,但在计算复杂度上相对较高,特别是对于大样本数据。
互信息则基于信息论的概念,量化两个变量间共享的信息量。它能够检测任何类型的统计依赖关系,包括线性和非线性关系、单调和非单调关系。互信息的一个重要优势是它对变量的数据类型没有限制,可以处理连续变量、离散变量和分类变量,这使其特别适合生态学中常见的混合数据类型分析。此外,互信息具有清晰的信息论解释,能够提供关于变量间信息共享程度的直观理解。
除了距离相关和互信息,还有其他非线性关系度量方法,如基于核的方法、基于图的方法和基于模型的方法。基于核的方法通过将数据映射到高维特征空间来检测非线性关系,基于图的方法通过构建变量间的图结构来识别依赖关系,基于模型的方法则通过拟合非线性模型来量化关系强度。在生态学实践中,选择哪种非线性关系度量方法需要考虑数据的特征、研究的目的和计算资源的限制。通常建议使用多种方法进行比较,以获得对生态关系更全面和稳健的认识。
5.3.1 距离相关
在研究植物功能性状之间的关系时,我们可能发现某些性状间存在复杂的非线性关系,传统的线性相关方法无法有效捕捉这些模式。
距离相关是一种革命性的非参数相关性度量方法,由统计学家Gábor J. Székely等人于2007年提出,它能够检测任意分布变量间的依赖关系,包括线性和非线性关系。与传统的相关性度量方法不同,距离相关不依赖于变量间的线性或单调关系假设,而是基于变量间距离的协方差来度量相关性。这种方法的独特之处在于它能够检测任何形式的统计依赖关系,只要这种依赖关系在概率意义上是存在的。
距离相关的核心概念是距离协方差和距离方差,这些概念扩展了传统的协方差和方差概念,使其能够捕捉更复杂的依赖模式。距离协方差度量的是两个变量在距离空间中的协同变化程度,而距离方差则度量单个变量在距离空间中的变异程度。
数学定义:对于两个变量\(X\)和\(Y\),距离相关系数定义为:
\[dCor(X,Y) = \frac{dCov(X,Y)}{\sqrt{dVar(X)dVar(Y)}}\]
其中\(dCov\)是距离协方差,\(dVar\)是距离方差。距离协方差就是量化这种”距离同步性”的程度。如果两个变量的距离模式高度同步,距离协方差就大;如果它们的距离模式没有关系,距离协方差就接近0。距离方差则衡量单个变量内部的”距离变异”程度。如果一个变量的所有值都很接近,距离方差就小;如果值之间差异很大,距离方差就大。
距离相关的核心思想很简单:通过比较所有数据点之间的距离模式来检测变量间的依赖关系。想象你有两个变量,比如植物的叶面积和光合速率。如果这两个变量相关,那么当两个植物的叶面积很接近时,它们的光合速率也应该很接近;当两个植物的叶面积差异很大时,它们的光合速率差异也应该很大。为了更直观地理解距离相关的概念,我们可以通过下面的示意图来展示弱距离相关和强距离相关的区别:
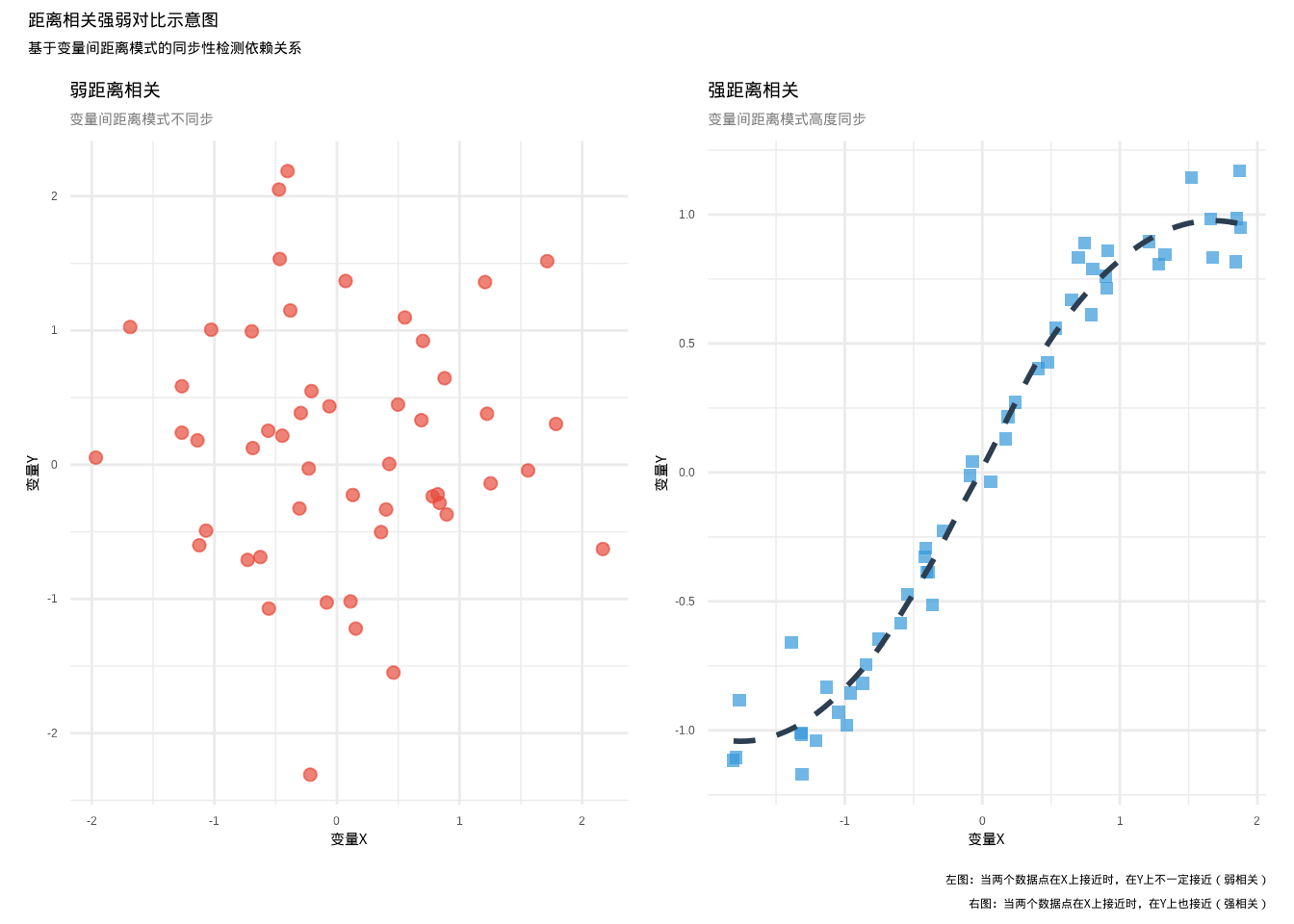
图5.4: 距离相关强弱对比示意图:左图显示弱距离相关(红色圆形散点,变量间距离模式不同步),右图显示强距离相关(蓝色方形散点+虚线趋势线,变量间距离模式高度同步)
上图显示了弱距离相关和强距离相关的区别:
弱距离相关(左图):变量X和Y之间没有明显的依赖关系。当两个数据点在X轴上很接近时,它们在Y轴上的值可能相差很大,反之亦然。这种距离模式的不同步导致距离相关系数接近0。
强距离相关(右图):变量X和Y之间存在明显的非线性依赖关系。当两个数据点在X轴上很接近时,它们在Y轴上的值也很接近;当两个数据点在X轴上相距较远时,它们在Y轴上的值也相距较远。这种距离模式的同步性导致距离相关系数接近1。
距离相关的核心思想正是通过比较所有数据点之间的距离模式来检测变量间的依赖关系。如果两个变量的距离模式高度同步(强相关),那么距离协方差就大;如果它们的距离模式没有关系(弱相关),距离协方差就接近0。
距离相关系数的取值范围在0到1之间,其中0表示变量间完全独立,1表示变量间存在确定的函数关系。值得注意的是,距离相关具有一个非常重要的性质:当且仅当两个变量相互独立时,距离相关系数等于0。这一性质使得距离相关成为检验变量独立性的有力工具。
在生态学研究中,这种特性具有重要的应用价值。许多生态关系本质上是非线性的,如物种-面积关系、功能性状权衡、种群动态模型等,传统的线性相关方法往往无法充分描述这些复杂模式。距离相关能够有效捕捉这些非线性关系,为生态学家提供了更全面的分析工具。例如,在分析植物功能性状间的关系时,我们可能发现叶面积与比叶重之间存在U型关系——中等大小的叶片具有最高的比叶重,而过大或过小的叶片比叶重较低。这种复杂的非线性关系用Pearson或Spearman相关可能无法有效检测,但距离相关能够给出显著的非零值。此外,距离相关对变量的分布形式没有要求,适用于连续变量、离散变量甚至混合类型的数据,这使其在处理生态学中常见的复杂数据类型时具有明显优势。然而,生态学家需要注意,距离相关的计算复杂度较高,对于大样本数据可能需要较长的计算时间,且其统计性质在小样本情况下的表现仍需谨慎评估。
## 距离相关系数: 0.454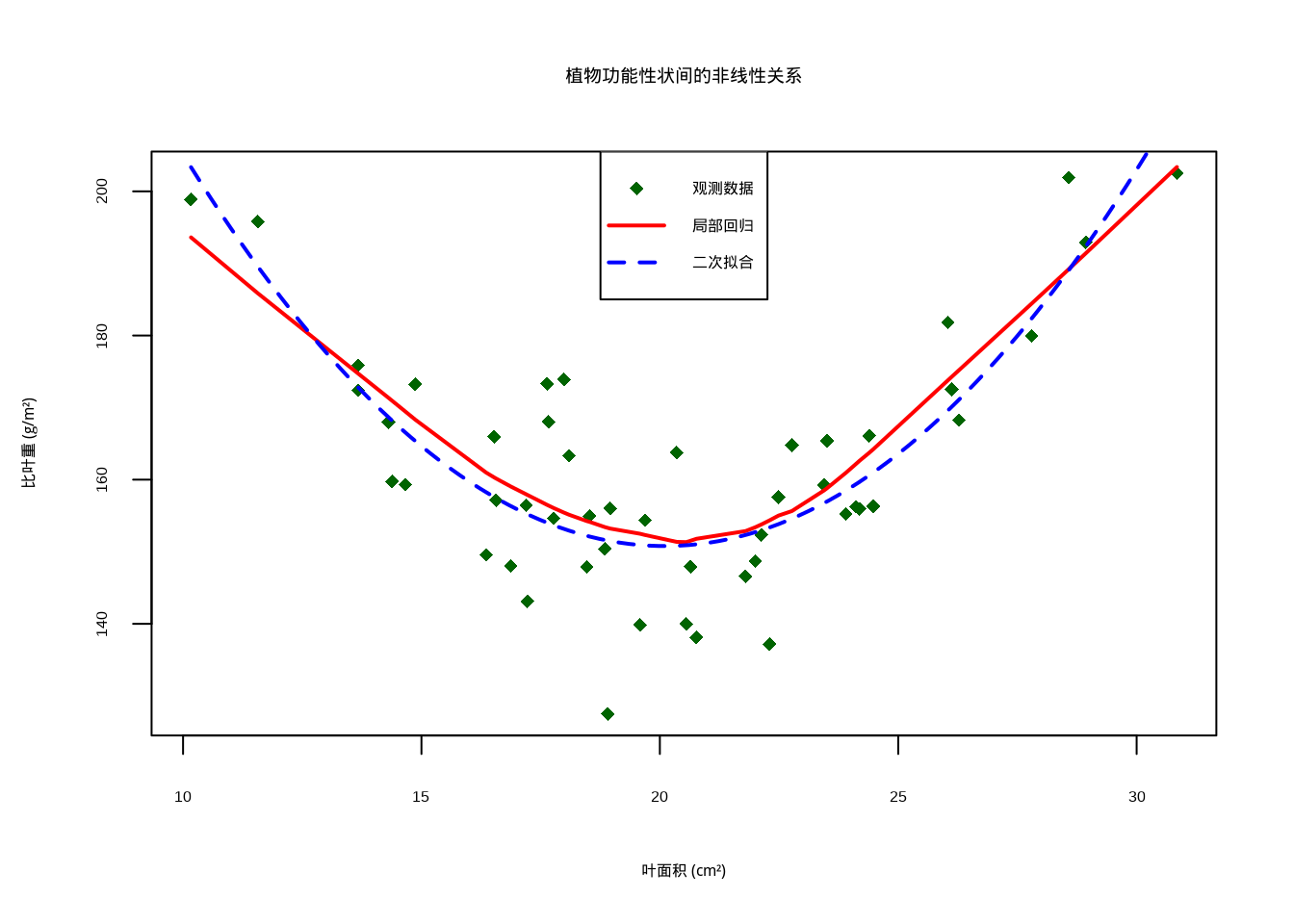
图5.5: 植物功能性状间的非线性关系散点图,显示U型关系。图中深绿色菱形表示观测数据,红色实线表示局部回归拟合曲线,蓝色虚线表示二次多项式拟合曲线
5.3.2 互信息
在生态学中,许多变量间的关系并非简单的线性或单调模式,而是复杂的非线性依赖。例如在研究环境因子对物种分布的联合影响时,我们想要量化多个环境变量共同包含的关于物种分布的信息量。这时,传统的相关性分析方法可能无法充分捕捉这些复杂关系,因此需要更灵活的度量方法。
互信息是基于信息论的依赖关系度量,它量化了两个变量间共享的信息量。与传统的相关性不同,互信息能够捕捉任何类型的统计依赖关系。互信息的概念源于信息论,由克劳德·香农在1948年提出,最初用于通信系统中的信息传输研究,后来被广泛应用于统计分析和机器学习领域。
互信息的核心思想是衡量知道一个变量的值能够减少另一个变量不确定性的程度。从信息论的角度来看,如果两个变量完全独立,那么知道其中一个变量的值不会提供关于另一个变量的任何信息,此时互信息为零;如果两个变量存在完全确定的函数关系,那么知道一个变量的值就能完全确定另一个变量,此时互信息达到最大值。
数学定义:对于两个离散随机变量\(X\)和\(Y\),互信息定义为:
\[I(X;Y) = \sum_{x\in X}\sum_{y\in Y} p(x,y) \log\left(\frac{p(x,y)}{p(x)p(y)}\right)\]
对于连续变量,需要使用积分形式。其中,\(p(x,y)\)表示变量\(X\)和\(Y\)联合概率质量函数,\(p(x)\)和\(p(y)\)分别表示变量\(X\)和\(Y\)的边缘概率质量函数。
互信息的一个重要特性是它对变量间关系的类型没有限制,能够检测线性和非线性关系、单调和非单调关系,甚至是复杂的多模态关系。这种普适性使得互信息在生态学研究中具有独特的优势,因为许多生态关系本质上是非线性和复杂的。例如,在研究环境因子对物种分布的影响时,物种对环境梯度的响应往往不是简单的线性关系,而是存在阈值效应、饱和效应或最优区间等复杂模式。互信息能够有效捕捉这些复杂的依赖关系,而传统的线性相关方法可能会遗漏重要的生态信息。
另一个重要特点是互信息对变量的分布形式没有严格要求,适用于连续变量、离散变量甚至混合类型的数据。在生态学中,我们经常需要处理不同类型的数据,如连续的环境变量(温度、降水)、离散的分类变量(生境类型、土壤类型)和二元变量(物种出现/缺失)。互信息提供了一个统一的框架来处理这些不同类型变量间的依赖关系。
此外,互信息具有对称性,即\(I(X;Y) = I(Y;X)\),这反映了变量间信息共享的相互性。互信息的取值范围从0到正无穷,其中0表示变量间完全独立,正值表示存在信息共享。为了便于解释,有时会将互信息标准化到[0,1]区间,如通过除以变量的熵来得到标准化互信息。在生态学应用中,互信息特别适合用于特征选择、生态网络构建、物种分布建模等需要处理复杂非线性关系的场景。
R代码实现:
# 计算互信息
library(infotheo) # 需要安装:install.packages("infotheo")
load("data/mutinformation.RData")
# 离散化连续变量(互信息计算需要离散数据)
temp_disc <- discretize(temperature, disc = "equalfreq", nbins = 5)
precip_disc <- discretize(precipitation, disc = "equalfreq", nbins = 5)
# 计算互信息
mi_temp <- mutinformation(temp_disc, species_presence)
mi_precip <- mutinformation(precip_disc, species_presence)
mi_joint <- mutinformation(cbind(temp_disc, precip_disc), species_presence)## 互信息分析结果:
## 温度与物种出现的互信息:0.038
## 降水量与物种出现的互信息:0.032
## 温度与降水量联合与物种出现的互信息:0.089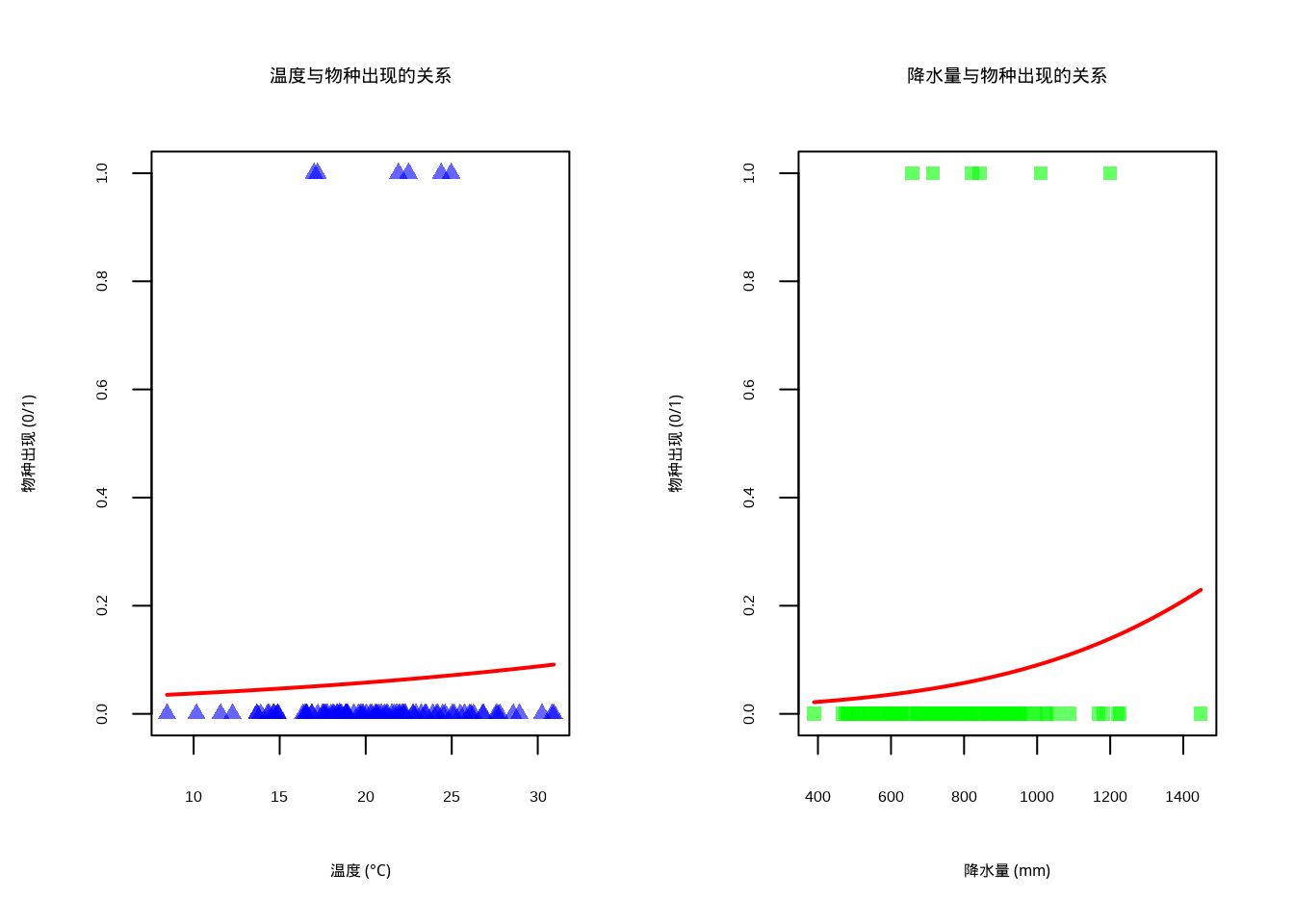
图5.6: 环境因子与物种分布的关系逻辑回归曲线。左图蓝色半透明三角形表示温度观测数据,右图绿色半透明方形表示降水量观测数据,两图中红色实线均表示逻辑回归拟合曲线
图5.6展示了环境因子与物种分布之间的非线性关系,采用逻辑回归曲线可视化二元响应变量(物种出现/不出现)与连续环境因子的关系。该图采用双面板布局,左侧显示温度与物种出现的关系,右侧显示降水量与物种出现的关系。蓝色半透明圆点表示温度观测数据,绿色半透明圆点表示降水量观测数据,红色曲线为逻辑回归拟合线,表示物种出现的概率随环境因子变化的趋势。这种可视化方法能够清晰地展示环境因子对物种分布的非线性影响,特别适用于生态位模型和物种分布预测研究。逻辑回归曲线呈现典型的S型特征,反映了物种对环境因子的响应阈值,为理解物种-环境关系提供了直观的图形表示。
5.4 时间序列的自相关
在前面的章节中,我们讨论了不同变量之间的相关性,如植物的叶面积与光合速率之间的关系。然而,在生态学研究中,许多数据还具有时间或空间依赖性,即同一变量在不同时间点或空间位置上的观测值之间往往存在某种关联。这种”自己与自己”的关联性被称为自相关,它反映了生态过程在时间或空间上的连续性。与变量间的相关性不同,自相关关注的是同一变量内部的时间或空间依赖模式。理解自相关对于正确分析生态数据至关重要,因为忽略自相关可能导致统计推断的错误。
时间自相关的生态学意义:
时间自相关是指同一变量在不同时间点上的观测值之间的相关性,其本质反映了生态系统的记忆效应与连续性。在自然界中,很少有生态过程是完全随机的——今天的种群数量会影响明天的数量,本月的降水量会影响下月的土壤湿度。这种依赖性源于多种生态机制:环境条件的持续性(如干旱或湿润期的延续)、生物种群的世代更迭以及资源利用的累积效应。因此,在诸如种群动态、气候变化与物候变化等在时间尺度上具有内在连续性的生态过程中,时间自相关分析成为我们理解其动态特征与内在规律的关键工具。
时间自相关主要分为三种类型:
正自相关:高值倾向于跟随高值,低值倾向于跟随低值。这反映了生态过程的惯性特征,如种群增长的持续性、气候变化的趋势性。强正自相关表明系统具有较强的记忆效应。
负自相关:高值倾向于跟随低值,低值倾向于跟随高值。这反映了过度补偿或振荡调节机制,如捕食-被捕食系统的周期性波动、资源竞争的反馈调节。
无自相关:观测值之间相互独立,没有明显的时间模式。这通常出现在纯粹的随机过程中,如某些环境噪声或短期天气波动。
理解时间自相关对生态数据分析至关重要。忽略时间自相关会导致统计推断的偏差——低估标准误、增加假阳性风险、错误估计置信区间。在生态学研究中,正确识别和处理时间自相关是获得可靠科学结论的基础。
5.4.1 生态学中的时间自相关实例
为了直观理解不同强度的时间自相关,让我们通过几个典型的生态学实例来观察:
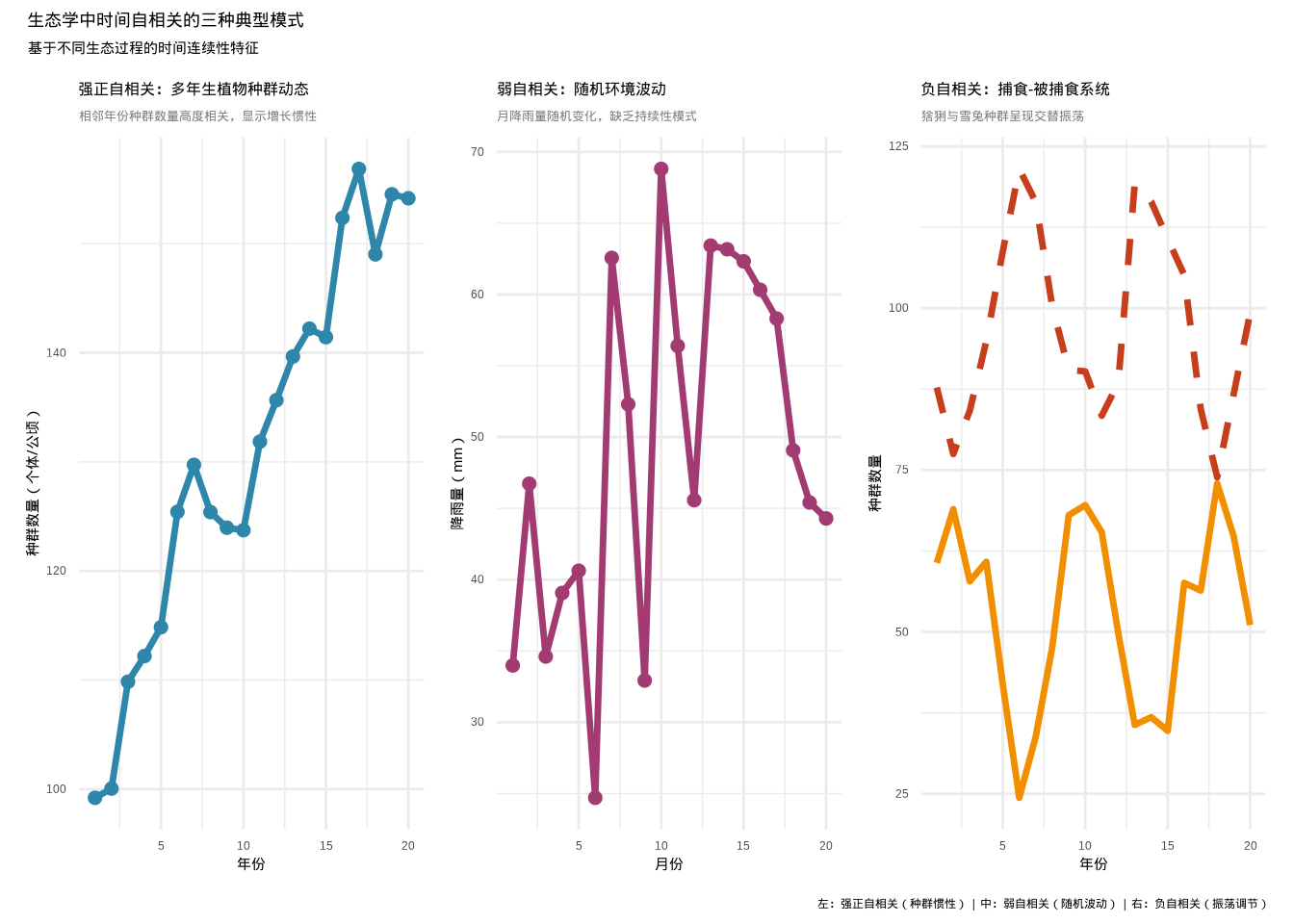
图5.7: 生态学中不同强度时间自相关的实例对比:左图显示强正自相关(蓝色实线表示多年生植物种群动态),中图显示弱自相关(紫色实线表示随机环境波动),右图显示负自相关(橙色实线表示捕食者种群,红色虚线表示被捕食者种群)
上图说明了生态学中不同强度时间自相关的实例:
强正自相关(左图):多年生植物种群动态显示明显的增长趋势,相邻年份的种群数量高度相关。这种模式反映了种群增长的惯性效应——良好的环境条件和繁殖成功会持续影响后续年份的种群规模。
弱自相关(中图):月降雨量的随机波动缺乏明显的连续模式,每个月的降雨量相对独立。这种模式常见于短期环境因素的随机变化,如局部天气系统的快速更替。
负自相关(右图):捕食者(猞猁)和被捕食者(雪兔)种群呈现明显的交替振荡。当一个物种达到高峰时,另一个物种处于低谷,形成了典型的负自相关模式,反映了生态系统中生物相互作用的反馈调节机制。
这些实例清晰地展示了时间自相关在生态学研究中的普遍性和重要性。正确识别这些模式有助于我们理解生态过程的动态机制,并为建立准确的生态模型提供基础。
5.4.2 自相关函数(ACF):时间依赖性的量化
假设我们正在研究一个湖泊中浮游植物生物量的季节变化,我们记录了连续36个月的观测数据,想要了解生物量在不同时间滞后下的自相关性模式。
自相关函数是时间序列分析中最基础的工具之一,用于量化时间序列在不同时间滞后下的自相关性强度。ACF的核心思想是计算时间序列与其自身在不同时间滞后下的相关系数,从而揭示时间序列中的周期性、趋势和记忆效应。对于时间滞后\(k\),自相关系数\(\rho_k\)定义为时间序列\(X_t\)与\(X_{t+k}\)之间的相关系数。ACF的取值范围在-1到1之间,正值表示正自相关(即高值倾向于跟随高值,低值倾向于跟随低值),负值表示负自相关(即高值倾向于跟随低值,低值倾向于跟随高值),0值表示没有自相关。
在生态学研究中,ACF具有重要的应用价值。例如,在分析种群动态时,显著的正自相关可能表明种群具有惯性效应或密度依赖性调节;显著的负自相关可能表明存在过度补偿机制;周期性模式可能反映季节性波动或多年周期。ACF还能帮助识别时间序列中的趋势成分——如果ACF缓慢衰减,表明存在趋势;如果ACF快速衰减到零,表明序列是平稳的。此外,ACF在构建时间序列模型(如ARIMA模型)时也起着关键作用,它为选择合适的模型阶数提供了重要依据。
数学定义:对于时间序列\(\{X_t\}\),滞后\(k\)的自相关系数定义为:
\[\rho_k = \frac{\sum_{t=k+1}^{n}(X_t - \bar{X})(X_{t-k} - \bar{X})}{\sum_{t=1}^{n}(X_t - \bar{X})^2}\]
其中\(n\)是时间序列长度,\(\bar{X}\)是序列的样本均值。
接下来就让我们用ACF这个工具,来看看上面的三个例子中的时间自相关模式。
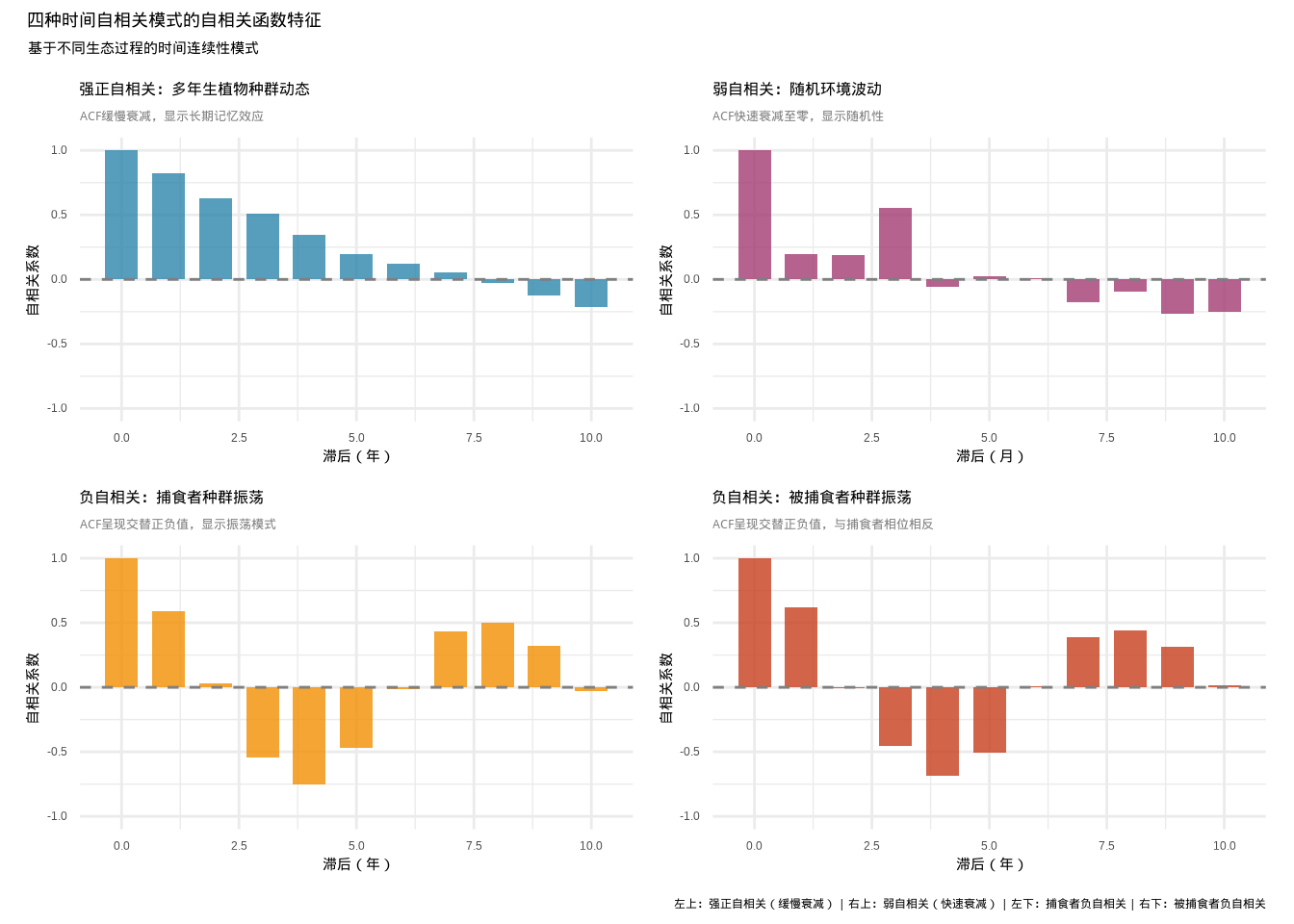
图5.8: 四种时间自相关模式的自相关函数对比:左上蓝色柱状图显示强正自相关的缓慢衰减模式,右上紫色柱状图显示弱自相关的快速衰减模式,左下橙色柱状图显示捕食者种群的负自相关振荡模式,右下红色柱状图显示被捕食者种群的负自相关振荡模式
图5.8系统展示了生态学中常见的四种时间自相关模式的自相关函数特征。该2×2组合图采用ggplot2包创建,每个子图使用不同颜色区分不同的生态过程:蓝色表示强正自相关(多年生植物种群动态),紫色表示弱自相关(随机环境波动),橙色表示捕食者种群的负自相关振荡,红色表示被捕食者种群的负自相关振荡。强正自相关模式显示ACF缓慢衰减,反映了生态系统的长期记忆效应;弱自相关模式显示ACF快速衰减至零,体现了随机环境波动的时间独立性;捕食者与被捕食者种群的负自相关模式呈现交替正负值,直观展示了捕食-被捕食系统的振荡动力学特征。这种可视化方法为生态学家识别时间序列数据的自相关结构提供了有力的工具,有助于理解不同生态过程的时间动态特征。
## 四种时间序列的自相关函数(滞后1)结果:
## 强正自相关序列:0.823
## 弱自相关序列:0.195
## 捕食者序列:0.593
## 被捕食者序列:0.623生态学意义:自相关函数在生态学中广泛应用于检测种群波动的周期性、环境因子的记忆效应、生态过程的持续性等时间动态特征。
5.4.3 偏自相关函数(PACF):直接时间依赖的识别
偏自相关函数是时间序列分析中的另一个重要工具,它度量了在控制中间时间滞后影响后,时间序列与其自身在特定滞后下的直接相关性。例如,在研究森林年轮宽度的时间序列时,我们想要区分不同时间滞后对当前年轮宽度的直接影响和间接影响。当我们想要了解前年年轮宽度对今年年轮宽度的关系时,需要排除去年年轮宽度这个”中间人”的影响。换句话说,PACF回答的问题是:“在控制了去年年轮宽度的影响后,前年年轮宽度对今年年轮宽度还有没有直接的因果关系?”这种分析帮助我们识别时间序列中真正需要的过去时间点数量,从而为建立准确的自回归模型提供关键依据。
与自相关函数不同,PACF排除了通过中间滞后传递的间接相关性,只保留直接的相关性。这种特性使得PACF在识别时间序列模型的自回归阶数(我们将在第10章中介绍自回归模型,现在仅知道有这样的分析就行)时特别有用。对于滞后\(k\),偏自相关系数\(\phi_{kk}\)可以理解为在回归模型\(X_t = \phi_1 X_{t-1} + \phi_2 X_{t-2} + \cdots + \phi_k X_{t-k} + \epsilon_t\)中,系数\(\phi_k\)的估计值。
PACF的计算通常基于Yule-Walker方程或通过逐步回归方法实现。在生态学时间序列分析中,PACF的主要作用是帮助确定自回归模型的合适阶数。如果PACF在滞后\(p\)之后截尾(即之后的偏自相关系数不再显著),那么\(p\)阶自回归模型可能是合适的。这种截尾模式为构建ARIMA模型提供了重要依据。例如,在分析气候时间序列时,PACF可以帮助识别气候系统的记忆长度;在分析种群动态时,PACF可以揭示密度依赖调节的时间尺度。
为了更直观地理解PACF的应用,我们将在下面的森林年轮宽度示例中演示如何计算和解释PACF(见5.10),并与ACF进行比较(见5.11)。
PACF与ACF的结合使用能够提供对时间序列结构的全面理解。ACF反映了总的相关性(包括直接和间接相关性),而PACF只反映直接相关性。这种区别在生态学应用中非常重要,因为它帮助我们区分生态过程中的直接因果联系和通过中间过程传递的间接联系。例如,在食物网动态中,捕食者与猎物的关系可能通过多个营养级传递,PACF可以帮助识别直接的相互作用关系。
数学定义:偏自相关系数\(\phi_{kk}\)可以通过求解Yule-Walker方程得到:
\[\begin{bmatrix} \rho_0 & \rho_1 & \cdots & \rho_{k-1} \\ \rho_1 & \rho_0 & \cdots & \rho_{k-2} \\ \vdots & \vdots & \ddots & \vdots \\ \rho_{k-1} & \rho_{k-2} & \cdots & \rho_0 \end{bmatrix} \begin{bmatrix} \phi_{k1} \\ \phi_{k2} \\ \vdots \\ \phi_{kk} \end{bmatrix} = \begin{bmatrix} \rho_1 \\ \rho_2 \\ \vdots \\ \rho_k \end{bmatrix}\]
其中:
\(\rho_j\):滞后\(j\)的自相关系数,表示时间序列与其自身在\(j\)个时间单位后的相关性强度。其中\(\rho_0 = 1\)表示时间序列与自身的完全相关。
\(\phi_{kj}\):在\(k\)阶偏自相关模型中,滞后\(j\)的偏自回归系数。这个系数表示在控制了其他滞后项的影响后,滞后\(j\)对当前值的直接影响强度。
\(\phi_{kk}\):滞后\(k\)的偏自相关系数,这是PACF的核心输出。它表示在排除了滞后1到\(k-1\)的所有中间影响后,滞后\(k\)对当前值的直接相关性。
矩阵左侧的Toeplitz矩阵:由自相关系数构成的对称矩阵,反映了时间序列在不同滞后下的相关性结构。
矩阵右侧的向量:包含从滞后1到滞后\(k\)的自相关系数,表示我们想要解释的总相关性模式。
这个方程组通过求解偏自回归系数\(\phi_{kj}\),最终得到我们关心的偏自相关系数\(\phi_{kk}\)。
R代码实现:
接下来我们通过一个森林年轮宽度的具体案例来演示偏自相关函数的应用。这个例子将展示如何:
首先,我们可视化原始的时间序列数据,这有助于直观理解数据的动态特征:
load("data/tree_ring_width.RData")
# 可视化原始时间序列
plot(years, tree_ring_width,
type = "l", lwd = 2, col = "darkgreen",
xlab = "年份", ylab = "年轮宽度 (mm)",
main = "森林年轮宽度的时间序列"
)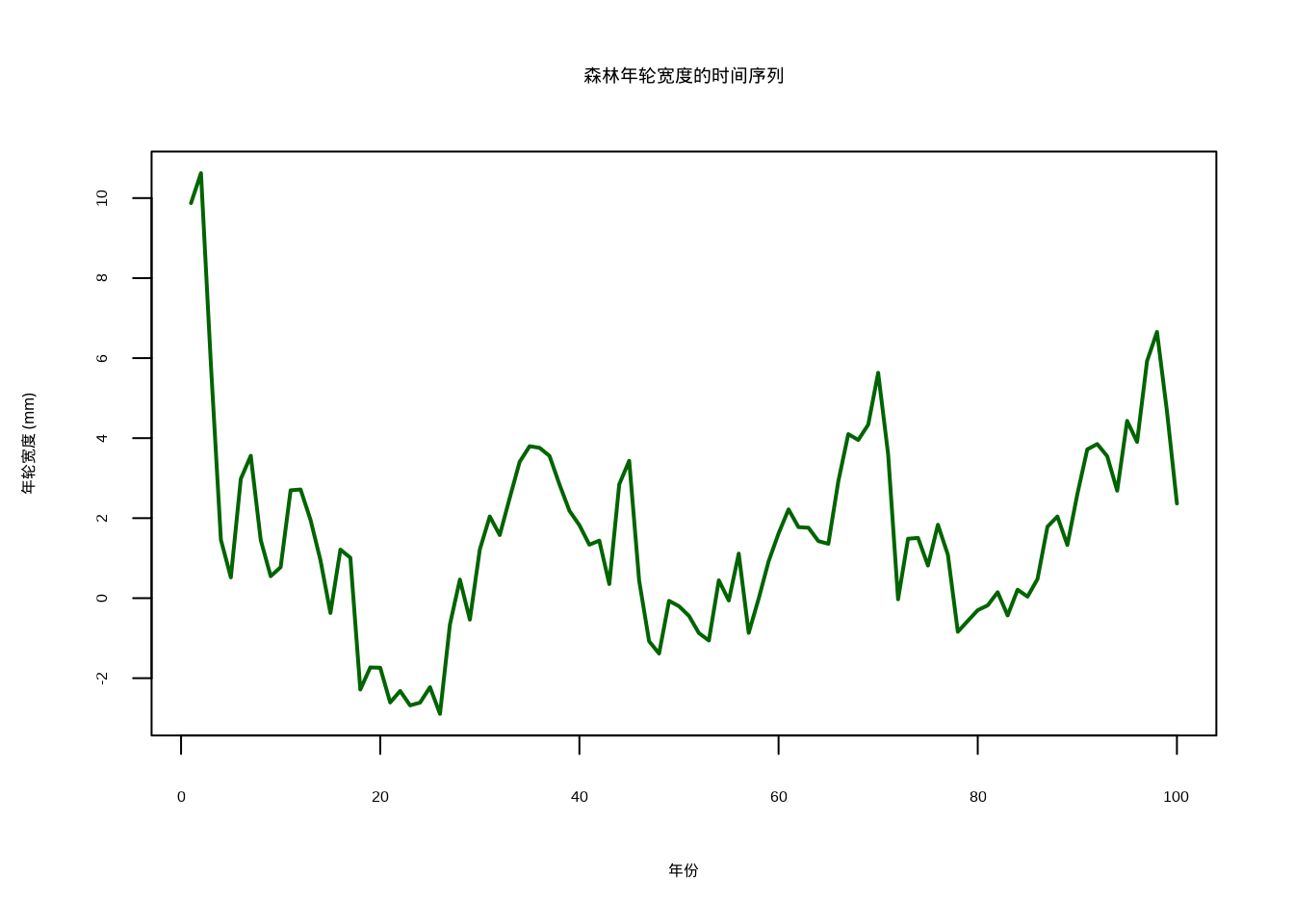
图5.9: 森林年轮宽度的时间序列图
然后,我们计算PACF:
load("data/tree_ring_width.RData")
# 计算偏自相关函数
pacf_result <- pacf(tree_ring_width, lag.max = 15, plot = FALSE)
# 可视化偏自相关函数
plot(pacf_result,
main = "森林年轮宽度的偏自相关函数",
xlab = "滞后(年)", ylab = "偏自相关系数"
)
abline(h = 0, lty = 2)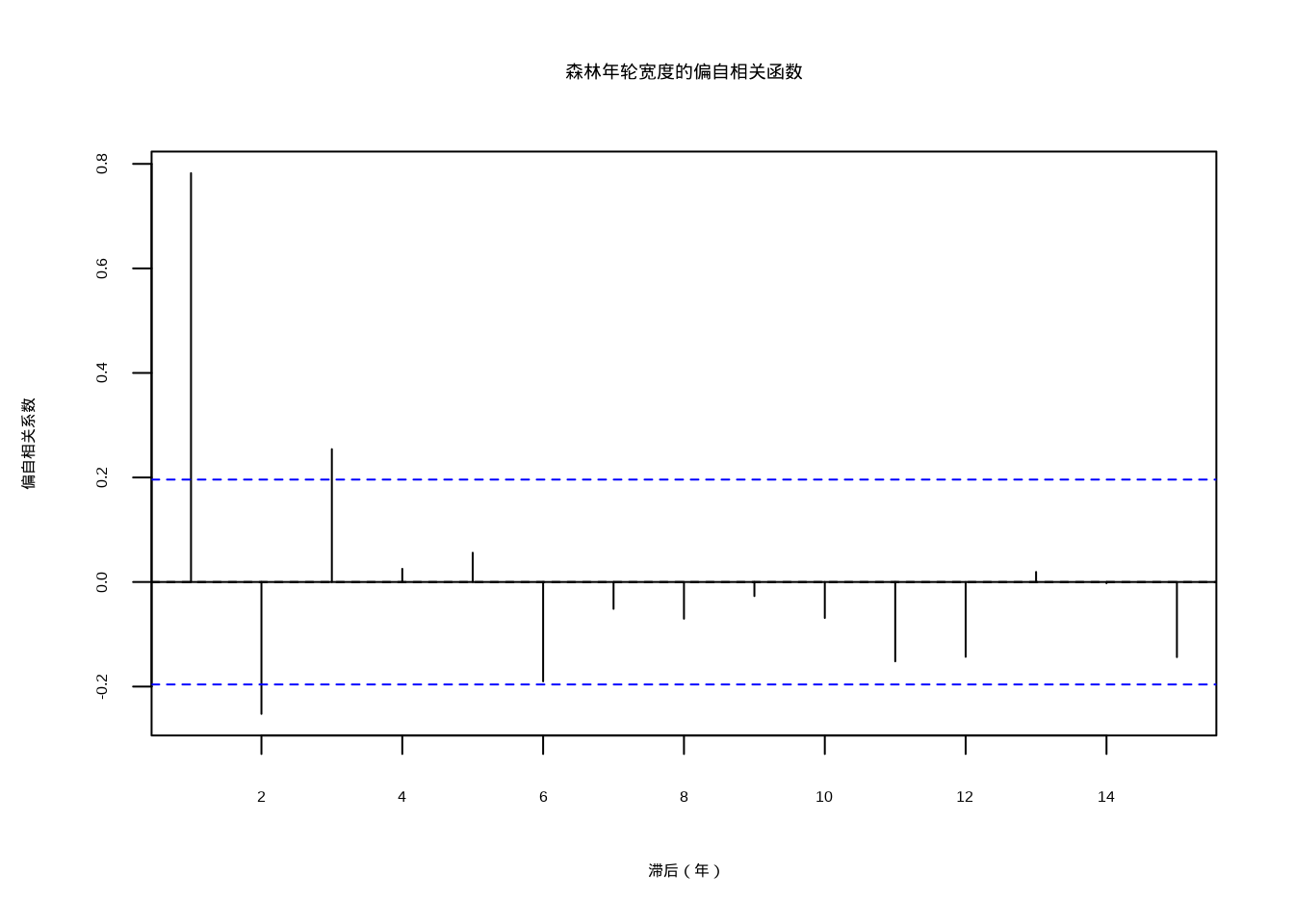
图5.10: 森林年轮宽度的偏自相关函数
## 关键滞后下的偏自相关系数:
## 滞后1年:0.782
## 滞后2年:-0.252
## 滞后3年:0.254现在我们来比较ACF和PACF的差异,这有助于理解两种函数在识别时间序列结构时的不同作用:
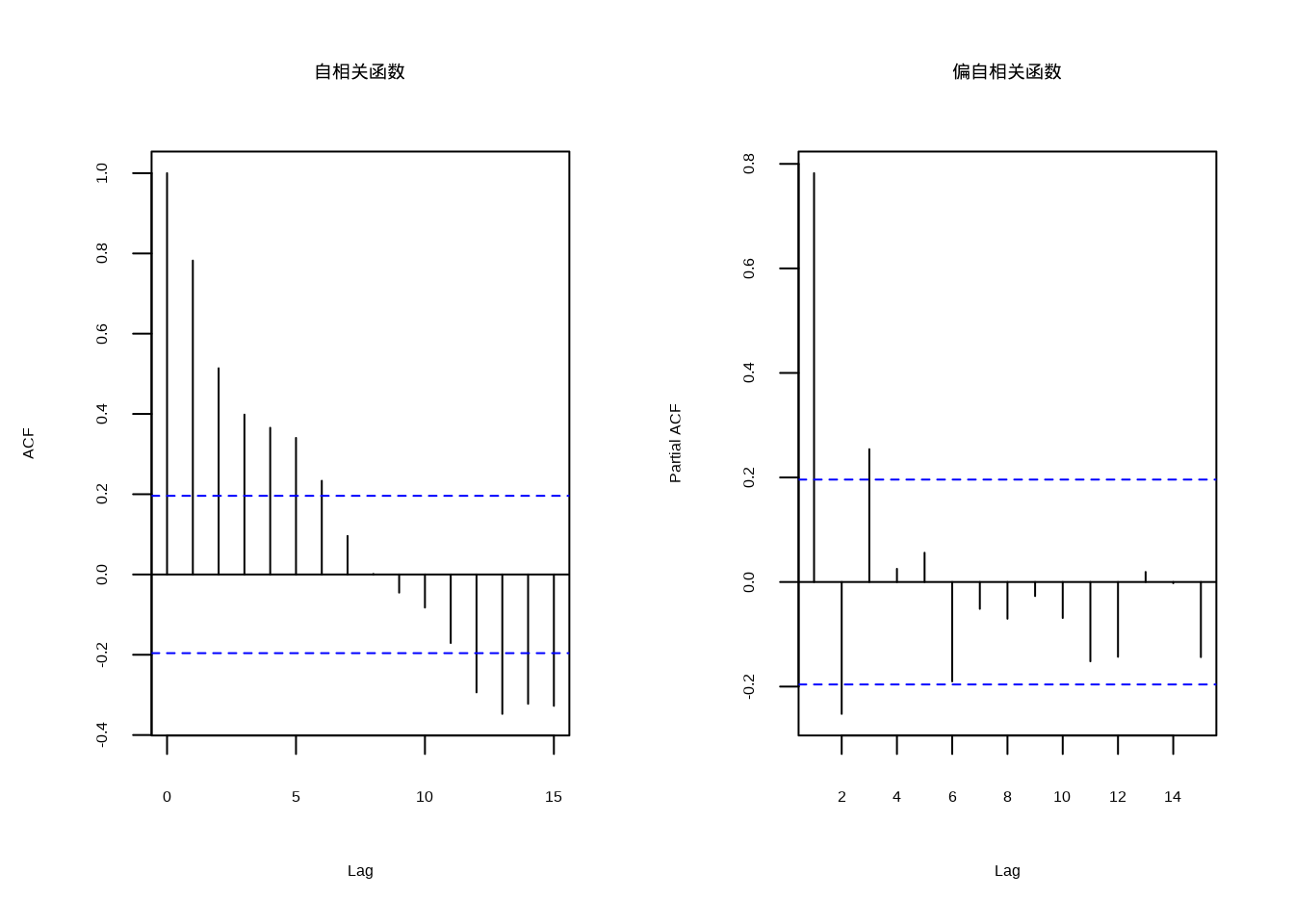
图5.11: 森林年轮宽度的自相关函数与偏自相关函数对比。左图显示自相关函数,右图显示偏自相关函数
图5.11展示了森林年轮宽度时间序列的自相关函数与偏自相关函数对比。该双面板图采用并排布局,左侧为自相关函数图,显示年轮宽度与自身滞后值之间的总相关性;右侧为偏自相关函数图,显示在控制中间滞后影响后,年轮宽度与特定滞后值之间的直接相关性。通过对比两种函数,可以识别时间序列的自回归结构:ACF的缓慢衰减模式表明时间序列具有持续性特征,而PACF的截尾模式则有助于确定自回归模型的合适阶数。在生态学应用中,这种对比分析对于理解森林生长对环境因子的响应模式、识别气候变化的滞后效应以及构建准确的时间序列预测模型具有重要意义。
接下来,我们使用统计方法来确定最优的自回归模型阶数。这在实际生态学研究中非常重要,可以帮助我们选择最合适的模型来描述生态过程:
# 拟合AR模型并确定最优阶数
library(forecast)
# 使用AIC准则选择最优AR模型阶数
best_ar <- auto.arima(tree_ring_width,
max.p = 10, max.q = 0, max.d = 0,
seasonal = FALSE, stepwise = FALSE, approximation = FALSE
)
cat("\n最优AR模型阶数:", best_ar$arma[1], "\n",
"模型系数:\n")##
## 最优AR模型阶数: 3
## 模型系数:## ar1 ar2 ar3 intercept
## 1.1139434 -0.5072173 0.2773914 2.0968099生态学意义:偏自相关函数在生态学中主要用于识别时间序列模型的自回归阶数,帮助理解生态过程的直接时间依赖关系和内在动态机制。通过上面的森林年轮宽度示例(见5.10和5.11),我们可以看到PACF如何帮助识别生态时间序列中的直接时间依赖关系,为构建准确的生态模型提供重要依据。
5.4.4 时间序列平稳性:分析的基础假设
在分析鸟类种群数量的长期监测数据时,我们需要首先检验时间序列的平稳性,因为非平稳时间序列可能导致伪相关和错误的统计推断。
时间序列平稳性是时间序列分析的基本假设,指的是时间序列的统计特性(如均值、方差和自相关结构)不随时间变化。具体而言,严格平稳要求时间序列的任意有限维联合分布都不随时间平移而改变,而弱平稳(也称为二阶平稳)只要求均值恒定、方差有限且自协方差只依赖于时间差而不依赖于具体时间点。在生态学实践中,我们通常关注弱平稳性,因为它更容易检验且对于大多数时间序列分析方法已经足够。
数学定义:弱平稳时间序列满足:
- \(E[X_t] = \mu\)(常数均值)
- \(Var[X_t] = \sigma^2 < \infty\)(有限常数方差)
- \(Cov[X_t, X_{t+k}] = \gamma_k\)(自协方差只依赖于滞后\(k\),不依赖于\(t\))
为了直观理解时间序列平稳性的概念,让我们对比一下平稳和非平稳时间序列的典型特征。
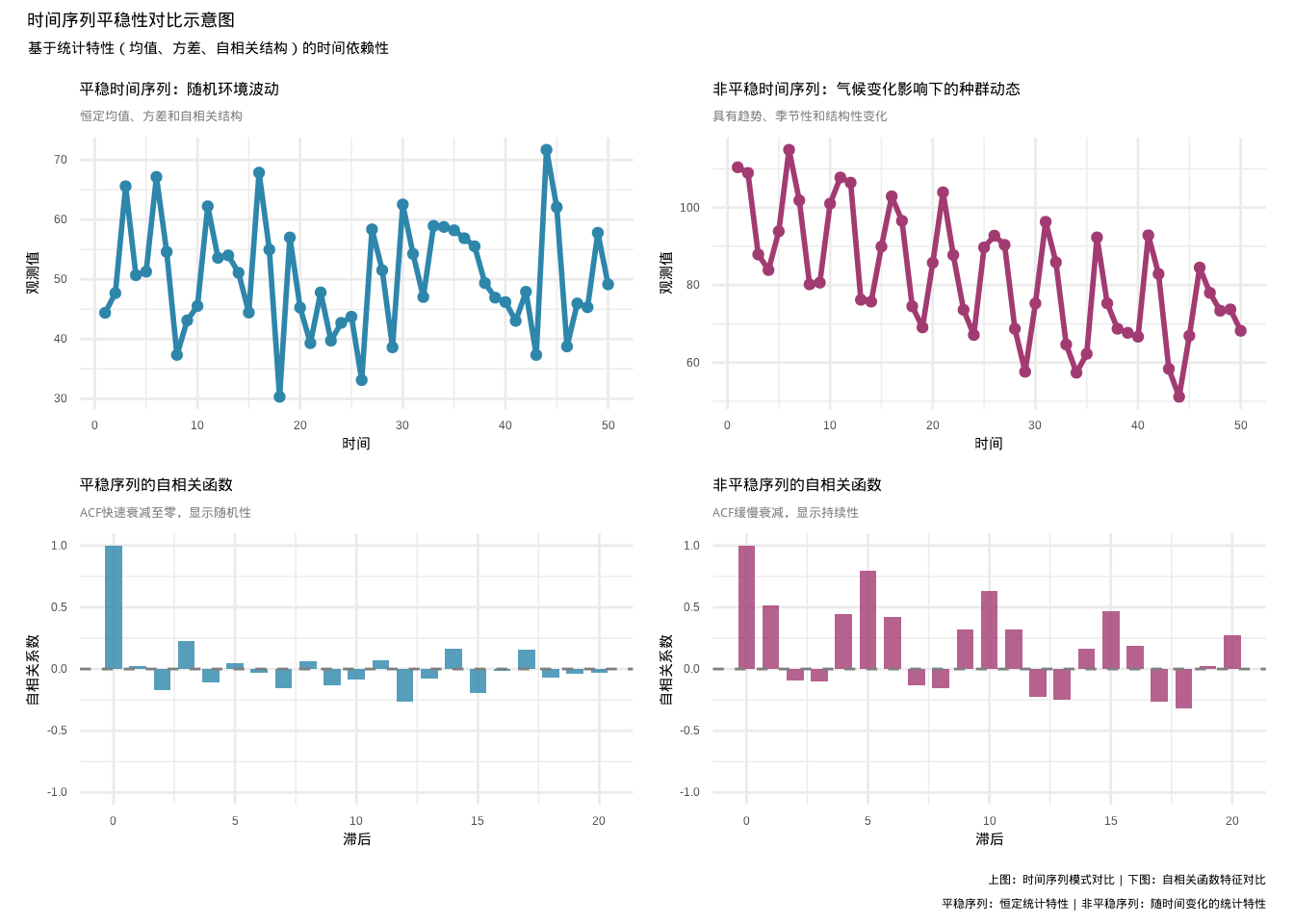
图5.12: 时间序列平稳性对比示意图:左上蓝色线条表示平稳时间序列(恒定统计特性),右上紫色线条表示非平稳时间序列(具有趋势和季节性变化),左下蓝色柱状图显示平稳序列的自相关函数,右下紫色柱状图显示非平稳序列的自相关函数
上面的对比图(见5.12)清晰地展示了平稳时间序列和非平稳时间序列在统计特性上的根本差异,这对于理解时间序列分析的基本假设至关重要。
在平稳时间序列的左侧部分,我们可以看到随机环境波动(如月降雨量)显示典型的平稳特征。时间序列图显示序列围绕一个固定的水平线(约50个单位)波动,既没有明显的上升或下降趋势,也没有系统性模式,观测值之间相互独立。这种恒定均值和恒定方差的特性正是平稳序列的核心特征。自相关函数图进一步证实了平稳性,自相关系数在滞后1之后迅速衰减到接近零,表明除了自身相关外,其他滞后的相关系数都不显著,序列缺乏持续性,当前观测值对未来的预测价值有限。
相比之下,非平稳时间序列的右侧部分展现了完全不同的特征。气候变化影响下的鸟类种群动态显示明显的非平稳性,时间序列图中可见明显的下降趋势,从约100单位下降到约60单位,反映了种群数量的长期变化。同时序列还表现出周期性的波动模式,显示了年际变化的规律性,随机游走成分更增加了序列的不可预测性和持续性。自相关函数图呈现出缓慢衰减的模式,自相关系数在多个滞后上保持显著正值,显示强烈的持续性和长期记忆效应,当前观测值对未来具有较强的预测价值。然而,这种高自相关主要源于序列中的趋势成分,而非真正的统计依赖。
在生态学研究中,正确识别时间序列的平稳性具有重要的实践意义。对于平稳序列,如随机环境波动,由于其统计特性稳定,适合直接应用经典的时间序列方法,统计推断相对可靠。而对于非平稳序列,如受气候变化影响的种群动态,则需要先进行平稳化处理,如差分、变换等方法,否则可能导致严重的统计问题。趋势相似的序列可能显示虚假的相关关系,模型可能错误地拟合趋势而非真实的生态关系,置信区间和假设检验也可能严重偏离真实情况。通过图示法识别平稳性是最直观的检验方法,为后续的统计分析和生态解释提供基础保障。
平稳性检验在生态学时间序列分析中具有至关重要的意义。许多经典的时间序列方法,如自回归模型、移动平均模型和谱分析,都建立在平稳性假设的基础上。如果时间序列是非平稳的,直接应用这些方法可能导致严重的统计问题,如伪回归(spurious regression)和无效的假设检验。生态学中的许多时间序列都表现出非平稳特征,如长期趋势(气候变化导致的温度上升)、季节性变化(物候的季节性波动)、结构性断点(生态系统突变事件)等。
检验时间序列平稳性的常用方法包括图示法、自相关函数分析、单位根检验(如ADF检验、KPSS检验)等。图示法通过观察时间序列图来识别明显的趋势或季节性模式;自相关函数分析通过检查ACF的衰减模式来判断平稳性——平稳时间序列的ACF应该快速衰减到零,而非平稳时间序列的ACF通常衰减缓慢;单位根检验则提供统计检验来正式判断时间序列是否具有单位根(非平稳的标志)。
ADF检验(Augmented Dickey-Fuller Test)是应用最广泛的单位根检验方法,由David Dickey和Wayne Fuller于1979年提出。ADF检验的核心思想是通过检验时间序列是否具有单位根来判断其平稳性。如果时间序列存在单位根,则说明该序列是非平稳的;如果不存在单位根,则序列是平稳的。
ADF检验的数学基础基于以下回归方程:
\[\Delta y_t = \alpha + \beta t + \gamma y_{t-1} + \sum_{i=1}^{p}\delta_i\Delta y_{t-i} + \epsilon_t\]
其中\(\Delta y_t = y_t - y_{t-1}\)表示一阶差分,\(\alpha\)是常数项,\(\beta t\)是趋势项,\(\gamma y_{t-1}\)是滞后项,\(\sum_{i=1}^{p}\delta_i\Delta y_{t-i}\)是差分滞后项(用于消除自相关),\(\epsilon_t\)是误差项。
ADF检验的原假设\(H_0\)是:\(\gamma = 0\),即时间序列存在单位根(非平稳);备择假设\(H_1\)是:\(\gamma < 0\),即时间序列不存在单位根(平稳)。检验统计量是\(\gamma\)的t统计量,但其分布不是标准的t分布,而是Dickey-Fuller分布。
在实际应用中,ADF检验有三种形式:
- 无常数项无趋势项:\(\Delta y_t = \gamma y_{t-1} + \sum_{i=1}^{p}\delta_i\Delta y_{t-i} + \epsilon_t\)
- 有常数项无趋势项:\(\Delta y_t = \alpha + \gamma y_{t-1} + \sum_{i=1}^{p}\delta_i\Delta y_{t-i} + \epsilon_t\)
- 有常数项有趋势项:\(\Delta y_t = \alpha + \beta t + \gamma y_{t-1} + \sum_{i=1}^{p}\delta_i\Delta y_{t-i} + \epsilon_t\)
选择哪种形式取决于时间序列的特征。通常建议从最复杂的模型(有常数项有趋势项)开始,如果趋势项不显著,则使用较简单的模型。
在生态学研究中,ADF检验具有重要的应用价值。例如,在分析气候变化对种群动态的影响时,ADF检验可以帮助判断种群数量是否具有长期趋势;在研究物候变化时,ADF检验可以检验温度或降水序列的平稳性;在生态系统监测中,ADF检验为构建准确的时间序列模型提供了基础。
需要注意的是,ADF检验对滞后阶数\(p\)的选择比较敏感。滞后阶数过小可能导致残差自相关,滞后阶数过大则会降低检验功效。常用的选择方法包括信息准则(AIC、BIC)或基于自相关函数的经验法则。此外,ADF检验的功效相对较低,特别是对于接近单位根但实际平稳的时间序列,容易犯第二类错误。
接下来我们就用一个简单的例子来演示时间序列平稳性的检验和处理。我们将使用鸟类种群数量监测数据(50年)来演示时间序列平稳性的检验和处理。
首先,我们模拟了一个具有趋势、季节性和随机成分的非平稳时间序列(图5.13),该序列模拟了鸟类种群在50年间的动态变化。
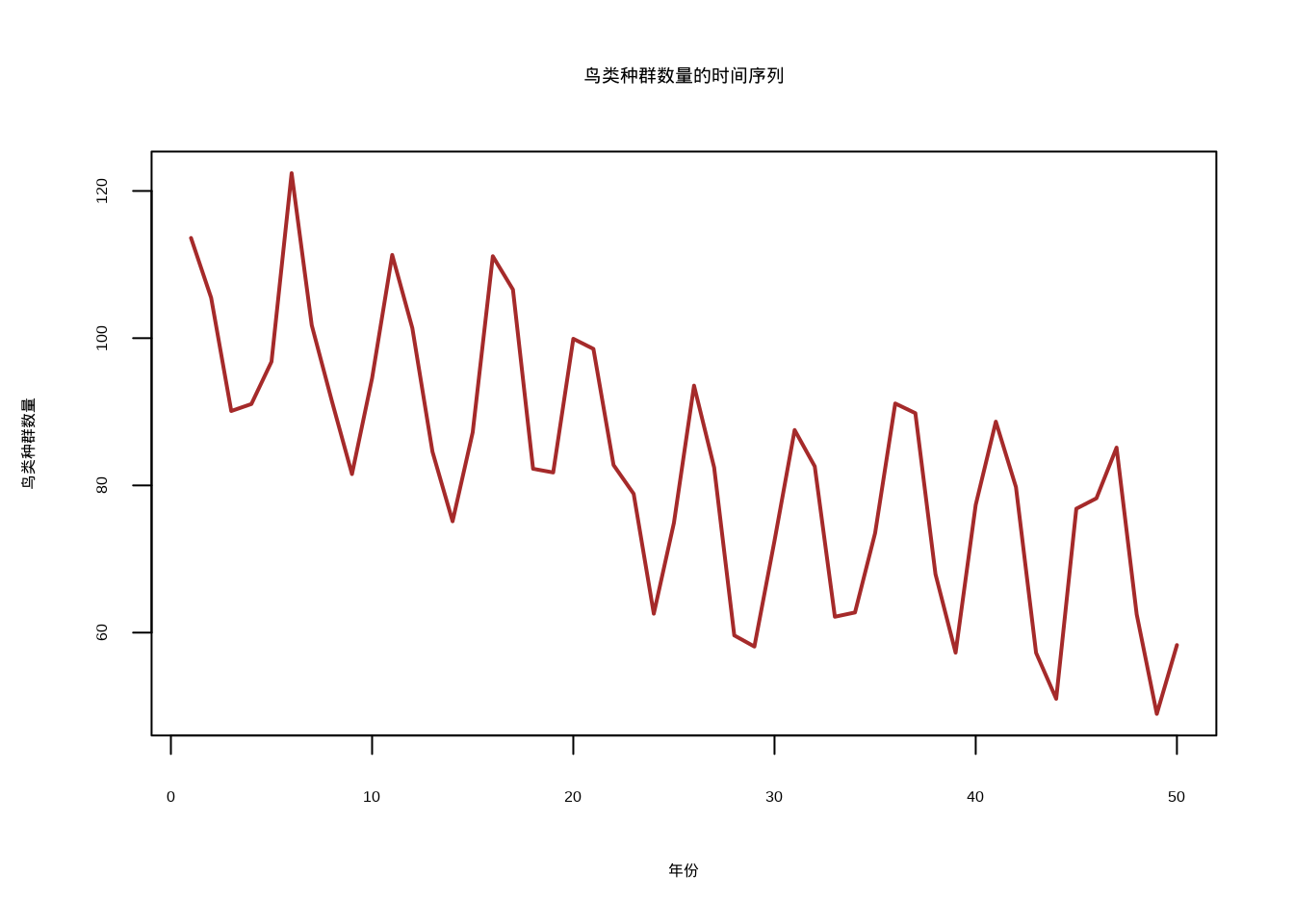
图5.13: 鸟类种群数量的时间序列图,展示了具有趋势、季节性和随机成分的非平稳时间序列
## ADF单位根检验结果:
## 检验统计量:-2.818
## p值:0.246
## 原假设:时间序列有单位根(非平稳)## 结论:不能拒绝原假设,时间序列可能是非平稳的##
## KPSS平稳性检验结果:
## 检验统计量:1.201
## p值:0.01
## 原假设:时间序列是平稳的## 结论:拒绝原假设,时间序列是非平稳的当发现时间序列非平稳时,通常需要进行差分或变换来使其平稳化。一阶差分可以去除线性趋势,季节性差分可以去除季节性模式,而对数变换或Box-Cox变换可以稳定方差。经过这些处理后的平稳时间序列就可以安全地应用各种时间序列分析方法了。在生态学应用中,理解时间序列的平稳性不仅关系到统计方法的正确使用,也帮助我们识别生态系统的长期变化模式和动态特征。
一阶差分是处理非平稳时间序列最常用的方法之一,其数学原理非常简单:对于时间序列 \(X_t\),一阶差分定义为相邻两个时间点的差值,即 \(\nabla X_t = X_t - X_{t-1}\)。这种操作能够有效去除时间序列中的线性趋势,因为线性趋势在差分后会变为常数项。例如,如果一个时间序列包含线性增长趋势 \(X_t = \alpha + \beta t + \epsilon_t\),那么一阶差分后得到 \(\nabla X_t = \beta + (\epsilon_t - \epsilon_{t-1})\),其中 \(\beta\) 是常数,而 \(\epsilon_t - \epsilon_{t-1}\) 通常是平稳的随机扰动项。
在生态学时间序列分析中,一阶差分具有重要的应用价值。许多生态过程,如种群数量变化、气候变化响应、生态系统演替等,往往表现出明显的趋势性特征。通过一阶差分,我们可以将这些趋势从原始数据中分离出来,从而更好地分析数据中的随机波动成分。例如,在研究鸟类种群年际变化时,一阶差分能够帮助我们识别种群增长或下降的速率变化,而不是仅仅关注绝对数量的变化。
需要注意的是,一阶差分虽然能够去除线性趋势,但可能会引入新的问题。差分操作会减少序列的长度(从 \(n\) 个观测值变为 \(n-1\) 个差分值),同时可能放大数据中的噪声成分。此外,如果原始序列包含季节性模式,一阶差分可能不足以完全消除季节性影响,此时需要结合季节性差分或其他方法。在实际应用中,通常需要结合统计检验(如ADF检验)来验证差分后序列的平稳性,确保差分处理达到了预期效果。
接下来我们就用一阶差分来处理上面例子中时间非平稳问题。通过一阶差分处理,我们可以将原始的非平稳序列转换为平稳序列,从而满足时间序列分析的基本假设。
# 如果非平稳,进行差分处理
if (adf_test$p.value >= 0.05) {
cat("\n进行一阶差分处理...\n")
bird_diff <- diff(bird_population)
# 检验差分后序列的平稳性
adf_diff <- adf.test(bird_diff)
cat("差分后序列的ADF检验:\n")
cat("p值:", format.pval(adf_diff$p.value, digits = 3), "\n")
}##
## 进行一阶差分处理...## 差分后序列的ADF检验:
## p值: 0.01# 差分后序列可视化
if (adf_test$p.value >= 0.05) {
plot(years[-1], bird_diff,
type = "l", lwd = 2, col = "blue",
main = "一阶差分后序列", xlab = "年份", ylab = "差分值"
)
}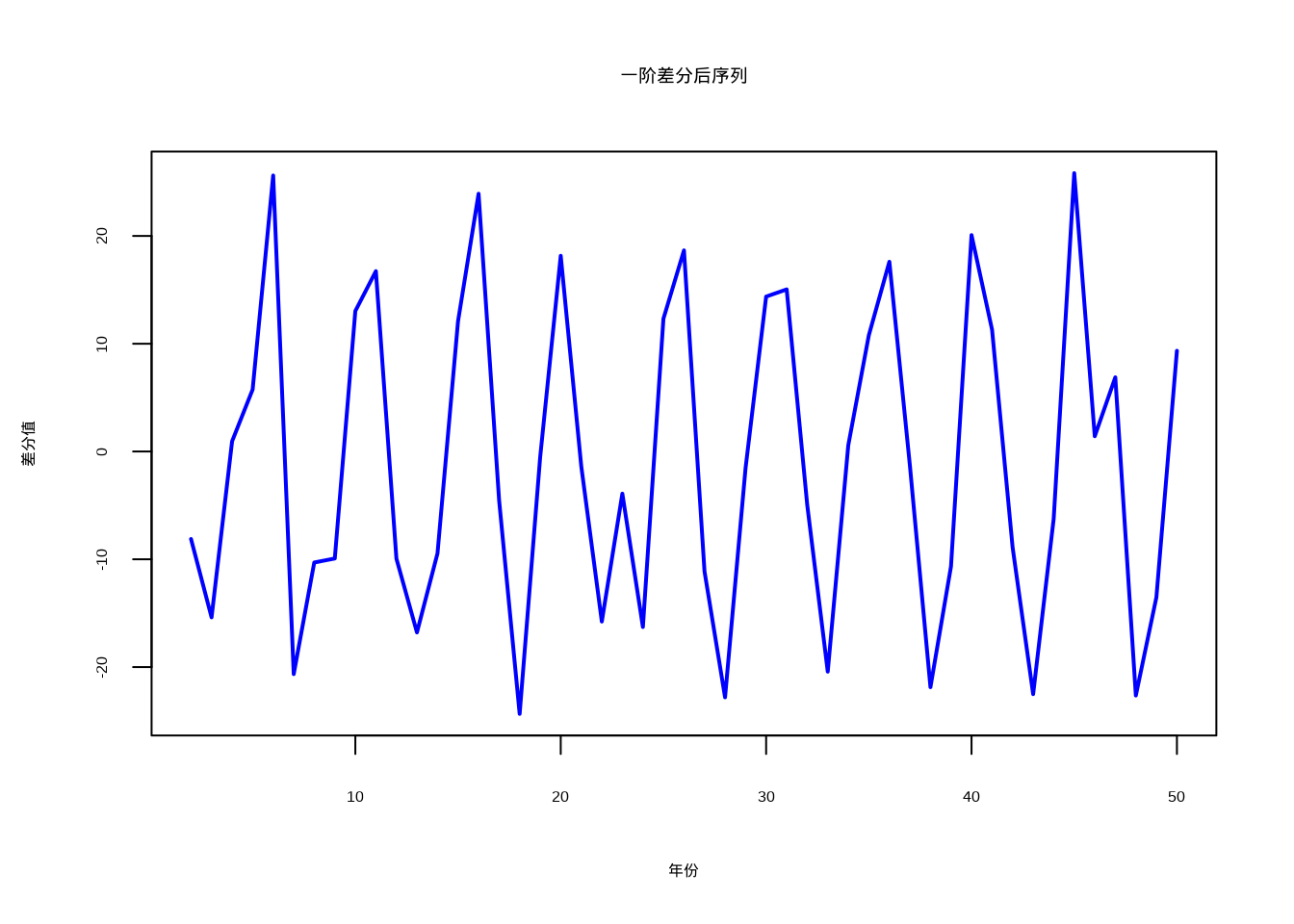
图5.14: 一阶差分后的鸟类种群序列,趋势成分已被去除,主要保留随机波动
经过一阶差分处理后,序列的趋势成分被有效去除,如图5.14所示,差分后的序列主要保留了随机波动成分。
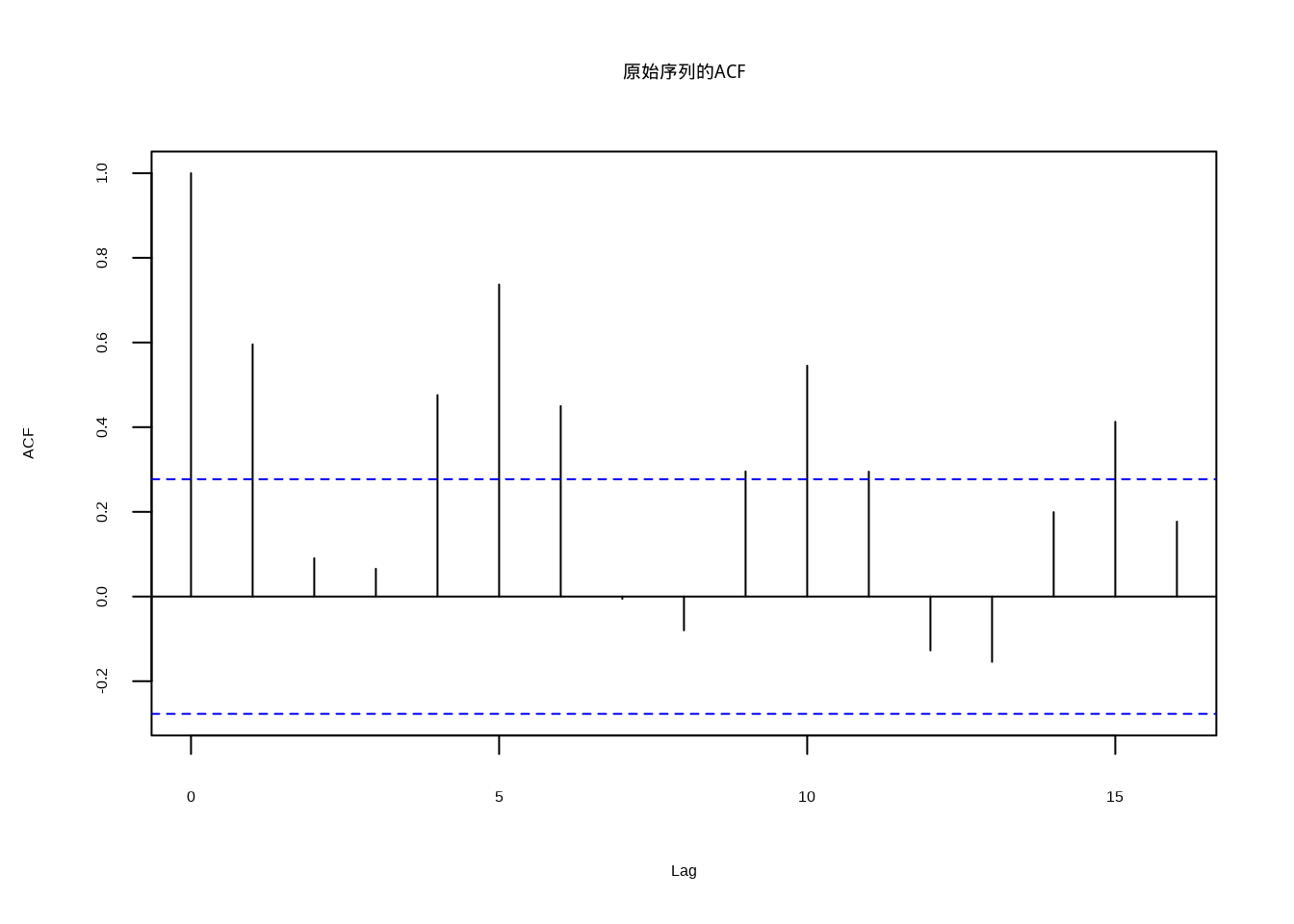
图5.15: 原始序列的自相关函数,显示缓慢衰减的非平稳特征
原始序列的自相关函数(图5.15)显示缓慢衰减的特征,这是非平稳时间序列的典型表现。
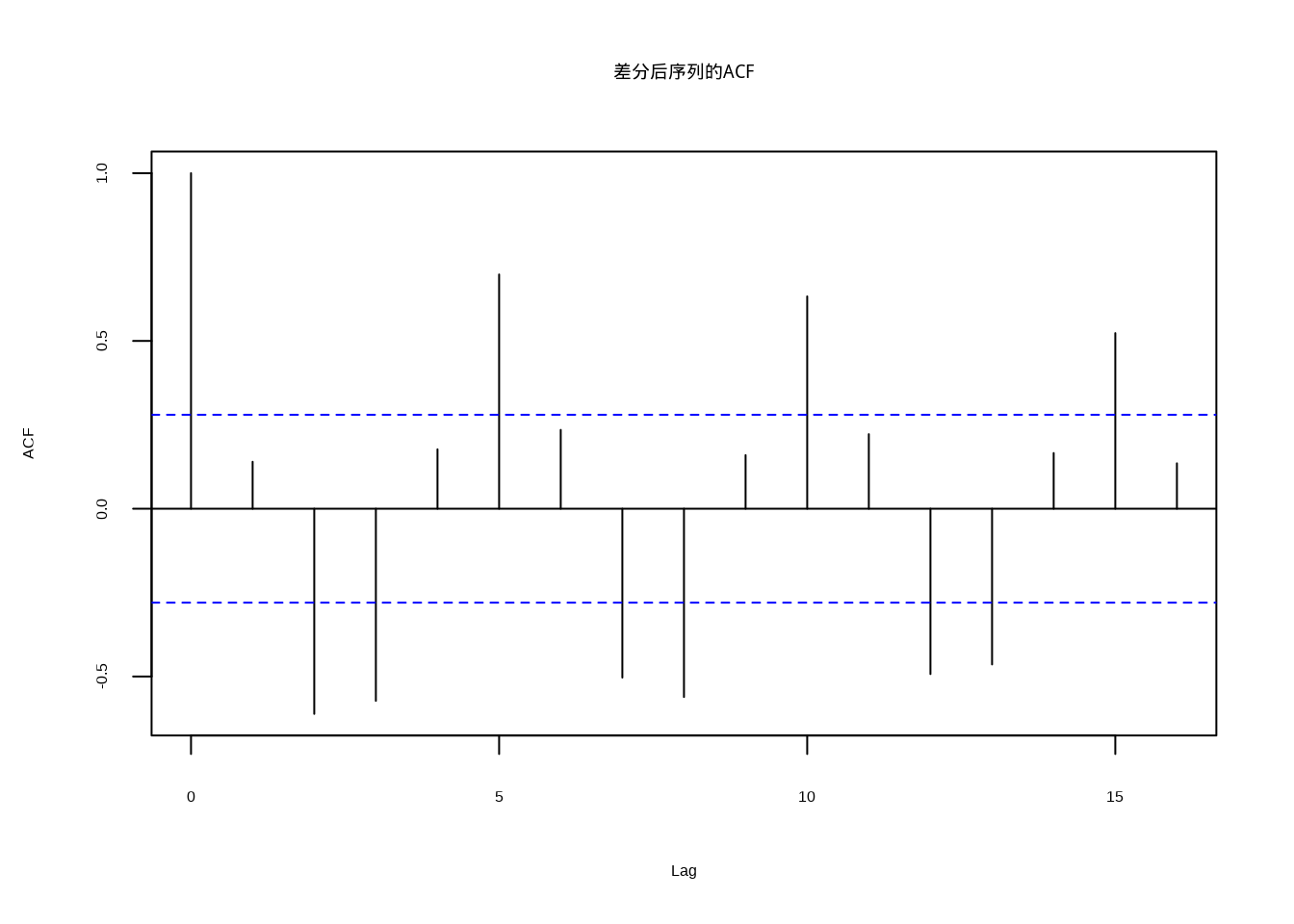
图5.16: 差分后序列的自相关函数,显示快速衰减的平稳特征
差分后序列的自相关函数(图5.16)显示快速衰减的特征,表明序列已经达到平稳状态。
# 分解时间序列(趋势、季节、随机成分)
if (length(bird_population) >= 2 * 12) { # 需要足够的数据点进行季节性分解
ts_data <- ts(bird_population, frequency = 5) # 假设5年周期
decompose_result <- decompose(ts_data)
plot(decompose_result)
}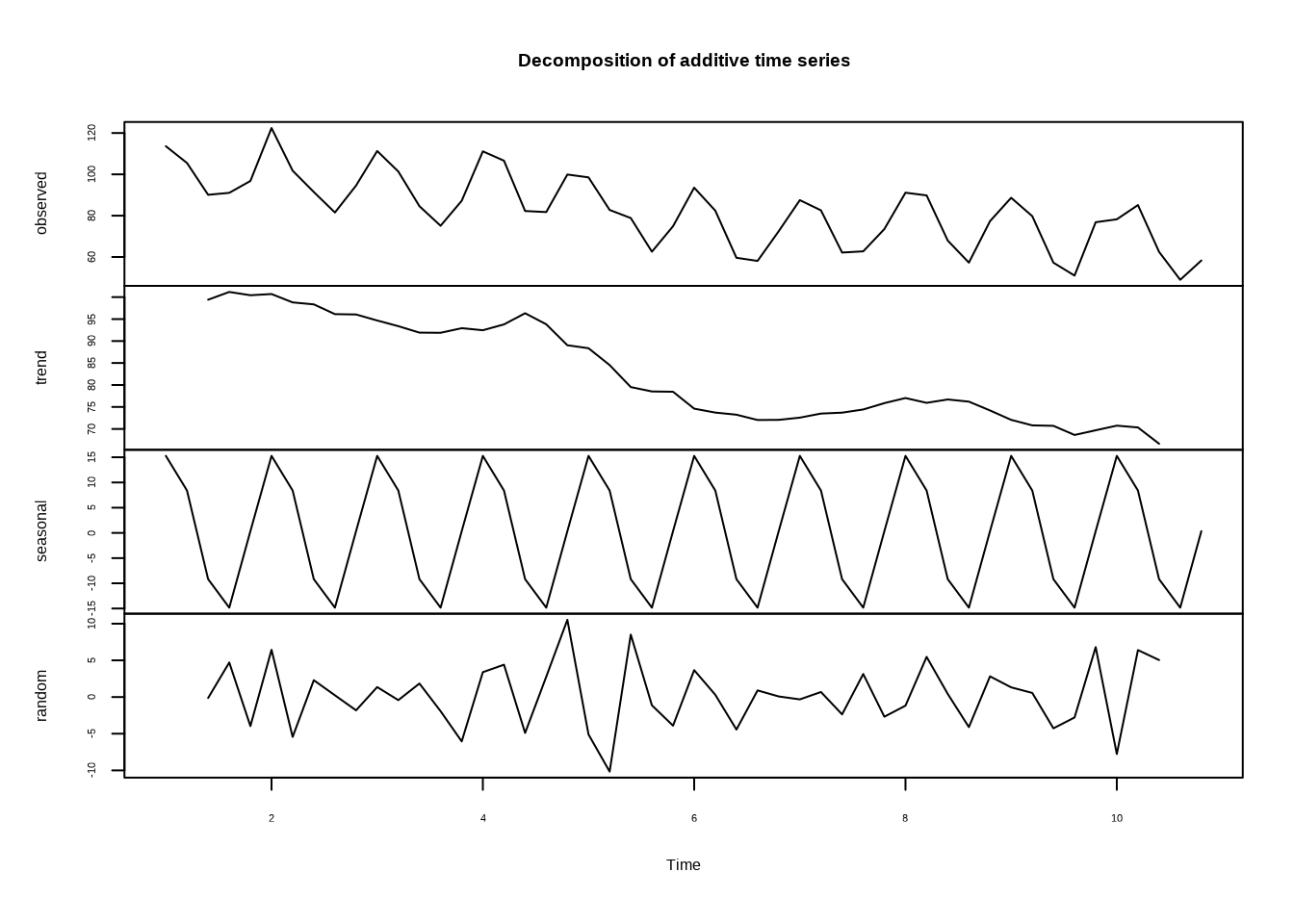
图5.17: 时间序列分解结果,展示趋势、季节性和随机成分的分离
图5.17展示了时间序列分解的结果,将原始序列分离为趋势、季节性和随机成分,帮助我们更好地理解时间序列的内在结构。
5.5 空间格局的自相关
空间自相关是生态统计学中一个富有诗意而又严谨的概念,它描述的是地理空间中相邻位置上的观测值之间那种微妙的相互关联性。这种关联性如同大自然留下的生态指纹,记录着生态过程在空间维度上的记忆和痕迹。在生态学研究中,我们常常发现许多现象都具有显著的空间依赖性:物种分布呈现出的聚集或扩散格局,环境因子如温度、降水、土壤养分在空间上的梯度变化,种群在栖息地中的空间分布模式等,所有这些都蕴含着空间自相关的密码。
图5.18和5.19直观地展示了空间自相关的不同类型和强度。当我们通过图形来直观展示空间自相关时,就如同打开了一扇观察生态空间格局的窗户。有空间自相关的图形呈现出一种”聚集之美”——在空间分布图上,我们能看到相似的值在空间上聚集在一起,形成明显的斑块、梯度或带状分布。比如在物种丰富度的热力图中,高值区域往往聚集在一起,低值区域也形成自己的群落,这种空间上的有序排列正是空间自相关的直观体现。相反,无空间自相关的图形则展现出”随机之舞”的特征——观测值在空间上呈现出完全随机的分布,没有任何明显的空间模式或聚集趋势,就像在空间中随机撒下的种子,彼此之间没有任何空间上的关联性。
空间自相关的强度也能够在图形中直观地展现出来。强空间自相关在图形上表现为清晰的空间格局——斑块边界分明,梯度变化平滑而连续,空间上的相似性表现得十分明显。例如,在图5.18的左下角,我们可以看到强空间自相关的典型表现:清晰的梯度变化和明确的边界。在一片森林中,如果某种树木的分布呈现出强烈的空间自相关,我们在分布图上就能看到明显的聚集中心,周围逐渐过渡到其他物种的分布区域,这种强烈的空间依赖性往往反映了重要的生态过程,如种子传播的限制、环境梯度的强烈影响或种间竞争的显著作用。
而弱空间自相关则呈现出较为模糊的空间趋势——虽然能够观察到一定的空间模式,但这种模式不够清晰,聚集程度较低,空间上的相似性表现得相对微弱。这种情形在生态学中同样具有重要意义,它可能反映了多种生态过程的复杂交织,或者表明所研究的生态现象受到多种因素的共同影响,没有单一的主导空间过程。图5.19中的热力图通过插值方法进一步清晰地展示了这些空间格局的细节。
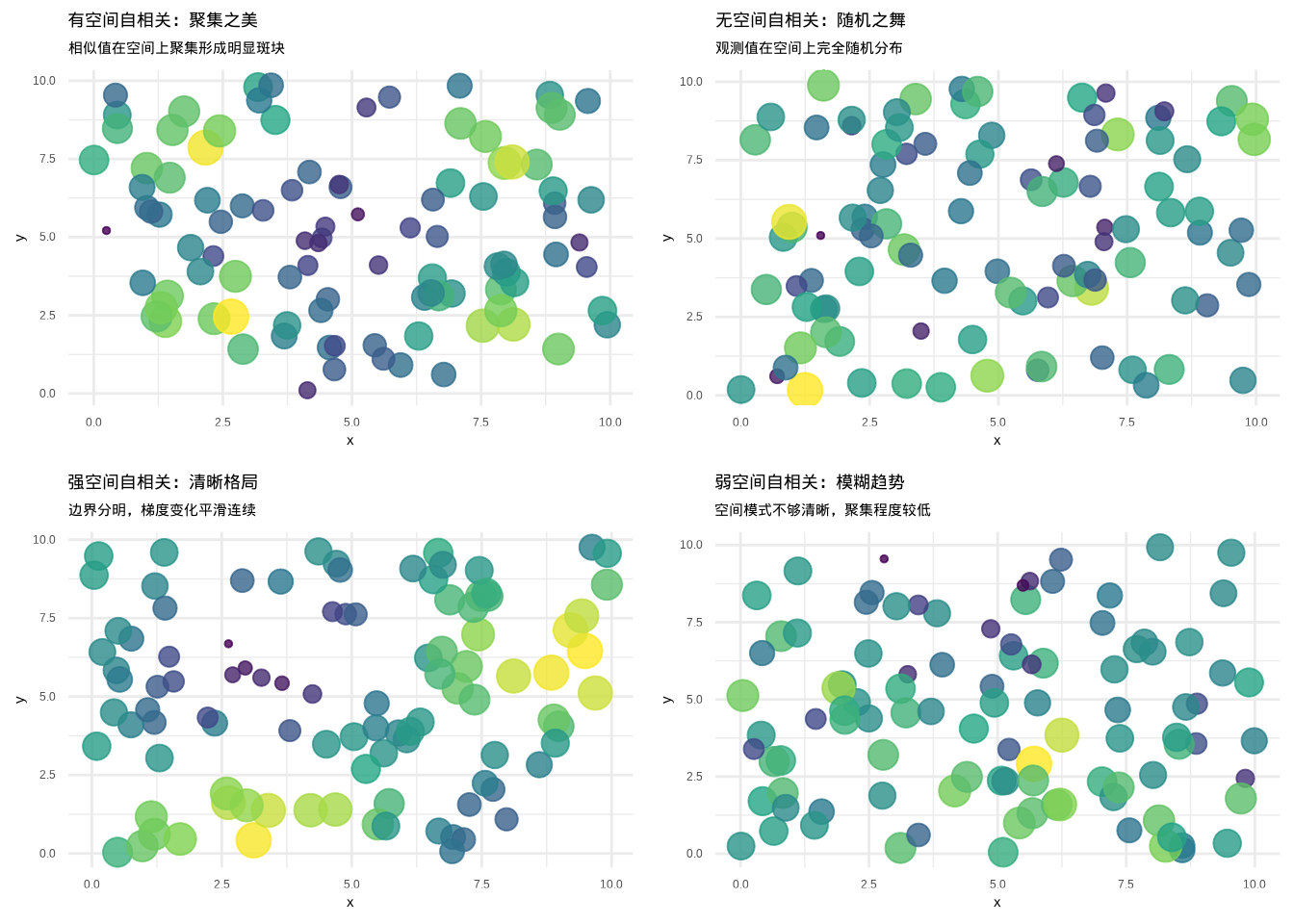
图5.18: 空间自相关模式的直观展示:有空间自相关(左上)、无空间自相关(右上)、强空间自相关(左下)、弱空间自相关(右下)
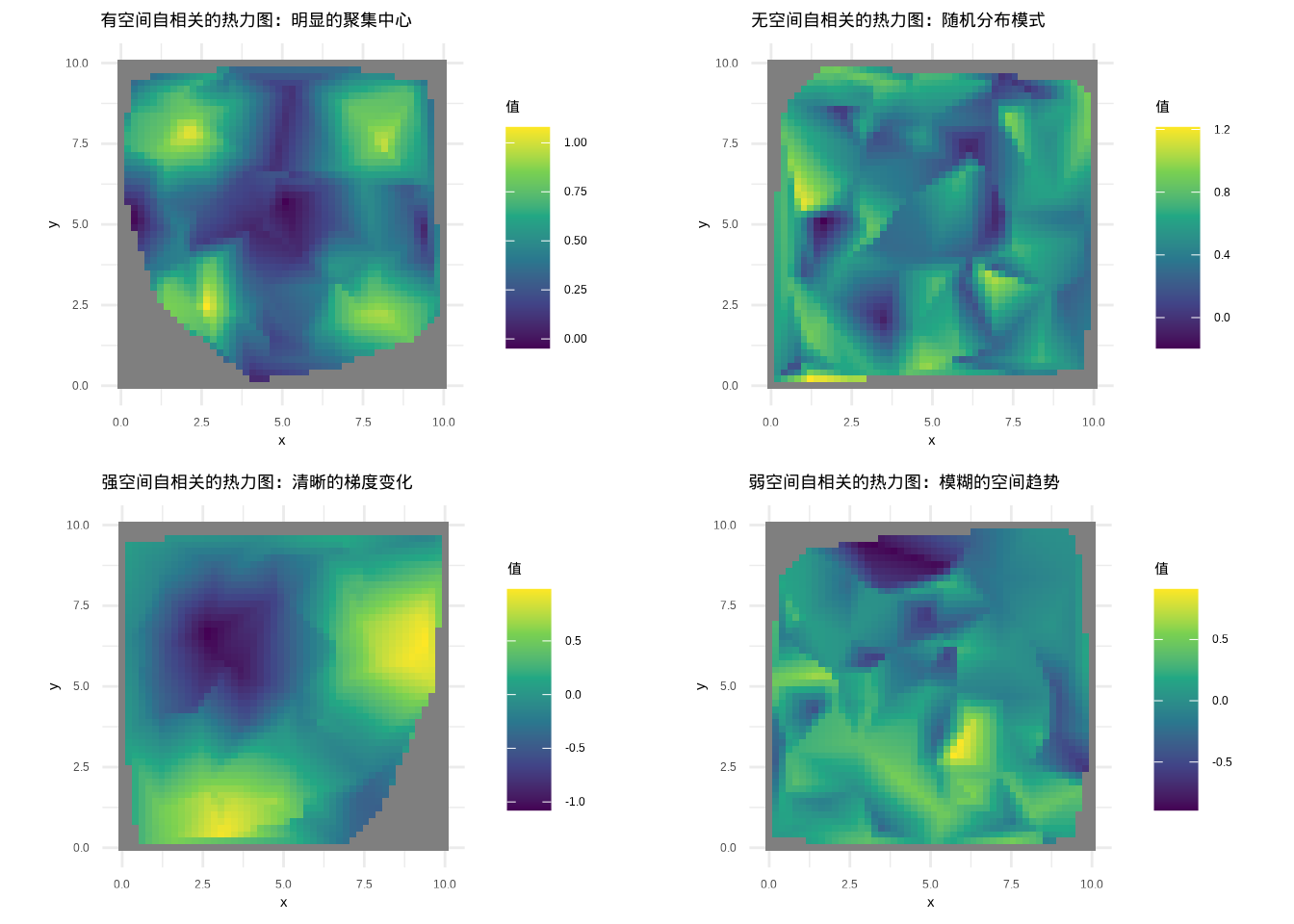
图5.19: 空间自相关的热力图展示:通过插值方法生成的热力图能够更清晰地显示空间格局
通过空间分布图、热力图和等值线图等直观的图形工具,我们能够直接”看到”空间自相关的存在与否及其强度。这些图形就像生态系统的空间肖像,记录着生态过程在空间维度上的印记。当我们观察一片草原的植被覆盖度分布图时,那些绿色的斑块和过渡带不仅美化了图形,更重要的是它们揭示了植被生长的空间依赖性;当我们研究河流水质参数的空间分布时,那些沿着河流流向逐渐变化的色彩梯度,正是空间自相关在水环境中的生动体现。
空间自相关分析因此成为我们理解生态现象空间结构和空间过程的重要工具。它帮助我们解读生态系统的空间语言,识别生态过程的作用尺度,为生态保护、资源管理和环境监测提供科学依据。在这个充满联系和依赖的生态世界中,空间自相关就像一把钥匙,帮助我们打开理解生态空间格局的大门。
5.5.1 变异函数(Variogram):空间依赖性的量化
假设我们正在研究一片草原上植物物种丰富度的空间分布,我们在100个样点上测量了物种数,想要了解物种丰富度在空间上的依赖关系如何随距离变化。
变异函数是地统计学中的核心工具,用于量化空间自相关随距离的变化模式。变异函数描述的是空间变量在特定距离下的半方差,即相同距离的观测点对之间差异的期望值的一半。变异函数的核心思想是:在空间上相近的观测值往往比相距较远的观测值更相似,这种相似性随着距离的增加而逐渐减弱,直到达到某个距离后相似性不再随距离变化。变异函数通常通过三个关键参数来描述空间依赖结构:块金值(nugget)、基台值(sill)和变程(range)。块金值代表距离为零时的半方差,反映了测量误差或小尺度变异;基台值代表半方差达到稳定时的值,反映了变量的总空间变异;变程代表空间自相关存在的最大距离,反映了空间依赖性的尺度。
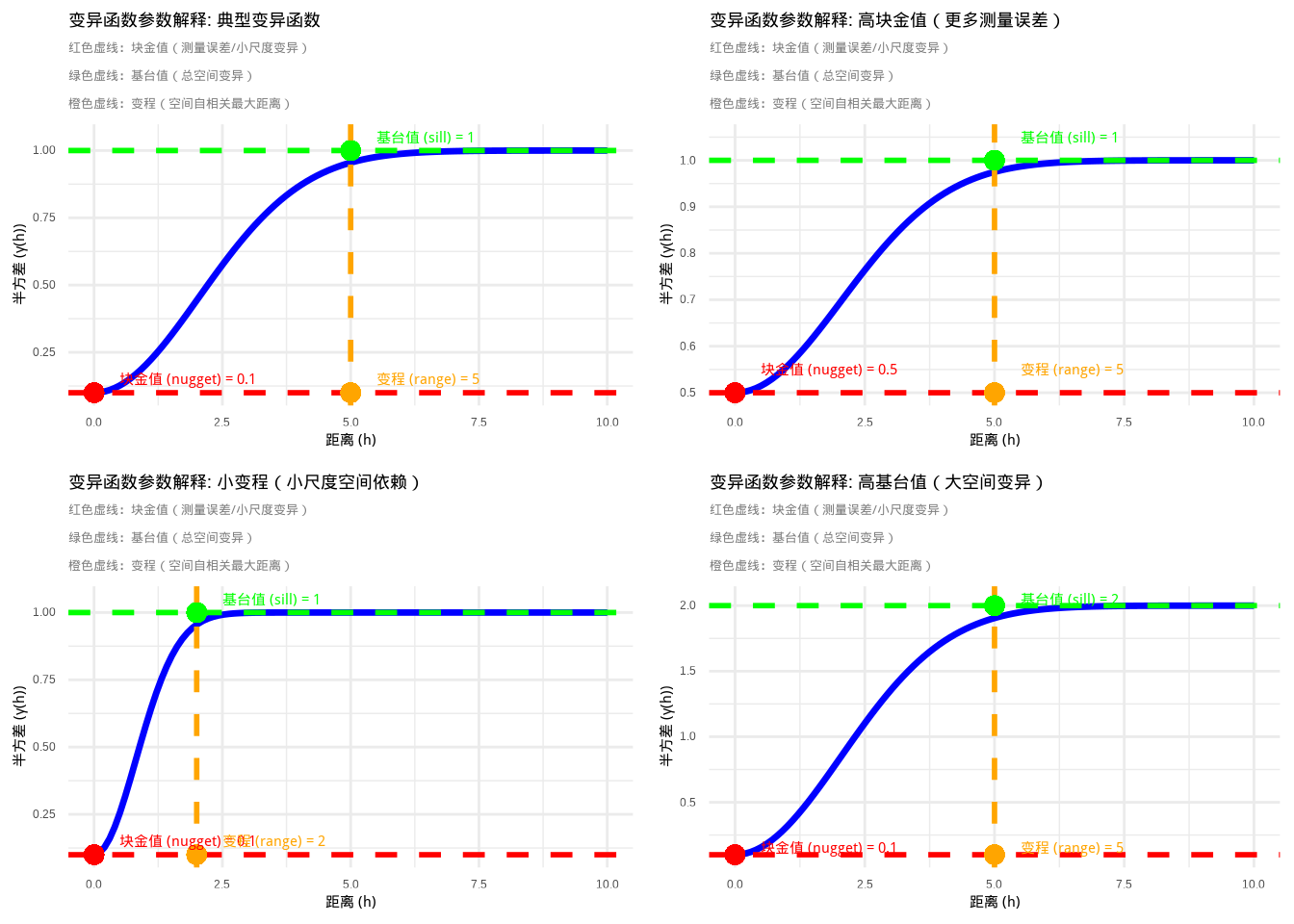
图5.20: 变异函数三个关键参数的技术解释:块金值(nugget)、基台值(sill)和变程(range)的直观展示。图中蓝色实线表示变异函数曲线,红色虚线标记块金值,绿色虚线标记基台值,橙色虚线标记变程
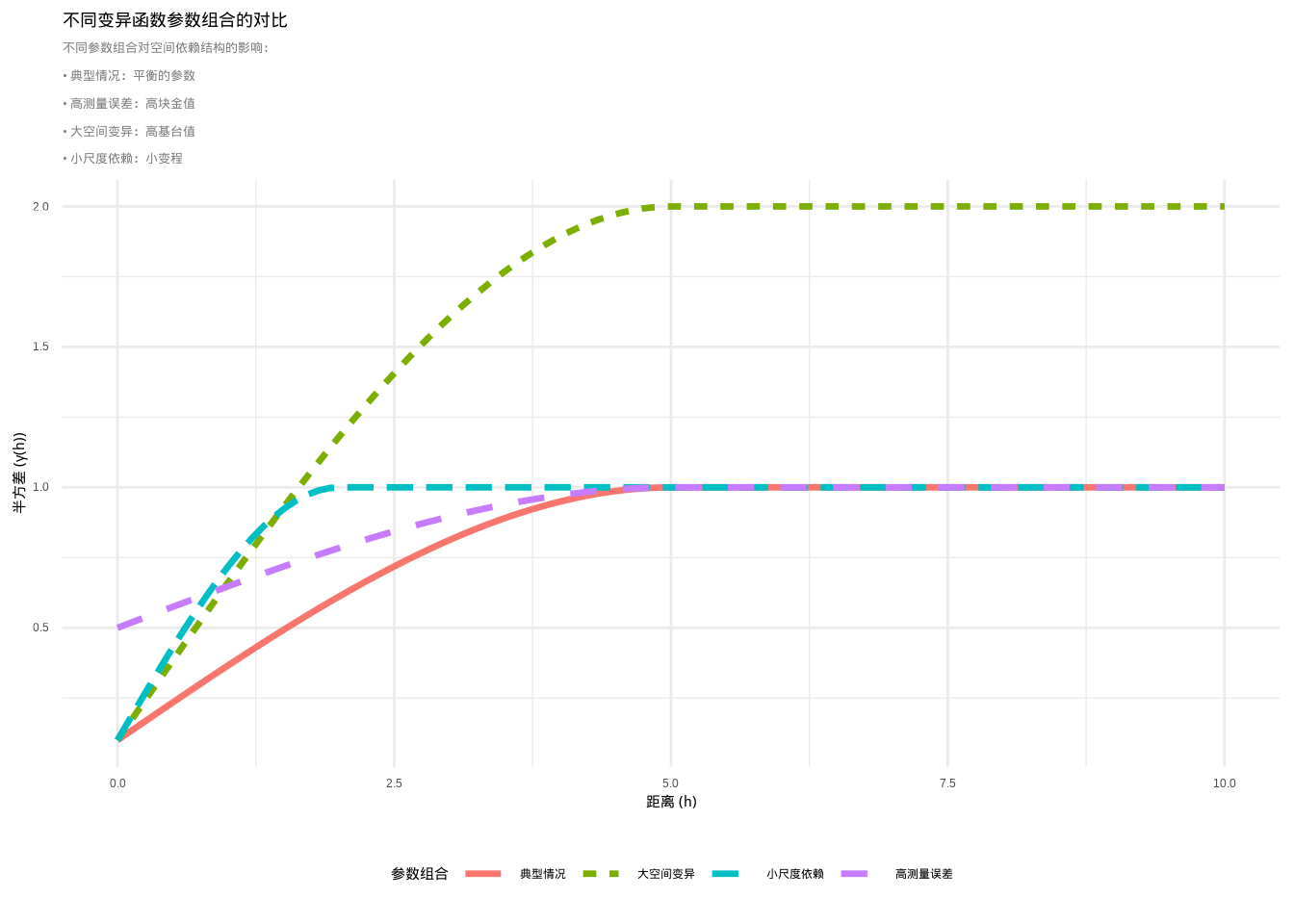
图5.21: 不同变异函数参数组合的对比:展示块金值、基台值和变程对空间依赖结构的影响。图中使用不同颜色和线型的曲线区分四种参数组合:典型情况、高测量误差、大空间变异和小尺度依赖
图5.20和5.21通过R代码技术性地解释了变异函数的三个关键参数。这些图形清晰地展示了块金值、基台值和变程在变异函数曲线中的位置和意义,帮助我们直观理解空间依赖结构的不同方面。
在生态学研究中,变异函数具有广泛的应用价值。例如,在分析物种分布时,变异函数可以帮助识别物种聚集的尺度;在研究环境异质性时,变异函数可以揭示环境因子的空间结构;在生态监测设计中,变异函数可以为确定合适的采样间距提供依据。变异函数的形状也提供了关于空间过程的重要信息:如果变异函数快速上升并达到基台值,表明空间依赖性在较小尺度上存在;如果变异函数缓慢上升,表明空间依赖性在较大尺度上存在;如果变异函数呈现周期性波动,可能反映重复的空间格局。此外,拟合的理论变异函数模型(如球状模型、指数模型、高斯模型等)可以用于空间插值(克里金法)和空间预测。
数学定义:对于空间变量\(Z(\mathbf{s})\),其中\(\mathbf{s}\)表示空间位置,变异函数定义为:
\[\gamma(\mathbf{h}) = \frac{1}{2}E[(Z(\mathbf{s} + \mathbf{h}) - Z(\mathbf{s}))^2]\]
其中\(\mathbf{h}\)是空间滞后向量,\(E[\cdot]\)表示期望值。
首先,我们通过图5.22展示土壤pH值的空间取样分布,这有助于我们直观理解数据的空间格局。然后,通过图??展示如何用变异函数来捕捉其中的空间自相关。
## grf: simulation(s) on randomly chosen locations with 100 points
## grf: process with 1 covariance structure(s)
## grf: nugget effect is: tausq= 0
## grf: covariance model 1 is: exponential(sigmasq=0.8, phi=30)
## grf: decomposition algorithm used is: cholesky
## grf: End of simulation procedure. Number of realizations: 1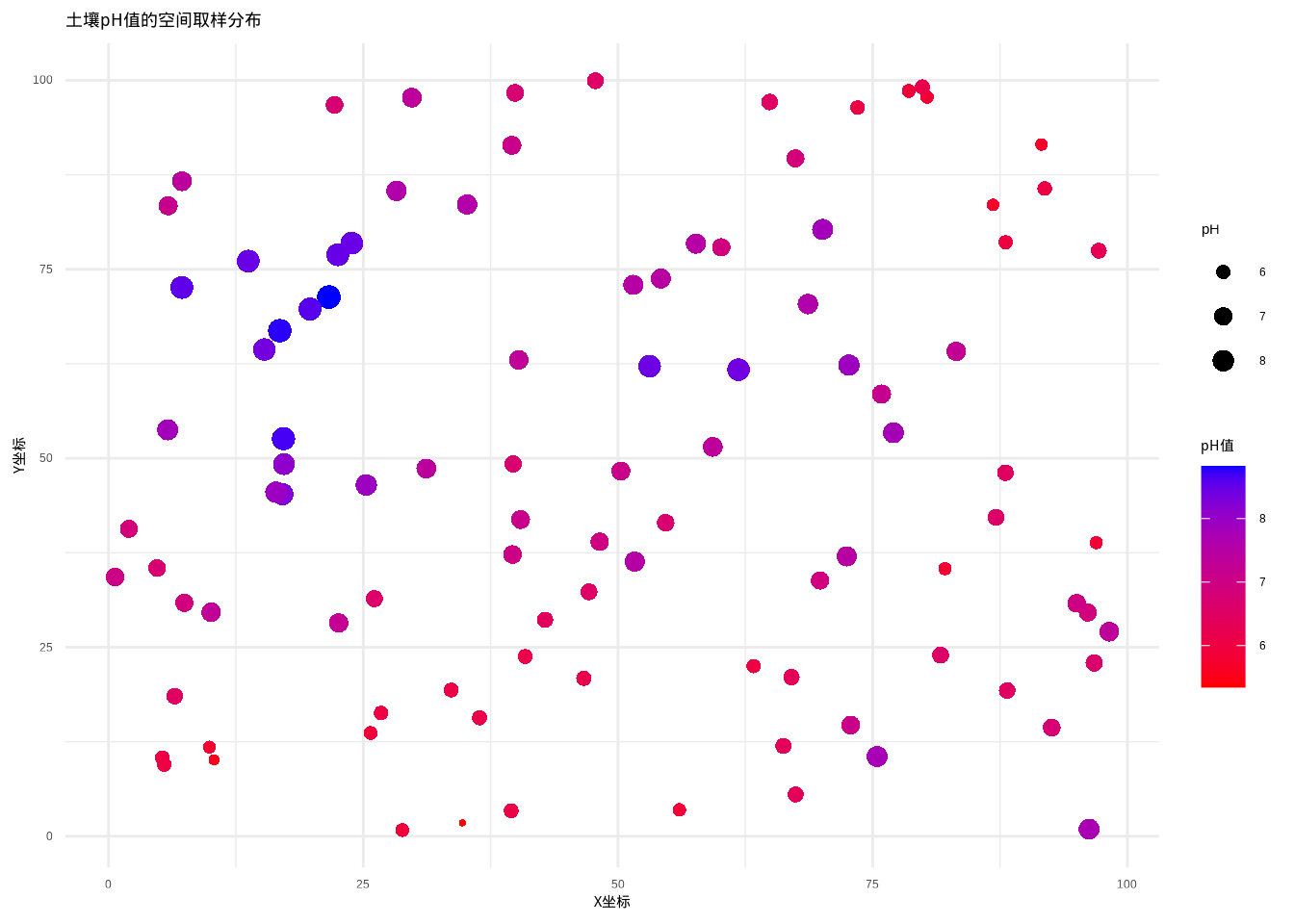
图5.22: 土壤pH值的空间取样分布图。图中使用从红色到蓝色的颜色渐变表示pH值大小,同时通过点的大小变化增强视觉区分
图5.23: 土壤pH值的经验变异函数和空间分布图
图5.24: 土壤pH值的经验变异函数和空间分布图
## 变异函数参数:
## 块金值 (nugget):0
## 偏基台值 (partial sill):8.068916
## 基台值 (sill):8.068916
## 变程 (range):411.67615.5.2 克里金插值:基于空间自相关的预测方法
克里金插值是一种基于变异函数理论的空间预测方法,由南非矿业工程师丹尼尔·克里金于20世纪50年代提出,最初用于金矿储量的估计,后来被广泛应用于地质学、环境科学和生态学等领域。克里金插值的核心思想是利用已知观测点之间的空间相关性来预测未知位置的属性值,其理论基础是区域化变量理论和最优无偏估计原则。
克里金插值的数学原理基于以下几个关键假设:首先,空间变量被认为是区域化变量,即在空间上具有连续性和相关性;其次,空间变量的变异结构可以通过变异函数来量化;最后,克里金插值寻求的是最优线性无偏估计,即在所有线性无偏估计中方差最小的估计。克里金插值的基本形式可以表示为:
\[\hat{Z}(s_0) = \sum_{i=1}^{n} \lambda_i Z(s_i)\]
其中\(\hat{Z}(s_0)\)是未知位置\(s_0\)的预测值,\(Z(s_i)\)是已知位置\(s_i\)的观测值,\(\lambda_i\)是权重系数。权重系数的确定需要满足两个条件:无偏性条件\(\sum_{i=1}^{n} \lambda_i = 1\)和最小方差条件。通过求解克里金方程组可以得到最优权重系数:
\[\begin{cases} \sum_{j=1}^{n} \lambda_j \gamma(s_i, s_j) + \mu = \gamma(s_i, s_0) & i = 1,2,\ldots,n \\ \sum_{j=1}^{n} \lambda_j = 1 \end{cases}\]
其中\(\gamma(s_i, s_j)\)是位置\(s_i\)和\(s_j\)之间的半方差,\(\mu\)是拉格朗日乘子。
克里金插值有多种类型,每种类型适用于不同的空间过程和假设条件。普通克里金是最常用的形式,适用于具有恒定均值的平稳空间过程。其假设空间变量的均值在整个研究区域内是常数,但未知。普通克里金通过局部邻域内的观测值来估计未知点的值,权重取决于观测点与预测点之间的空间相关性。普通克里金的预测方差可以表示为:
\[\sigma^2_{OK} = \sum_{i=1}^{n} \lambda_i \gamma(s_i, s_0) + \mu\]
这种预测方差提供了克里金预测的不确定性度量,在生态学应用中具有重要价值。
除了普通克里金,还有其他类型的克里金方法适用于更复杂的空间过程。简单克里金假设空间变量的均值已知且恒定,适用于有充分先验知识的场景。泛克里金适用于具有趋势的非平稳空间过程,通过引入趋势面函数来建模空间变量的系统性变化。协同克里金则利用辅助变量来提高主要变量的预测精度,特别适用于当辅助变量更容易获取或测量精度更高时。指示克里金用于处理分类变量或存在阈值的连续变量,通过将连续变量转换为指示变量来进行空间预测。
在生态学研究中,克里金插值具有广泛的应用价值。首先,它可以用于生成连续的空间分布图,如物种丰富度、环境因子、土壤属性等的空间分布。这些分布图为生态学家提供了直观的空间格局可视化,有助于识别热点区域、环境梯度和空间异质性。其次,克里金插值可以用于填补缺失数据,特别是在野外调查中由于各种原因无法到达所有位置时。通过基于已有观测点的空间相关性,可以合理估计缺失位置的值。第三,克里金预测方差提供了空间预测的不确定性信息,这对于生态风险评估和决策制定具有重要意义。例如,在保护生物学中,高预测方差的区域可能需要更密集的采样来降低不确定性。
克里金插值的实施通常包括以下几个步骤:数据探索和预处理、经验变异函数计算、理论变异函数拟合、克里金方程组求解、空间预测和不确定性评估。在数据探索阶段,需要检查数据的空间分布、异常值和趋势性。经验变异函数的计算需要考虑方向性,以检测各向异性。理论变异函数的拟合需要选择合适的模型(如球状模型、指数模型、高斯模型)和参数。克里金预测的质量取决于变异函数模型的准确性和空间采样设计的合理性。
尽管克里金插值在生态学中应用广泛,但也存在一些局限性和注意事项。首先,克里金插值对变异函数模型的选择比较敏感,不合适的模型可能导致有偏的预测。其次,克里金插值假设空间过程是平稳的或准平稳的,对于高度非平稳的过程可能需要使用泛克里金或其他方法。第三,克里金插值的预测精度受到采样密度和空间分布的影响,在采样稀疏的区域预测不确定性较高。第四,克里金插值对异常值比较敏感,需要在预处理阶段进行适当处理。
在生态学实践中,克里金插值通常与其他空间分析方法结合使用。例如,与地理信息系统(GIS)结合可以实现空间数据的可视化和分析;与遥感数据结合可以提供大尺度的环境背景;与统计模型结合可以分析空间格局与环境因子的关系。随着计算技术的发展,克里金插值也在不断演进,出现了如贝叶斯克里金、机器学习结合克里金等新方法,为生态学研究提供了更强大的空间分析工具。
# 进行空间插值(普通克里金法)
library(automap)
# 创建插值网格
grid <- expand.grid(
x = seq(0, 100, length.out = 50),
y = seq(0, 100, length.out = 50)
)
coordinates(grid) <- ~ x + y
gridded(grid) <- TRUE
# 执行克里金插值
kriging_result <- autoKrige(pH ~ 1, spatial_data, grid)## [using ordinary kriging]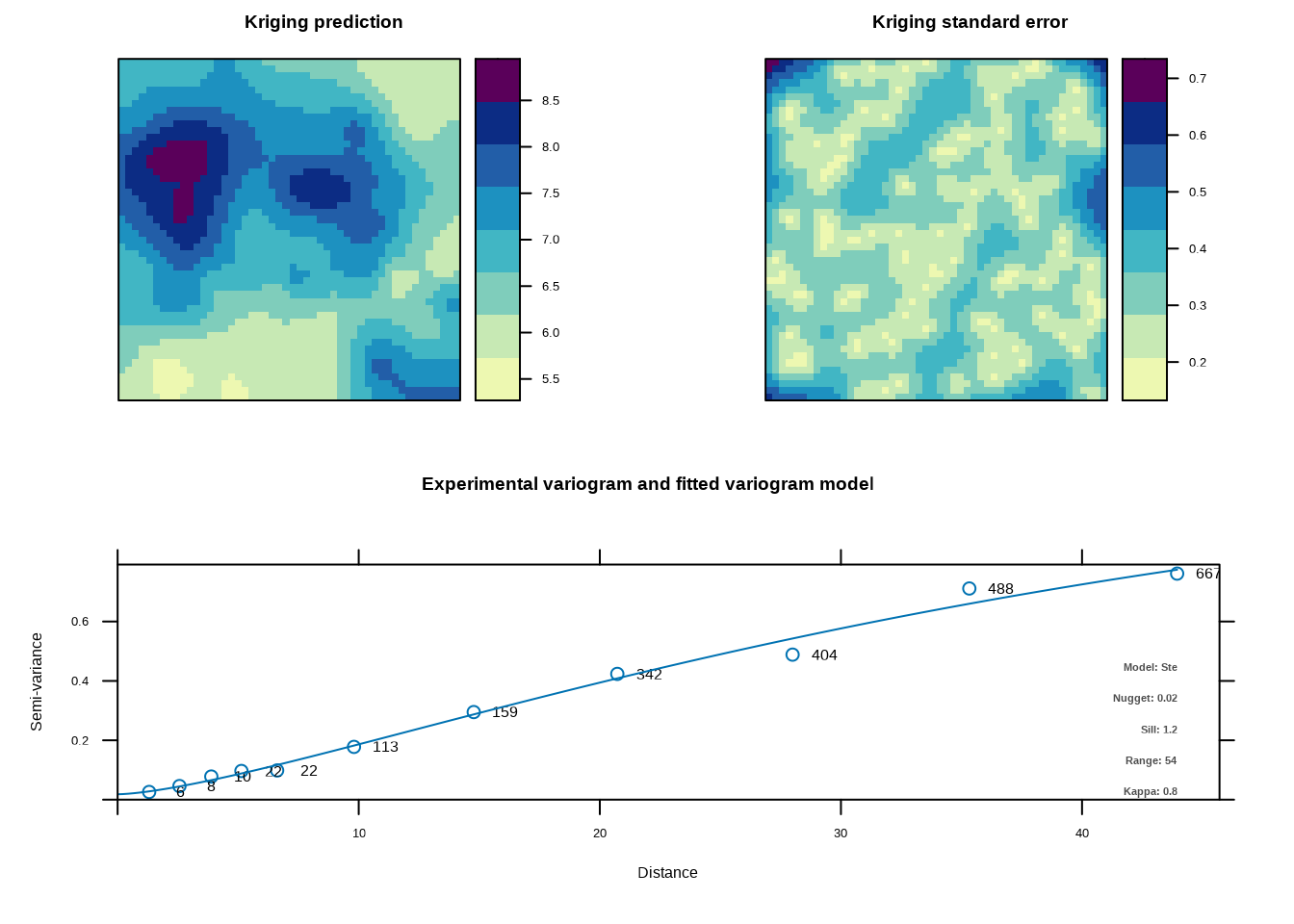
图5.25: 土壤pH值的克里金插值结果
## 克里金插值统计信息:## 预测值的范围: 5.5 8.72## 预测方差的范围: 0.0287 0.4863生态学意义:变异函数在生态学中广泛应用于量化空间依赖性的尺度,如物种分布的空间格局、环境异质性的空间结构、种群聚集的空间范围等。通过图5.25展示的克里金插值结果,我们可以看到基于空间自相关的预测方法如何生成连续的空间分布图,为生态学研究和环境管理提供重要的空间信息。
5.5.3 空间自相关指数:全局空间模式的检测
在研究森林中树木分布的空间格局时,我们想要了解整个研究区域内树木分布是随机分布、聚集分布还是均匀分布,这需要使用全局空间自相关指数来量化。
空间自相关指数是量化空间数据中自相关程度的统计量,其中最著名的是Moran’s I和Geary’s C。这些指数提供了对全局空间模式的整体度量,帮助我们判断空间数据是否表现出显著的空间自相关。Moran’s I是最常用的全局空间自相关指数,其计算原理类似于Pearson相关系数,但应用于空间邻接关系。Moran’s I的取值范围通常在-1到1之间,正值表示正空间自相关(即相似的值在空间上聚集),负值表示负空间自相关(即相异的值在空间上聚集),0值表示没有空间自相关(即随机分布)。
Geary’s C是另一个重要的全局空间自相关指数,其计算基于相邻观测值之间的差异。与Moran’s I不同,Geary’s C的取值范围在0到2之间,其中0表示完全正空间自相关,1表示没有空间自相关,大于1的值表示负空间自相关。Geary’s C对局部差异更加敏感,而Moran’s I对全局模式更加敏感。在生态学应用中,这两种指数往往结合使用,以提供对空间模式的全面理解。
数可以量化种群的聚集程度。此外,空间自相关检验还为许多空间统计方法提供了基础,如空间回归模型、空间方差分析等。
数学定义:
- Moran’s I:
\[I = \frac{n}{\sum_{i=1}^{n}\sum_{j=1}^{n}w_{ij}} \cdot \frac{\sum_{i=1}^{n}\sum_{j=1}^{n}w_{ij}(x_i - \bar{x})(x_j - \bar{x})}{\sum_{i=1}^{n}(x_i - \bar{x})^2}\]
其中\(n\)是观测点数,\(x_i\)是第\(i\)个观测值,\(\bar{x}\)是样本均值,\(w_{ij}\)是空间权重。
- Geary’s C:
\[C = \frac{(n-1)}{2\sum_{i=1}^{n}\sum_{j=1}^{n}w_{ij}} \cdot \frac{\sum_{i=1}^{n}\sum_{j=1}^{n}w_{ij}(x_i - x_j)^2}{\sum_{i=1}^{n}(x_i - \bar{x})^2}\]
空间自相关指数的计算需要定义空间权重矩阵,该矩阵量化了不同空间位置之间的邻接关系或空间影响。常见的权重定义方法包括基于距离的权重(如反距离权重)、基于邻接的权重(如queen邻接、rook邻接)和基于核函数的权重。权重矩阵的选择对空间自相关分析的结果有重要影响,需要根据研究的具体背景和空间过程的性质来合理选择。
在生态学研究中,空间自相关指数具有重要的应用价值。例如,在保护生物学中,Moran’s I可以帮助识别物种的热点区域;在景观生态学中,空间自相关分析可以揭示生境破碎化的空间模式;在种群生态学中,这些指
R代码实现:
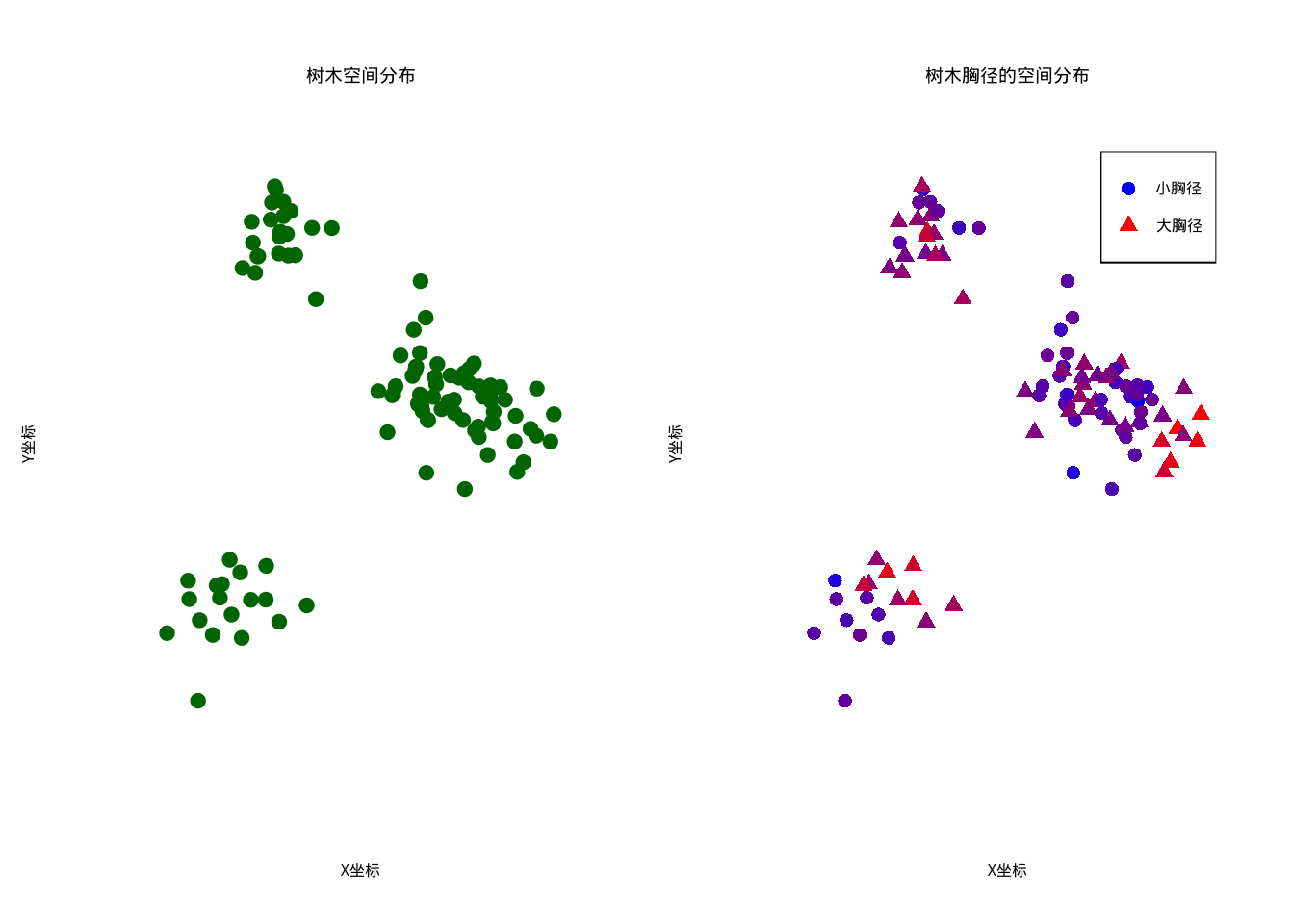
图5.26: 森林树木的空间分布和胸径变异。左图显示树木空间分布,右图使用从蓝色到红色的颜色渐变表示胸径大小,同时通过圆点和三角形的点型区分小胸径和大胸径
从图5.26中我们可以观察到:左图显示了树木在空间中的分布模式,可以看到明显的聚集现象;右图用颜色表示胸径大小,蓝色表示小胸径,红色表示大胸径,我们可以初步观察到胸径在空间上可能存在一定的聚集模式。
现在,我们使用空间自相关指数来量化这种空间模式:
load("data/forest_trees.RData")
knn_weights <- knn2nb(knearneigh(tree_coords, k = 5))
listw_weights <- nb2listw(knn_weights, style = "W")
# 进行空间自相关分析
# 计算Moran's I
moran_test <- moran.test(tree_dbh, listw_weights)
# 计算Geary's C
geary_test <- geary.test(tree_dbh, listw_weights)##
## === 空间自相关分析 ===## Moran's I检验结果:
## Moran's I统计量:0.425
## 期望值:-0.01
## 方差:0.003
## p值:4.48e-15##
## Geary's C检验结果:
## Geary's C统计量:0.568
## 期望值:1
## p值:7.06e-11为了验证空间自相关结果的统计显著性,我们进行蒙特卡洛模拟检验(结果见图5.27):
##
## Moran's I蒙特卡洛检验:## p值: 0.001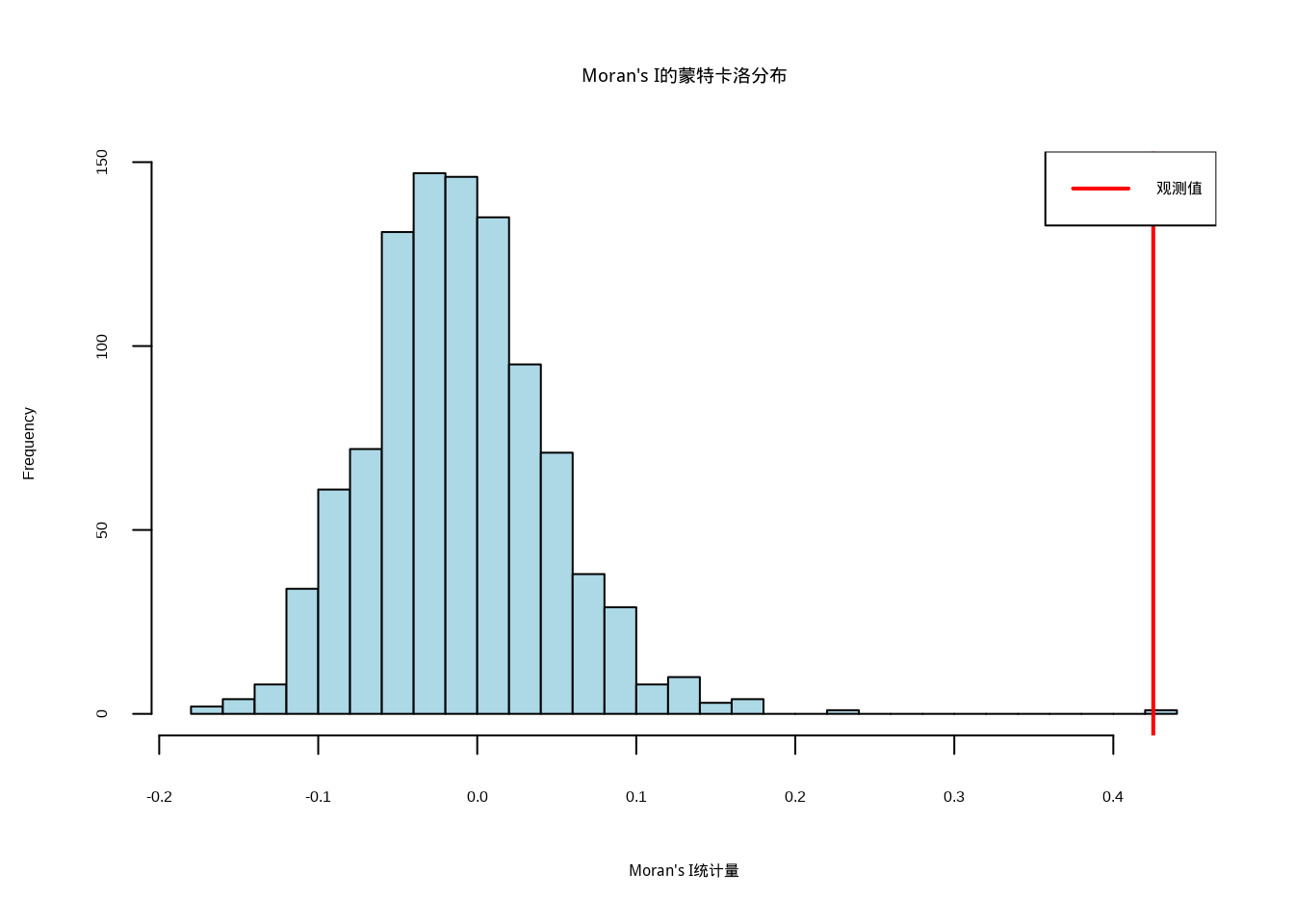
图5.27: Moran’s I的蒙特卡洛检验结果。图中浅蓝色直方图表示随机化分布,红色垂直线标记观测到的Moran’s I统计量
通过这个完整的分析流程,我们能够深入理解森林生态系统的空间结构特征及其统计意义。首先,从空间分布特征来看,模拟的森林树木呈现出明显的聚集分布模式,这种分布特征在真实的森林生态系统中十分常见,反映了种子传播、微环境适宜性等生态过程的空间异质性。树木胸径数据也显示出显著的空间变异模式,相邻树木的胸径值往往相近,这种空间依赖性暗示着可能存在某种生态机制在驱动胸径的空间分布格局。
进一步的空间自相关分析为我们提供了量化这种空间模式的统计证据。Moran’s I统计量显著大于其期望值,这一结果表明树木胸径在空间上存在正的空间自相关,即相似大小的树木倾向于在空间上聚集分布。Geary’s C统计量小于1的发现进一步支持了这一结论,因为Geary’s C对局部空间差异更为敏感,其值小于1同样表明空间单元之间存在正的空间自相关。这两种空间自相关指数的相互印证,增强了我们对空间模式判断的可靠性。
为了验证这种空间自相关模式的统计显著性,我们进行了蒙特卡洛模拟检验(图5.27)。检验结果显示观测到的Moran’s I统计量在随机分布假设下的概率极低,这表明我们观测到的空间自相关模式不太可能是随机产生的,而是具有统计显著性的真实空间模式。这种显著性检验为我们的生态学解释提供了坚实的统计基础。
这个完整的分析流程从数据模拟、可视化到统计检验,展示了空间自相关分析在生态学研究中的系统应用方法。它不仅帮助我们识别和量化空间模式,更重要的是为理解这些模式背后的生态过程提供了统计依据。这种分析方法为生态学家研究物种分布、种群动态、环境因子变异等空间生态学问题提供了实用的技术框架。
5.5.4 局部空间自相关:空间异质性的识别
在研究城市绿地中鸟类物种丰富度的分布时,我们不仅关心整体的空间模式,还希望识别出具体的局部热点(高值聚集区)和冷点(低值聚集区),这需要使用局部空间自相关分析方法。
局部空间自相关分析是全局空间自相关分析的延伸,它专注于识别空间数据中的局部异质性模式。最常用的局部空间自相关方法包括LISA(Local Indicators of Spatial Association)和Getis-Ord Gi*统计量。LISA由Luc Anselin于1995年提出,它度量每个空间单元与其邻居之间的局部空间关联程度,能够识别四种类型的局部空间关联:高-高聚集(热点)、低-低聚集(冷点)、高-低异常值(高值被低值包围)和低-高异常值(低值被高值包围)。
Getis-Ord \(G_i^*\)统计量是另一种重要的局部空间自相关方法,专门用于识别热点和冷点。与LISA不同,\(G_i^*\)统计量专注于检测高值或低值的空间聚集,而不区分其他类型的空间异常。\(G_i^*\)统计量的正值表示热点(高值聚集),负值表示冷点(低值聚集),统计量的绝对值越大表示聚集程度越强。
数学定义:
- 局部Moran’s I(LISA):
\[I_i = \frac{(x_i - \bar{x})}{\sum_{j=1}^{n}(x_j - \bar{x})^2/n} \sum_{j=1}^{n}w_{ij}(x_j - \bar{x})\]
- Getis-Ord \(G_i^*\):
\[G_i^* = \frac{\sum_{j=1}^{n}w_{ij}x_j}{\sum_{j=1}^{n}x_j}\]
现在,我们通过一个城市绿地鸟类物种丰富度的案例来演示局部空间自相关分析的具体应用:
现在,我们进行局部空间自相关分析来识别局部热点和冷点:
load("data/city_parks.RData")
# 创建空间权重矩阵(基于距离的权重)
dist_threshold <- 20 # 20单位内的公园视为邻居
# 创建基于距离的邻居列表
nb_dist <- dnearneigh(park_coords, 0, dist_threshold)
# 检查是否有孤立点,如果有则使用k近邻
if (any(card(nb_dist) == 0)) {
cat("检测到孤立点,使用k近邻方法\n")
nb_dist <- knn2nb(knearneigh(park_coords, k = 3))
}## 检测到孤立点,使用k近邻方法listw_dist <- nb2listw(nb_dist, style = "W")
# 计算局部Moran's I(LISA)
local_moran <- localmoran(bird_richness, listw_dist)
# 创建LISA分类
lisa_results <- data.frame(
x = coordinates(park_coords)[, 1],
y = coordinates(park_coords)[, 2],
richness = bird_richness,
local_i = local_moran[, 1],
p_value = local_moran[, 5]
)
# 根据LISA值分类
lisa_results$lisa_type <- "不显著"
lisa_results$lisa_type[lisa_results$p_value < 0.05 &
lisa_results$local_i > 0 &
lisa_results$richness > mean(bird_richness)] <- "高-高"
lisa_results$lisa_type[lisa_results$p_value < 0.05 &
lisa_results$local_i > 0 &
lisa_results$richness < mean(bird_richness)] <- "低-低"
lisa_results$lisa_type[lisa_results$p_value < 0.05 &
lisa_results$local_i < 0 &
lisa_results$richness > mean(bird_richness)] <- "高-低"
lisa_results$lisa_type[lisa_results$p_value < 0.05 &
lisa_results$local_i < 0 &
lisa_results$richness < mean(bird_richness)] <- "低-高"
# 计算Getis-Ord Gi*
local_g <- localG(bird_richness, listw_dist)
# 添加Gi*结果
lisa_results$gi_star <- as.numeric(local_g)
lisa_results$gi_type <- "不显著"
lisa_results$gi_type[lisa_results$gi_star > 1.96] <- "热点"
lisa_results$gi_type[lisa_results$gi_star < -1.96] <- "冷点"现在让我们可视化局部空间自相关分析的结果:
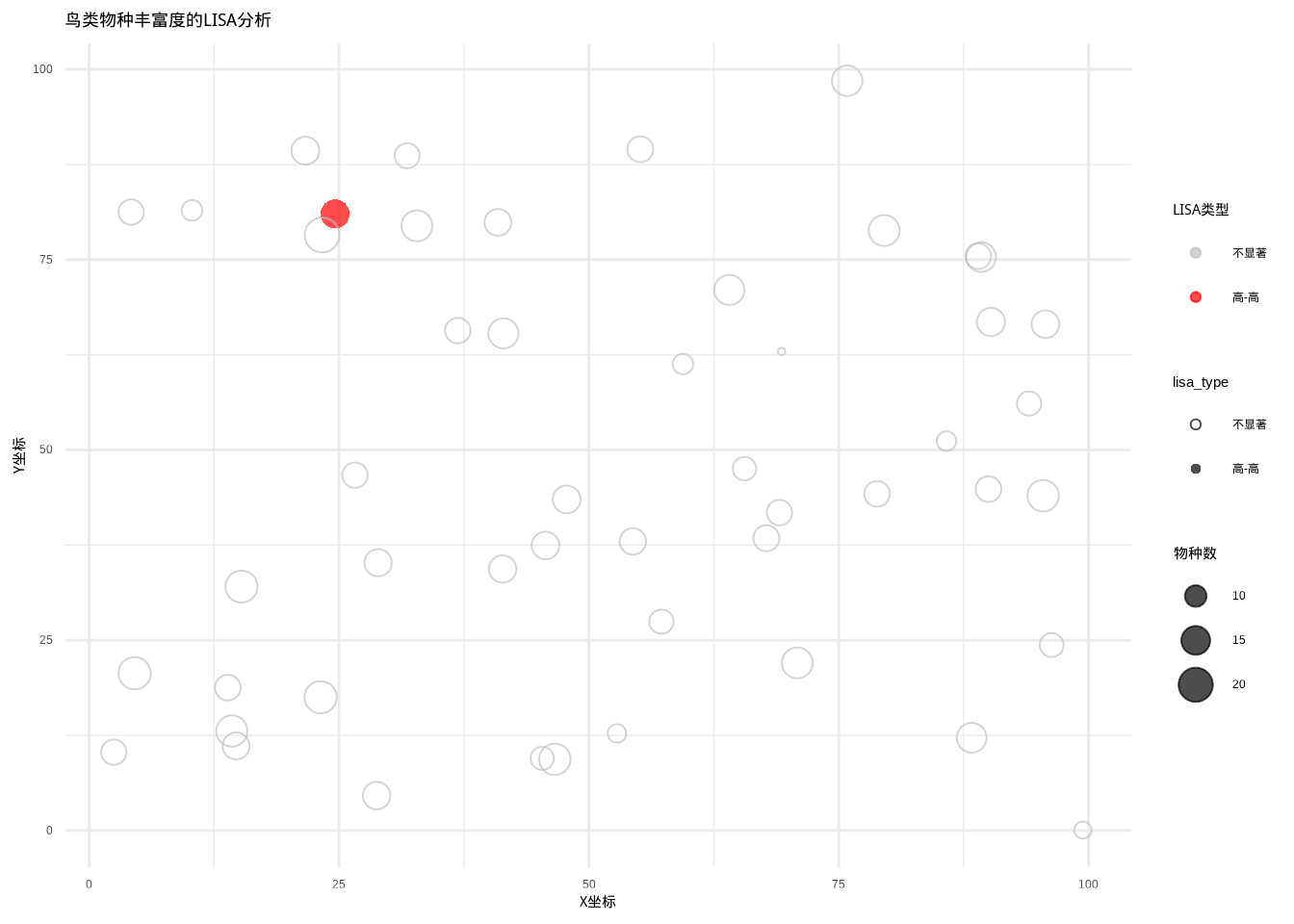
图5.28: 鸟类物种丰富度的LISA分析结果。图中使用不同颜色和点型区分五种LISA类型:高-高(红色圆点)、低-低(蓝色三角形)、高-低(粉色方形)、低-高(浅蓝色菱形)和不显著(灰色空心圆点)
图5.28展示了鸟类物种丰富度的局部空间自相关分析结果。该散点图采用颜色编码系统表示不同的LISA类型:红色表示”高-高”聚集区(热点区域,即物种丰富度高且周边地区也高),蓝色表示”低-低”聚集区(冷点区域,即物种丰富度低且周边地区也低),粉色表示”高-低”异常区(高值被低值包围),浅蓝色表示”低-高”异常区(低值被高值包围),灰色表示统计不显著的区域。点的大小与物种丰富度成正比,直观地显示了空间格局的异质性。这种可视化方法对于识别生物多样性保护的关键区域、理解物种分布的空间依赖性以及制定区域化的生态保护策略具有重要价值,能够揭示传统全局统计方法无法发现的局部空间关联模式。
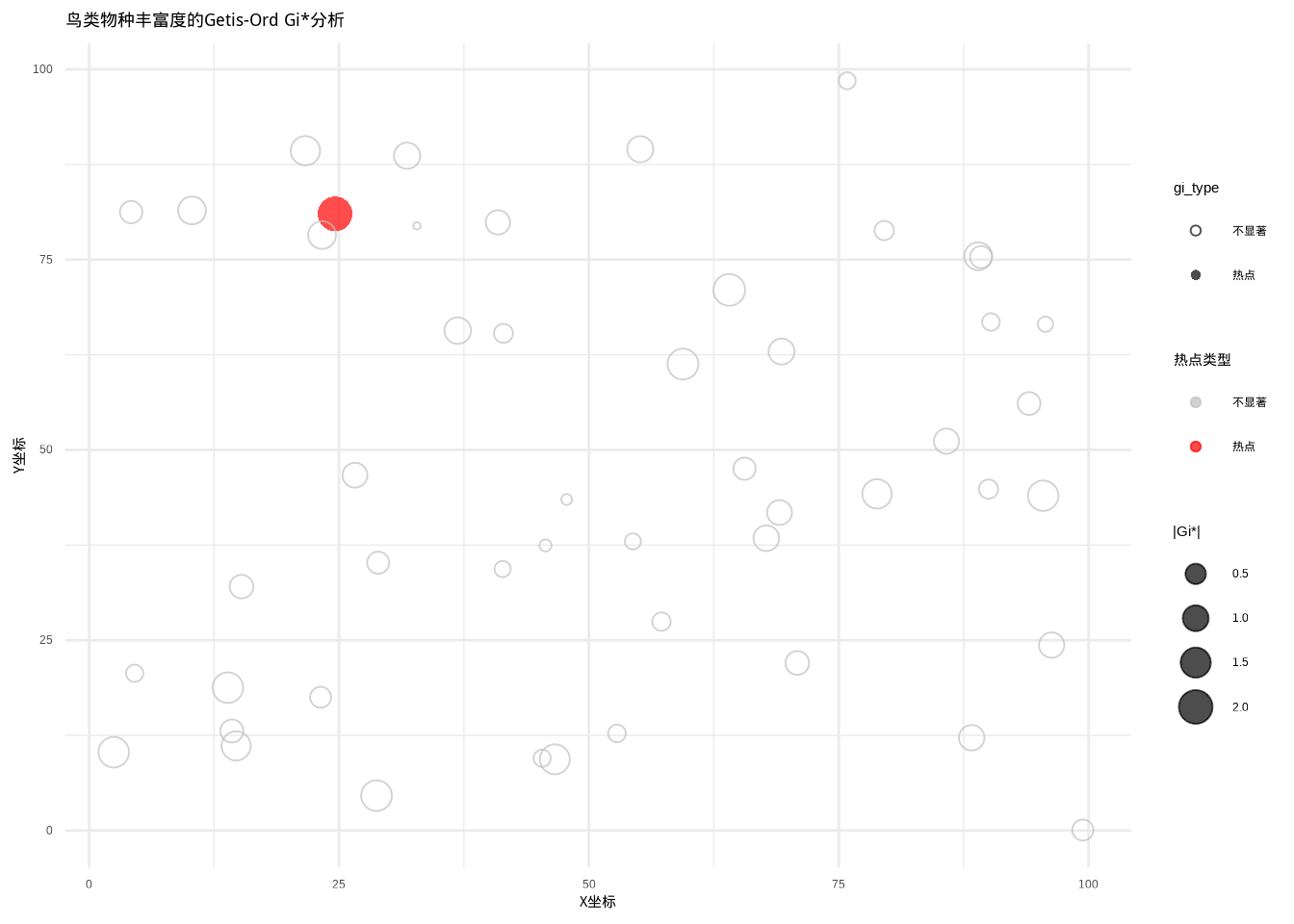
图5.29: 鸟类物种丰富度的Getis-Ord Gi*分析结果。图中使用不同颜色和点型区分三种类型:热点(红色圆点)、冷点(蓝色三角形)和不显著(灰色空心圆点)
图5.29展示了鸟类物种丰富度的Getis-Ord Gi热点分析结果。该散点图采用简化的颜色编码系统:红色表示统计显著的热点区域(高值聚集区),蓝色表示统计显著的冷点区域(低值聚集区),灰色表示统计不显著的区域。点的大小与Gi统计量的绝对值成正比,反映了局部空间聚集的强度。与LISA分析相比,Getis-Ord Gi*分析更专注于识别高值或低值的空间聚集,而不区分”高-低”或”低-高”等异常模式。这种可视化方法在生态学保护规划中特别有用,能够快速识别生物多样性的核心保护区域(热点)和生态恢复的优先区域(冷点),为制定差异化的空间管理策略提供科学依据。
现在让我们查看局部空间自相关分析的统计结果:
## LISA分析结果摘要:
## 总公园数:50
## 显著LISA模式的数量:1
## 高-高聚集(热点):1
## 低-低聚集(冷点):0
## 高-低异常值:0
## 低-高异常值:0##
## Getis-Ord Gi*分析结果摘要:
## 热点数量:1
## 冷点数量:0进行局部空间自相关分析时,需要注意多重比较问题。由于同时检验多个局部统计量,传统的显著性水平可能需要调整,如使用错误发现率(FDR)控制:
## 经过FDR校正后的显著LISA模式:
## 数量:0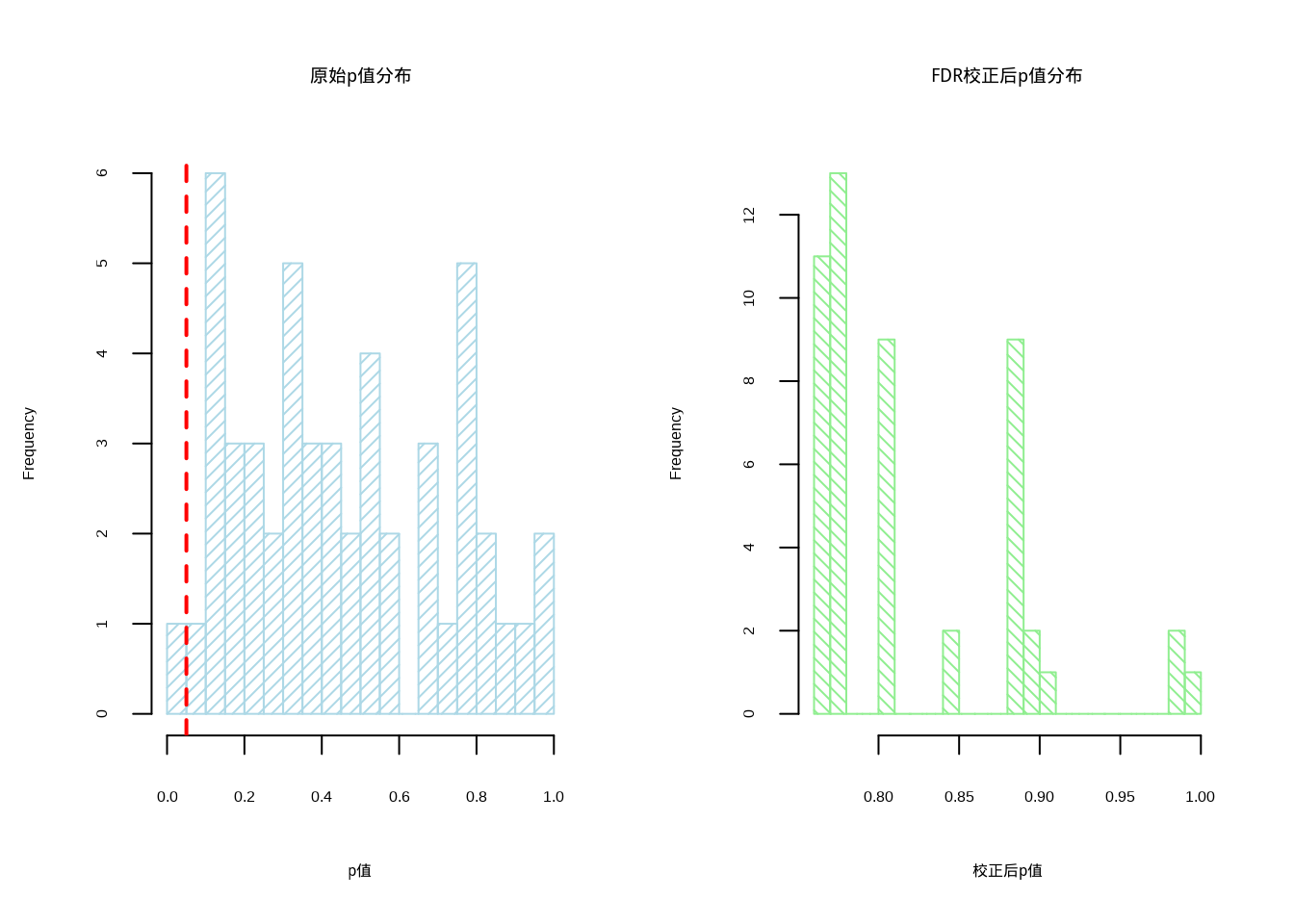
图5.30: 多重比较校正前后的p值分布对比。左图使用浅蓝色斜线填充表示原始p值分布,右图使用浅绿色反斜线填充表示FDR校正后p值分布,两图中红色虚线均标记显著性阈值0.05
图5.30展示了多重比较校正前后p值分布的对比。该双面板直方图采用并排布局,左侧显示原始p值分布(浅蓝色),右侧显示经过错误发现率校正后的p值分布(浅绿色)。红色垂直线标记0.05显著性水平,直观展示了FDR校正对统计显著性的影响。在局部空间自相关分析中,由于同时检验多个空间单元,多重比较问题可能导致假阳性结果增加。FDR校正通过调整p值来控制错误发现率,确保统计推断的可靠性。这种可视化方法帮助生态学家理解多重比较校正的必要性,并在空间统计分析中做出更保守但更可靠的结论。
LISA分析为我们提供了对局部空间模式的详细分类。高-高聚集区(热点)代表了物种丰富度高的绿地聚集在一起,这些区域可能是城市中生态条件最优越、保护价值最高的区域;低-低聚集区(冷点)则代表了物种丰富度低的绿地聚集,可能反映了城市环境压力较大或生态条件较差的区域。高-低异常值和低-高异常值则揭示了空间异质性的复杂模式,高值被低值包围可能表示孤立的优质栖息地,而低值被高值包围可能表示受到局部干扰的区域。
Getis-Ord \(G_i^*\)分析进一步验证了热点和冷点的存在,其专注于识别高值或低值的空间聚集,而不考虑其他类型的空间异常。\(G_i^*\)分析的结果与LISA分析相互印证,增强了我们对空间模式判断的可靠性。两种方法的结合使用提供了对局部空间异质性的全面理解。
多重比较校正的重要性在这个分析中得到了体现。由于同时检验多个局部统计量,传统的显著性水平可能导致假阳性结果的增加。FDR校正帮助我们控制错误发现率,确保我们识别的显著模式具有更高的可靠性。校正前后显著模式数量的变化提醒我们在解释局部空间自相关结果时需要谨慎。
这个完整的分析流程从数据模拟、空间权重构建、局部统计量计算到多重比较校正,展示了局部空间自相关分析在城市生态学研究中的系统应用方法。它不仅帮助我们识别和量化局部空间模式,更重要的是为理解这些模式背后的生态过程提供了统计依据,为城市生态规划、生物多样性保护和栖息地管理提供了实用的技术框架。
5.5.5 空间平稳性:空间分析的基础假设
在研究森林生物量的空间分布时,我们需要首先检验空间数据的平稳性,因为非平稳空间过程可能导致有偏的空间预测和错误的统计推断。
空间平稳性是空间统计学的基本假设,指的是空间过程的统计特性(如均值、方差和协方差结构)在空间上保持恒定。与时间序列平稳性类似,空间平稳性也分为严格平稳和弱平稳(二阶平稳)。严格平稳要求空间过程的任意有限维联合分布不随空间平移而改变,而弱平稳只要求均值恒定、方差有限且协方差只依赖于空间位置差而不依赖于具体位置。在生态学实践中,我们通常关注弱平稳性,因为它更容易检验且对于大多数空间分析方法已经足够。
数学定义:弱平稳空间过程满足:
- \(E[Z(\mathbf{s})] = \mu\)(常数均值)
- \(Var[Z(\mathbf{s})] = \sigma^2 < \infty\)(有限常数方差)
- \(Cov[Z(\mathbf{s}), Z(\mathbf{s}+\mathbf{h})] = C(\mathbf{h})\)(协方差只依赖于空间滞后\(\mathbf{h}\),不依赖于具体位置\(\mathbf{s}\))
为了直观理解空间平稳性的概念,让我们对比一下平稳和非平稳空间过程的典型特征。
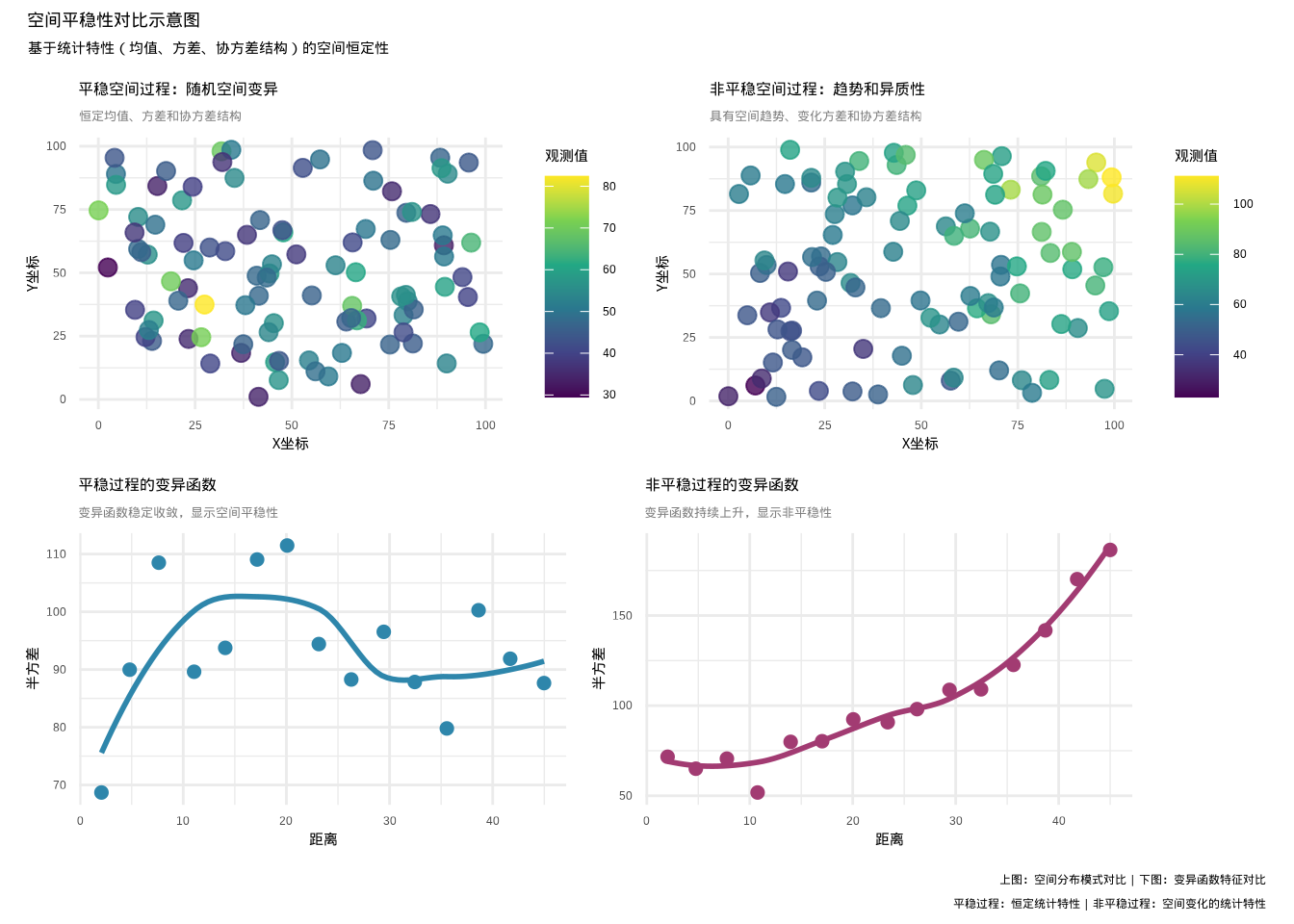
图5.31: 空间平稳性对比示意图:左上显示平稳空间过程(恒定统计特性),右上显示非平稳空间过程(具有趋势和空间异质性),左下蓝色散点和曲线表示平稳过程的变异函数,右下紫色散点和曲线表示非平稳过程的变异函数
上面的对比图(见5.31)清晰地展示了平稳空间过程和非平稳空间过程在统计特性上的根本差异,这对于理解空间分析的基本假设至关重要。
在平稳空间过程的左侧部分,我们可以看到随机空间变异显示典型的平稳特征。空间分布图显示观测值在整个研究区域内随机分布,既没有明显的空间趋势,也没有系统性的空间模式,观测值之间表现出恒定的均值和方差。这种恒定的统计特性正是空间平稳性的核心特征。变异函数图进一步证实了平稳性,半方差随着距离增加而稳定收敛到基台值,表明空间依赖性在特定距离范围内存在且稳定。
相比之下,非平稳空间过程的右侧部分展现了完全不同的特征。具有趋势和异质性的空间过程显示明显的非平稳性,空间分布图中可见从西北到东南的明显梯度变化,反映了空间变量的系统性趋势。同时观测值的变异程度也随空间位置变化,显示了空间异质性特征。变异函数图呈现出持续上升的模式,半方差随着距离增加而不断增大,无法稳定收敛到基台值,显示强烈的非平稳性特征。这种持续上升的变异函数主要源于空间过程中的趋势成分,而非真正的空间依赖性。
在生态学研究中,正确识别空间过程的平稳性具有重要的实践意义。对于平稳空间过程,由于其统计特性在空间上稳定,适合直接应用经典的空间统计方法,如普通克里金插值、空间自相关分析等,统计推断相对可靠。而对于非平稳空间过程,如具有环境梯度的生态变量分布,则需要先进行平稳化处理,如趋势去除、空间变换等方法,否则可能导致严重的统计问题。空间趋势可能导致虚假的空间相关性,模型可能错误地拟合趋势而非真实的生态关系,置信区间和空间预测也可能严重偏离真实情况。通过图示法和变异函数分析识别空间平稳性是最直观的检验方法,为后续的空间统计分析和生态解释提供基础保障。
空间平稳性检验在生态学空间分析中具有至关重要的意义。许多经典的空间统计方法,如克里金插值、空间自回归模型和地统计分析,都建立在平稳性假设的基础上。如果空间过程是非平稳的,直接应用这些方法可能导致严重的统计问题,如有偏估计和无效的假设检验。生态学中的许多空间数据都表现出非平稳特征,如环境梯度(海拔、纬度梯度)、人为影响的空间模式(城市化梯度、污染扩散)和生态系统演替的空间趋势等。
检验空间平稳性的常用方法包括图示法、变异函数分析、趋势面检验和方向性变异函数分析等。图示法通过观察空间分布图来识别明显的趋势或空间模式;变异函数分析通过检查变异函数的收敛模式来判断平稳性——平稳空间过程的变异函数应该收敛到基台值,而非平稳空间过程的变异函数通常持续上升;趋势面检验通过拟合空间趋势模型来检验趋势的显著性;方向性变异函数分析则通过比较不同方向上的变异函数来检测各向异性。
趋势面检验是检验空间平稳性的重要方法,它通过拟合多项式趋势面来量化空间趋势的显著性。趋势面模型的一般形式为:
\[Z(\mathbf{s}) = \beta_0 + \beta_1x + \beta_2y + \beta_3x^2 + \beta_4xy + \beta_5y^2 + \cdots + \epsilon(\mathbf{s})\]
其中\(\mathbf{s} = (x,y)\)表示空间坐标,\(\beta_i\)是趋势系数,\(\epsilon(\mathbf{s})\)是平稳的残差过程。
趋势面检验的原假设\(H_0\)是:所有趋势系数\(\beta_i = 0\)(即没有空间趋势,过程是平稳的);备择假设\(H_1\)是:至少有一个趋势系数\(\beta_i \neq 0\)(即存在空间趋势,过程是非平稳的)。检验统计量通常使用F统计量:
\[F = \frac{(SSE_r - SSE_f)/(df_r - df_f)}{SSE_f/df_f}\]
其中\(SSE_r\)是简化模型(无趋势)的残差平方和,\(SSE_f\)是完整模型(有趋势)的残差平方和,\(df_r\)和\(df_f\)分别是相应的自由度。
在生态学研究中,趋势面检验具有重要的应用价值。例如,在分析物种丰富度的空间分布时,趋势面检验可以帮助判断是否存在环境梯度的影响;在研究污染物扩散时,趋势面检验可以识别污染源的空间影响模式;在生态系统监测中,趋势面检验为构建准确的空间模型提供了基础。
需要注意的是,趋势面检验对趋势函数形式的选择比较敏感。多项式趋势面可能无法充分捕捉复杂的空间模式,有时需要使用更灵活的趋势函数或基于样条的方法。此外,趋势面检验需要足够的空间采样点来可靠估计趋势系数,在采样稀疏的区域检验功效可能较低。
接下来我们就用一个简单的例子来演示空间平稳性的检验和处理。我们将使用森林生物量的空间分布数据来演示空间平稳性的检验和处理。
首先,我们模拟了一个具有空间趋势和异质性的非平稳空间过程(图5.32),该过程模拟了森林生物量在100公顷样地内的空间分布。
## grf: simulation(s) on randomly chosen locations with 100 points
## grf: process with 1 covariance structure(s)
## grf: nugget effect is: tausq= 0
## grf: covariance model 1 is: exponential(sigmasq=10, phi=20)
## grf: decomposition algorithm used is: cholesky
## grf: End of simulation procedure. Number of realizations: 1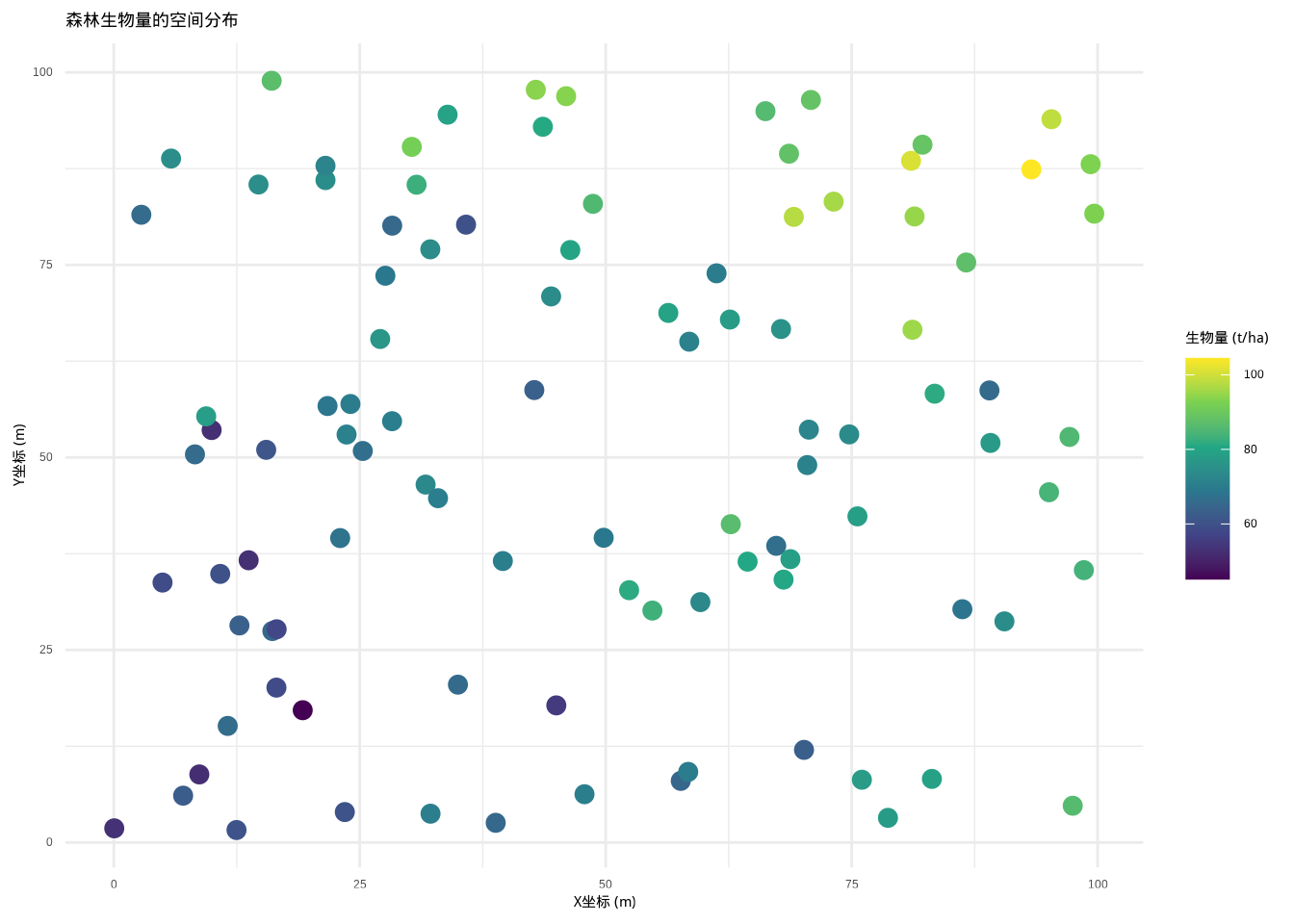
图5.32: 森林生物量的空间分布图,展示了具有趋势和空间异质性的非平稳空间过程
# 检验空间平稳性:趋势面检验
library(sp)
# 拟合趋势面模型
# 一阶趋势面(线性趋势)
trend_linear <- lm(biomass ~ x + y, data = spatial_df)
# 二阶趋势面(二次趋势)
trend_quadratic <- lm(biomass ~ x + y + I(x^2) + I(y^2) + I(x*y),
data = spatial_df)| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| x | 1 | 5978.493 | 5978.49335 | 118.64693 | 0 |
| y | 1 | 3789.080 | 3789.07994 | 75.19666 | 0 |
| Residuals | 97 | 4887.727 | 50.38894 | NA | NA |
| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| x | 1 | 5978.4933486 | 5978.4933486 | 130.9929680 | 0.0000000 |
| y | 1 | 3789.0799404 | 3789.0799404 | 83.0213899 | 0.0000000 |
| I(x^2) | 1 | 0.0230785 | 0.0230785 | 0.0005057 | 0.9821071 |
| I(y^2) | 1 | 597.5007693 | 597.5007693 | 13.0916595 | 0.0004799 |
| I(x * y) | 1 | 0.0620205 | 0.0620205 | 0.0013589 | 0.9706721 |
| Residuals | 94 | 4290.1415490 | 45.6398037 | NA | NA |
##
## 模型比较:## 无趋势模型(仅截距)AIC: 786.5264## 一阶趋势面AIC: 680.719## 二阶趋势面AIC: 673.6782表5.3展示了一阶趋势面的F检验结果,用于评估线性趋势对生物量空间变异的解释程度。表5.5展示了二阶趋势面的F检验结果,用于评估线性趋势对生物量空间变异的解释程度。
# 检查残差的平稳性
residuals_linear <- residuals(trend_linear)
residuals_quadratic <- residuals(trend_quadratic)## 残差统计:
## 原始数据方差:148.03
## 一阶趋势面残差方差:49.37
## 二阶趋势面残差方差:43.33当发现空间过程非平稳时,通常需要进行趋势去除或变换来使其平稳化。趋势去除可以通过拟合趋势面并计算残差来实现,空间变换(如对数变换)可以稳定方差。经过这些处理后的平稳空间过程就可以安全地应用各种空间统计分析方法了。在生态学应用中,理解空间过程的平稳性不仅关系到统计方法的正确使用,也帮助我们识别生态系统的空间变化模式和动态特征。
趋势去除是处理非平稳空间过程最常用的方法之一,其数学原理基于空间过程的分解:\(Z(\mathbf{s}) = m(\mathbf{s}) + \epsilon(\mathbf{s})\),其中\(m(\mathbf{s})\)是确定性趋势成分,\(\epsilon(\mathbf{s})\)是平稳的随机残差。通过估计趋势函数\(\hat{m}(\mathbf{s})\),我们可以得到平稳的残差过程\(\hat{\epsilon}(\mathbf{s}) = Z(\mathbf{s}) - \hat{m}(\mathbf{s})\)。
在生态学空间分析中,趋势去除具有重要的应用价值。许多生态过程,如物种分布、环境因子变异、生态系统生产力等,往往表现出明显的空间趋势特征。通过趋势去除,我们可以将这些趋势从原始数据中分离出来,从而更好地分析数据中的空间随机变异成分。例如,在研究森林生物量的空间分布时,趋势去除能够帮助我们识别局部的空间聚集模式,而不是仅仅关注整体的空间梯度。
需要注意的是,趋势去除虽然能够分离趋势成分,但可能会引入新的问题。趋势函数的选择对结果有重要影响,不合适的趋势函数可能导致过度拟合或欠拟合。此外,趋势去除后的残差过程可能仍然存在空间异质性,需要进一步检验。在实际应用中,通常需要结合统计检验(如变异函数分析)来验证去趋势后过程的平稳性,确保趋势去除达到了预期效果。
接下来我们就用趋势去除来处理上面例子中空间非平稳问题。通过趋势去除处理,我们可以将原始的非平稳空间过程转换为平稳过程,从而满足空间分析的基本假设。
##
## 进行趋势去除处理...
## 使用二阶趋势面进行趋势去除
## 去趋势后过程的统计特性:
## 均值:0
## 方差:43.335图5.33展示了原始森林生物量的空间分布,可以观察到明显的空间趋势和异质性,这是典型的非平稳空间过程特征。
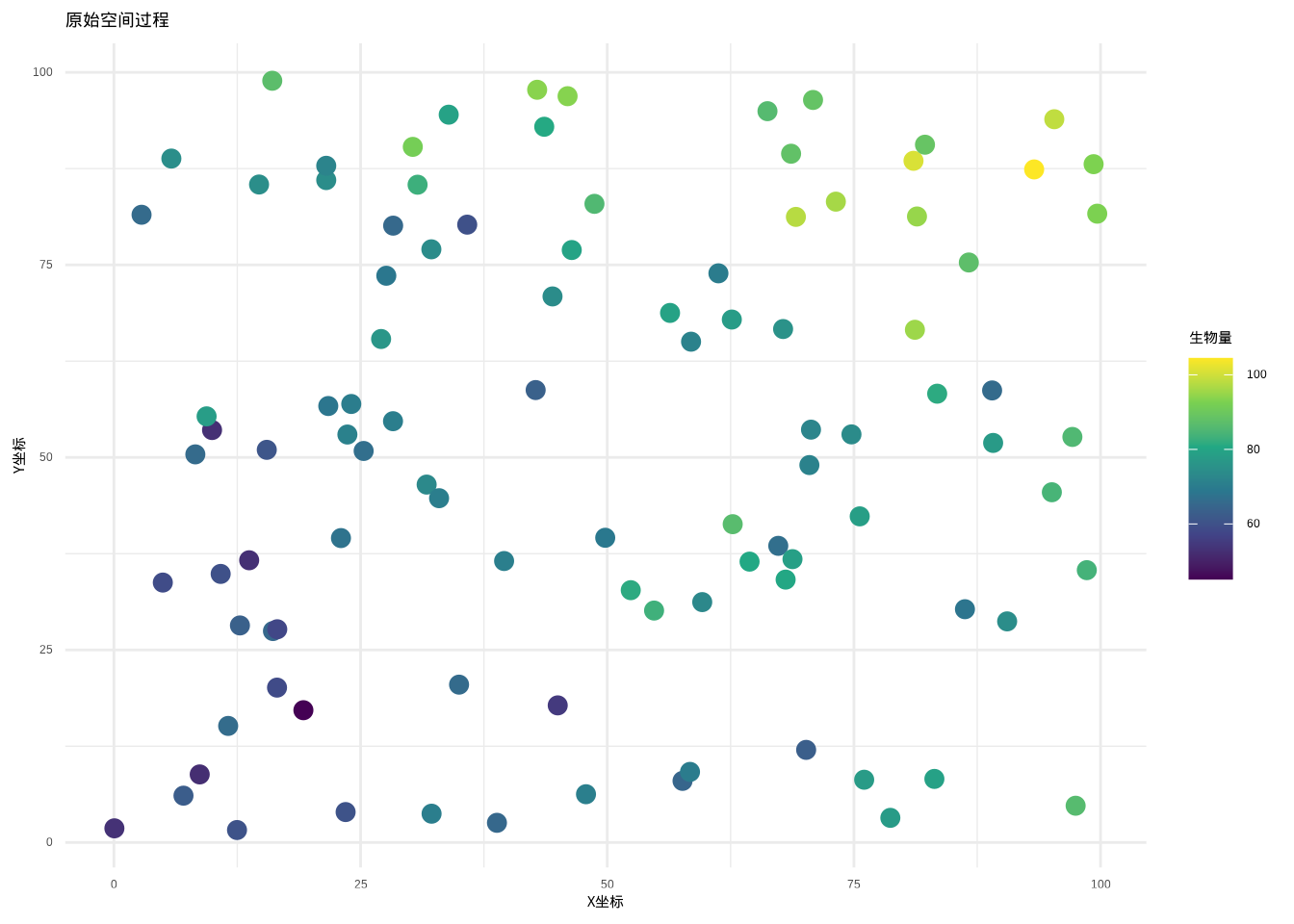
图5.33: 原始森林生物量空间分布,显示明显的空间趋势和异质性
经过趋势去除处理后,空间过程的趋势成分被有效去除,如图5.34所示,去趋势后的过程主要保留了空间随机变异成分。
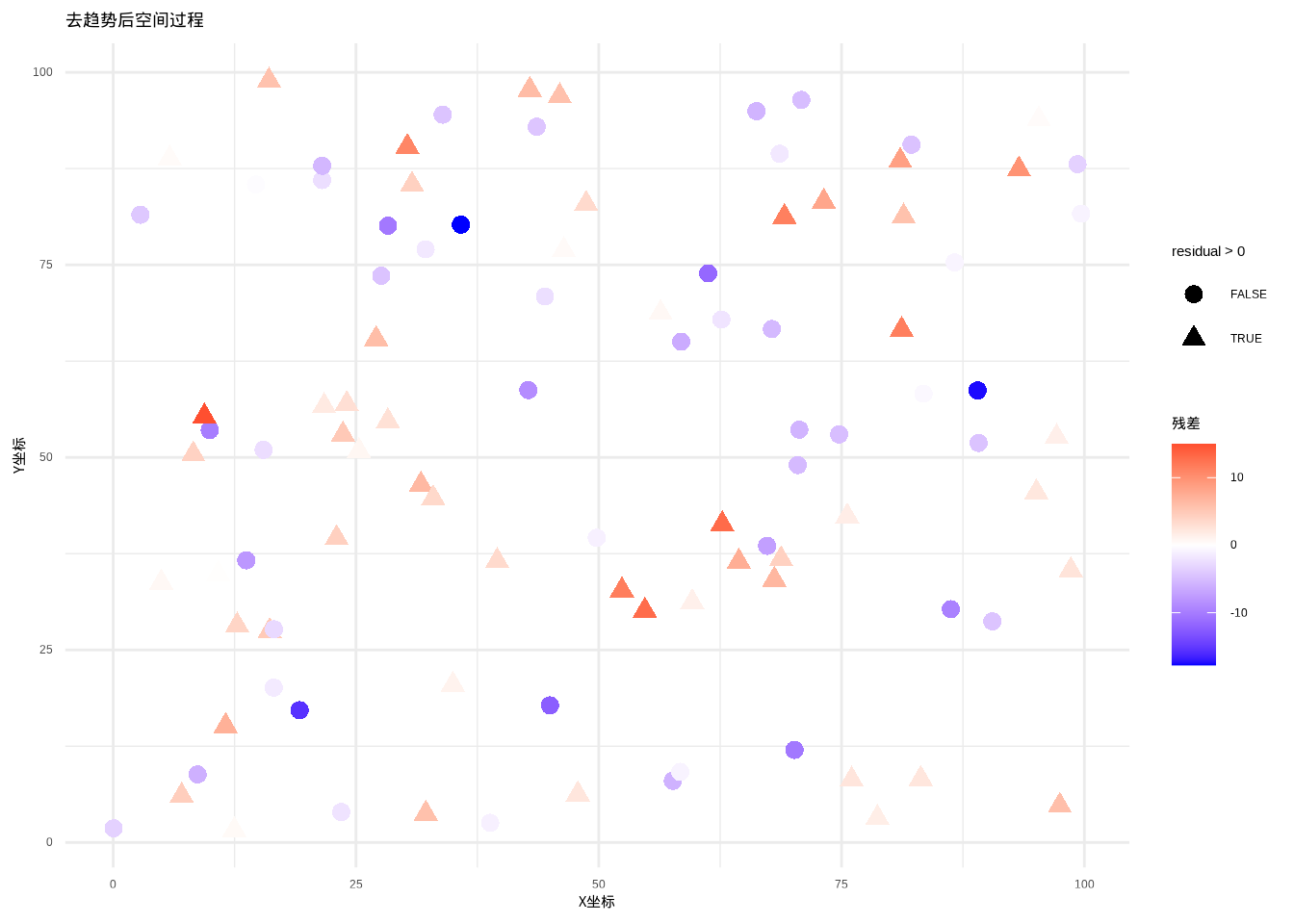
图5.34: 去趋势后的森林生物量空间分布,趋势成分已被去除。图中使用从蓝色到红色的颜色渐变表示残差大小,同时通过圆点和三角形的点型区分负残差和正残差
原始空间过程的变异函数(图5.35)显示持续上升的特征,这是非平稳空间过程的典型表现。
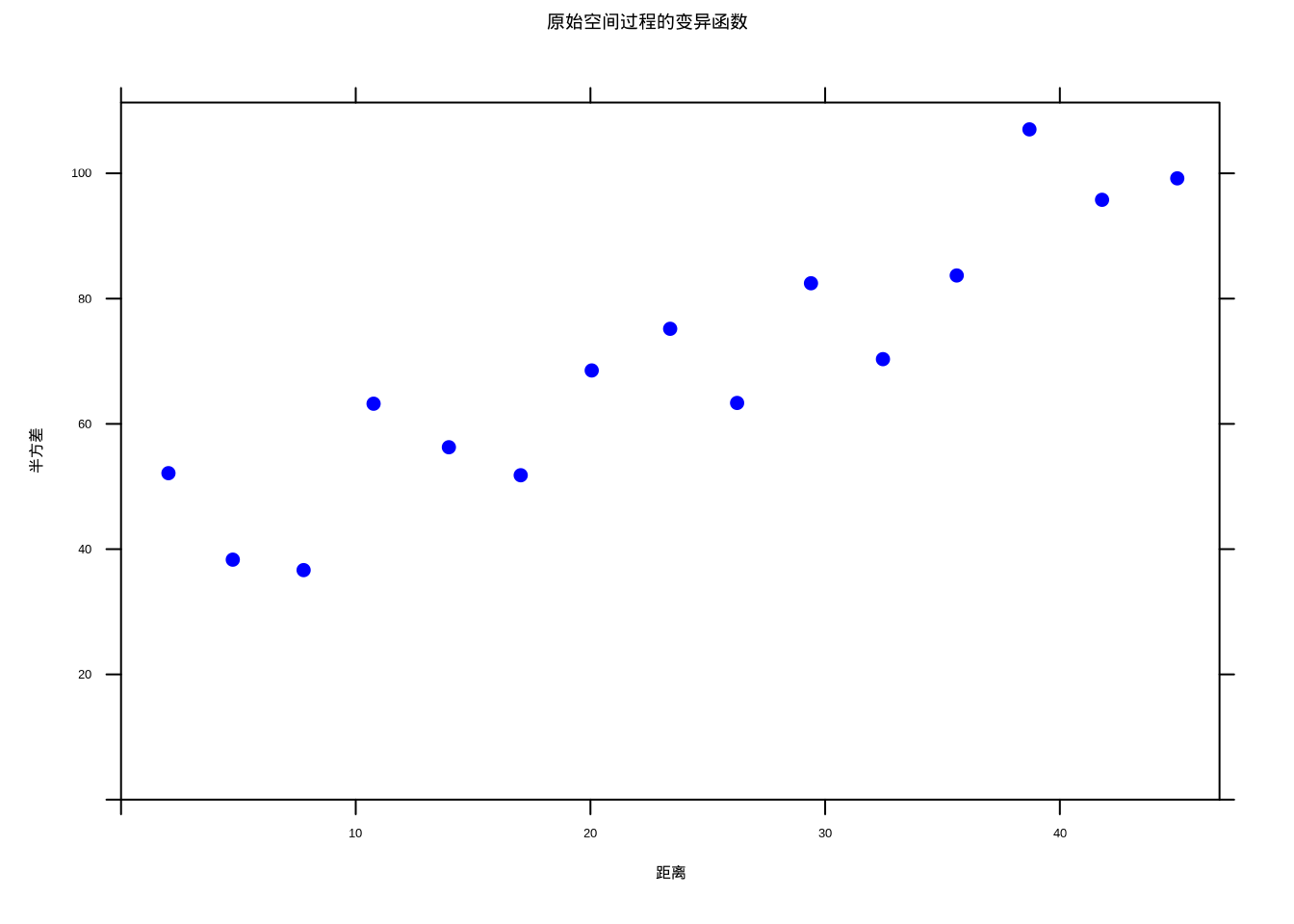
图5.35: 原始空间过程的变异函数,显示持续上升的非平稳特征
去趋势后空间过程的变异函数(图5.36)显示收敛到基台值的特征,表明过程已经达到平稳状态。
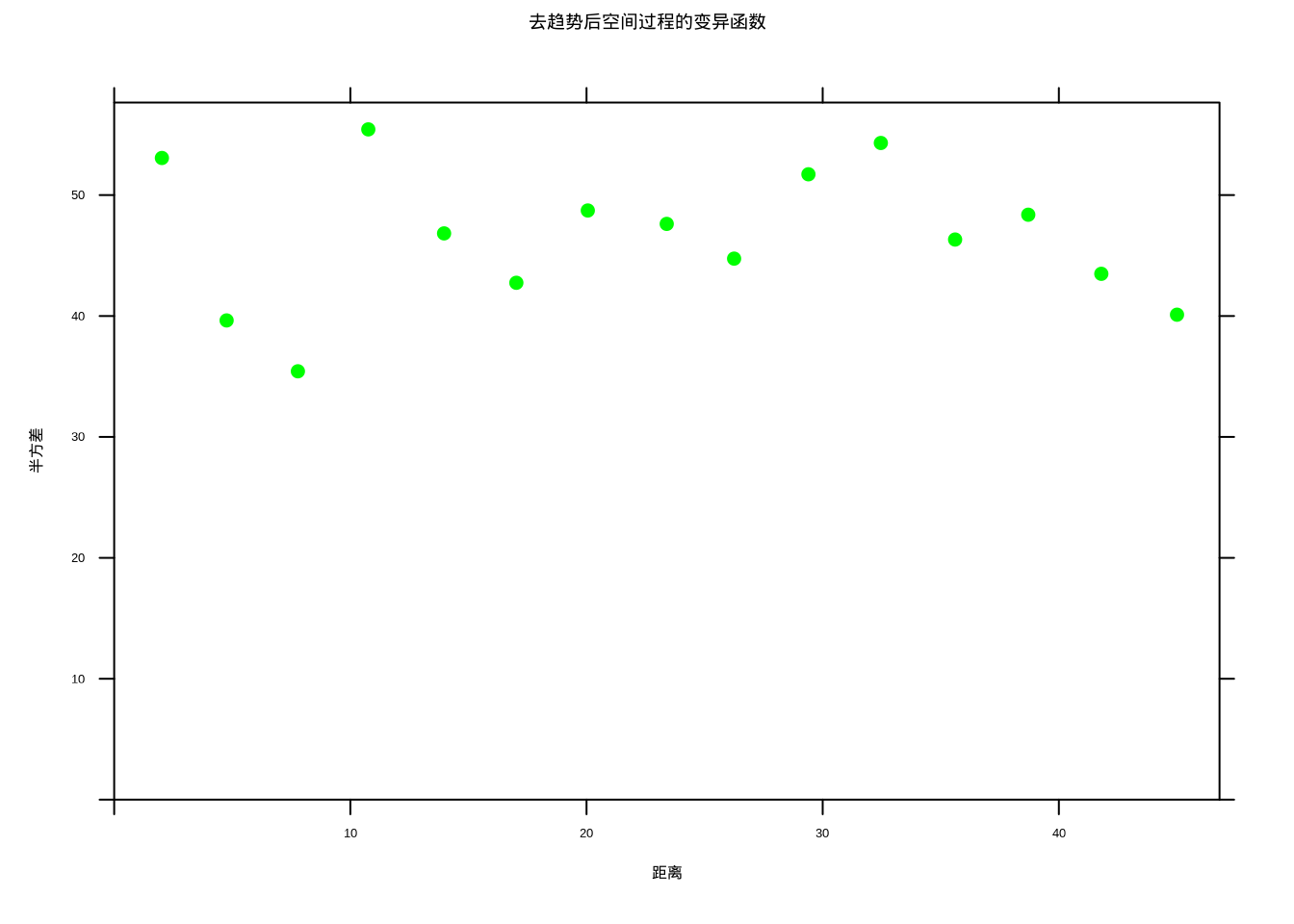
图5.36: 去趋势后空间过程的变异函数,显示收敛的平稳特征
图5.37展示了空间过程分解的结果,将原始过程分离为趋势成分和随机成分,帮助我们更好地理解空间过程的内在结构。
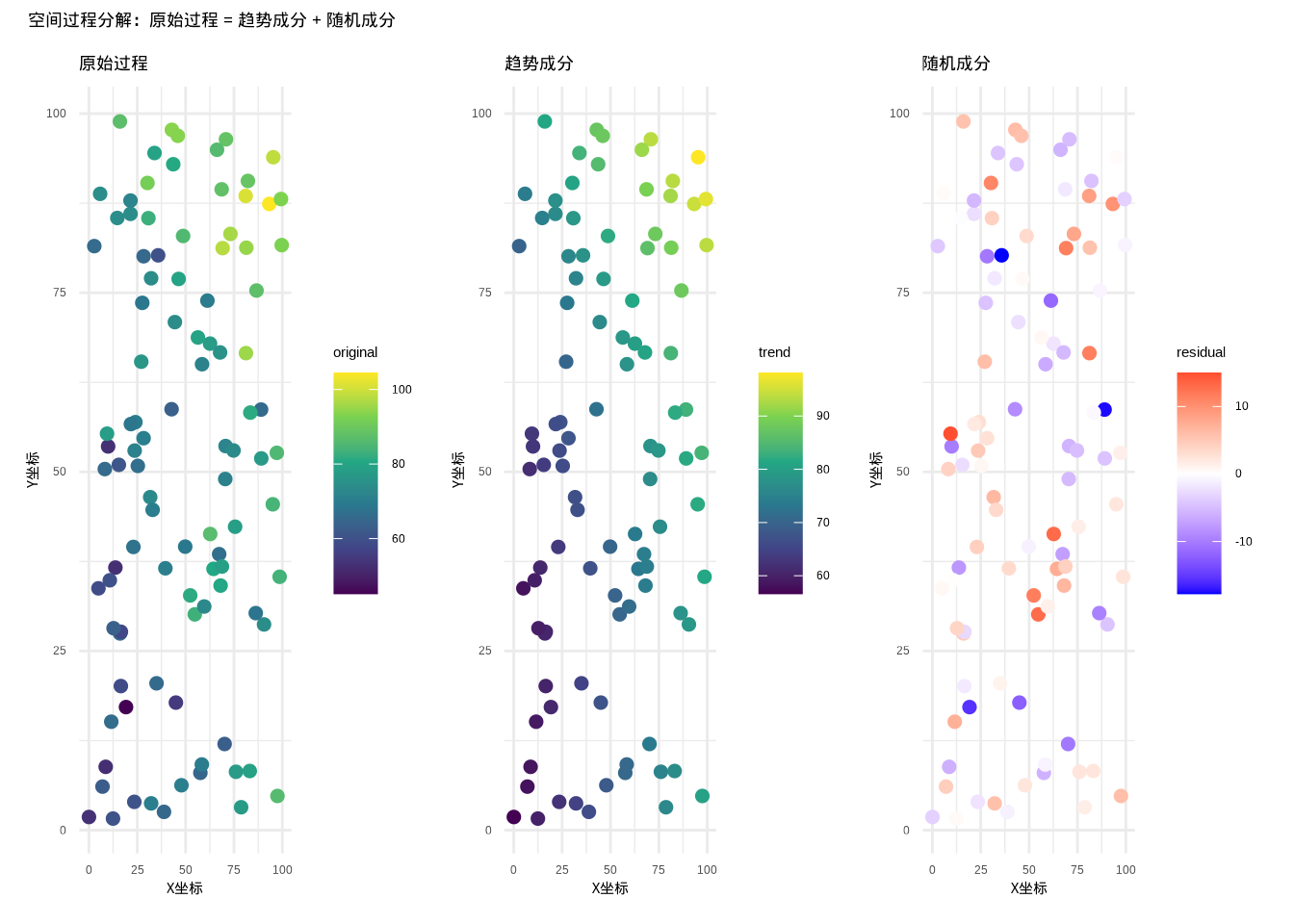
图5.37: 空间过程分解结果,展示趋势成分和随机成分的分离
5.6 系统发育相关性
系统发育相关性分析是进化生态学和比较生物学中的重要工具,用于研究物种间性状相关性时考虑其系统发育关系。由于物种共享进化历史,不同物种间的性状值往往存在非独立性,这种非独立性可能导致传统统计方法的偏差。通过整合系统发育信息,系统发育相关性分析能够区分性状间的生态关系和进化保守性,从而更准确地揭示性状的生态和进化意义。
5.6.1 系统发育信号:进化历史的印记
在研究不同植物物种的叶片性状时,我们想要了解这些性状在系统发育树(物种间进化关系的分支图)上的分布模式,即它们是否表现出系统发育信号——亲缘关系较近的物种是否具有相似的性状值。
系统发育信号是指性状在系统发育树上的分布模式,反映了性状的进化保守性程度。如果亲缘关系较近的物种具有相似的性状值,我们说该性状具有强烈的系统发育信号;如果性状值在系统发育树上随机分布,与亲缘关系无关,则系统发育信号较弱或不存在。系统发育信号的量化对于理解性状的进化动态和生态适应具有重要意义。
最常用的系统发育信号的度量指标是Blomberg’s K和Pagel’s \(\lambda\)。Blomberg’s K由Blomberg等人于2003年提出,它比较观测到的性状在系统发育树上的方差与其在布朗运动模型下的期望方差。K值等于1表示性状的进化完全符合布朗运动模型(中等系统发育信号);K值大于1表示性状比布朗运动模型预测的更保守(强系统发育信号);K值小于1表示性状比布朗运动模型预测的更趋同(弱系统发育信号)。K值的统计显著性通常通过置换检验来评估。
Pagel’s \(\lambda\)是由Pagel于1999年提出的另一个广泛使用的系统发育信号度量指标。\(\lambda\)度量系统发育树在解释性状变异中的相对重要性(即相关性的缩放因子)。\(\lambda\)值在0到1之间变化,其中0表示性状变异与系统发育无关(没有系统发育信号),1表示性状变异完全符合布朗运动模型下的系统发育相关性(强系统发育信号)。\(\lambda\)值可以通过最大似然法估计,并可以通过似然比检验来评估其统计显著性。
在生态学研究中,系统发育信号分析具有重要的应用价值。例如,在功能生态学中,系统发育信号分析可以帮助理解功能性状的进化保守性;在群落生态学中,它可以揭示群落构建中的系统发育过程;在保护生物学中,它可以指导基于系统发育多样性的保护策略。此外,系统发育信号分析还为系统发育比较方法提供了基础,确保生态关系的统计检验不受系统发育非独立性的影响。
数学定义:
- Blomberg’s K:
\[K = \frac{MS_{obs}}{MS_{random}}\]
上式为简化表达,其中\(MS_{obs}\)是性状观测值在系统发育树上的均方,\(MS_{random}\)是在布朗运动模型下的期望均方。实际计算时K反映了观测到的性状方差与布朗运动模型下期望方差的比值。
- Pagel’s \(\lambda\):
Pagel’s \(\lambda\)是一个介于0和1之间的指标,用于衡量性状在系统发育树上的进化保守性程度。\(\lambda\)=0表示性状进化完全独立于系统发育关系,即无系统发育信号);\(\lambda\)=1则表示性状进化遵循布朗运动模型,即强系统发育信号。
Pagel’s \(\lambda\)的数学模型为:
\[\mathbf{V} = \lambda\mathbf{C} + (1-\lambda)\mathbf{I}\]
其中\(\mathbf{V}\)是性状的协方差矩阵,\(\mathbf{C}\)是系统发育协方差矩阵(由系统发育树计算得到),\(\mathbf{I}\)是单位矩阵。\(\lambda\)的计算是通过缩放系统发育树的内部枝长进行实现的。
通过最大化似然函数来估计:
\[\ln L(\lambda) = -\frac{1}{2}[(n-1)\ln(2\pi) + \ln|\lambda\mathbf{C} + (1-\lambda)\mathbf{I}| + \mathbf{y}^T(\lambda\mathbf{C} + (1-\lambda)\mathbf{I})^{-1}\mathbf{y}]\]
其中\(\mathbf{C}\)是系统发育协方差矩阵,\(\mathbf{I}\)是单位矩阵,\(\mathbf{y}\)是性状向量。
R代码实现:
# 系统发育信号分析示例:植物叶片性状的系统发育保守性
library(ape)
library(phytools)
# 模拟系统发育树和性状数据
set.seed(123)
# 生成随机系统发育树(50个物种)
n_species <- 50
phy_tree <- rtree(n_species)
# 模拟具有系统发育信号的性状数据
# 使用布朗运动模型模拟保守性状
trait_conservative <- rTraitCont(phy_tree, model = "BM", sigma = 1)
# 模拟没有系统发育信号的性状数据(随机性状)
trait_random <- rnorm(n_species, mean = 0, sd = 1)
names(trait_random) <- phy_tree$tip.label
# 计算Blomberg's K, 并通过置换检验评估显著性
K_perm_conservative <- phylosig(phy_tree, trait_conservative,
method = "K", test = TRUE, nsim = 999)
K_perm_random <- phylosig(phy_tree, trait_random,
method = "K", test = TRUE, nsim = 999)
cat("Blomberg's K分析结果:\n",
"保守性状的K值:", round(K_perm_conservative$K, 3), "\n",
"随机性状的K值:", round(K_perm_random$K, 3), "\n",
sep = "")## Blomberg's K分析结果:
## 保守性状的K值:1.104
## 随机性状的K值:0.168cat("\n置换检验p值:\n",
"保守性状:", format.pval(K_perm_conservative$P, digits = 3), "\n",
"随机性状:", format.pval(K_perm_random$P, digits = 3), "\n",
sep = "")##
## 置换检验p值:
## 保守性状:0.001
## 随机性状:0.83# 计算Pagel's λ, 并通过似然比检验评估显著性
lambda_conservative <- phylosig(phy_tree, trait_conservative,
method = "lambda")
lambda_random <- phylosig(phy_tree, trait_random,
method = "lambda")
cat("\nPagel's λ分析结果:\n",
"保守性状的λ值:", round(lambda_conservative$lambda, 3), "\n",
"随机性状的λ值:", round(lambda_random$lambda, 3), "\n",
sep = "")##
## Pagel's λ分析结果:
## 保守性状的λ值:1
## 随机性状的λ值:0cat("\n似然比检验p值:\n",
"保守性状:", format.pval(lambda_conservative$P, digits = 3), "\n",
"随机性状:", format.pval(lambda_random$P, digits = 3), "\n",
sep = "")##
## 似然比检验p值:
## 保守性状:
## 随机性状: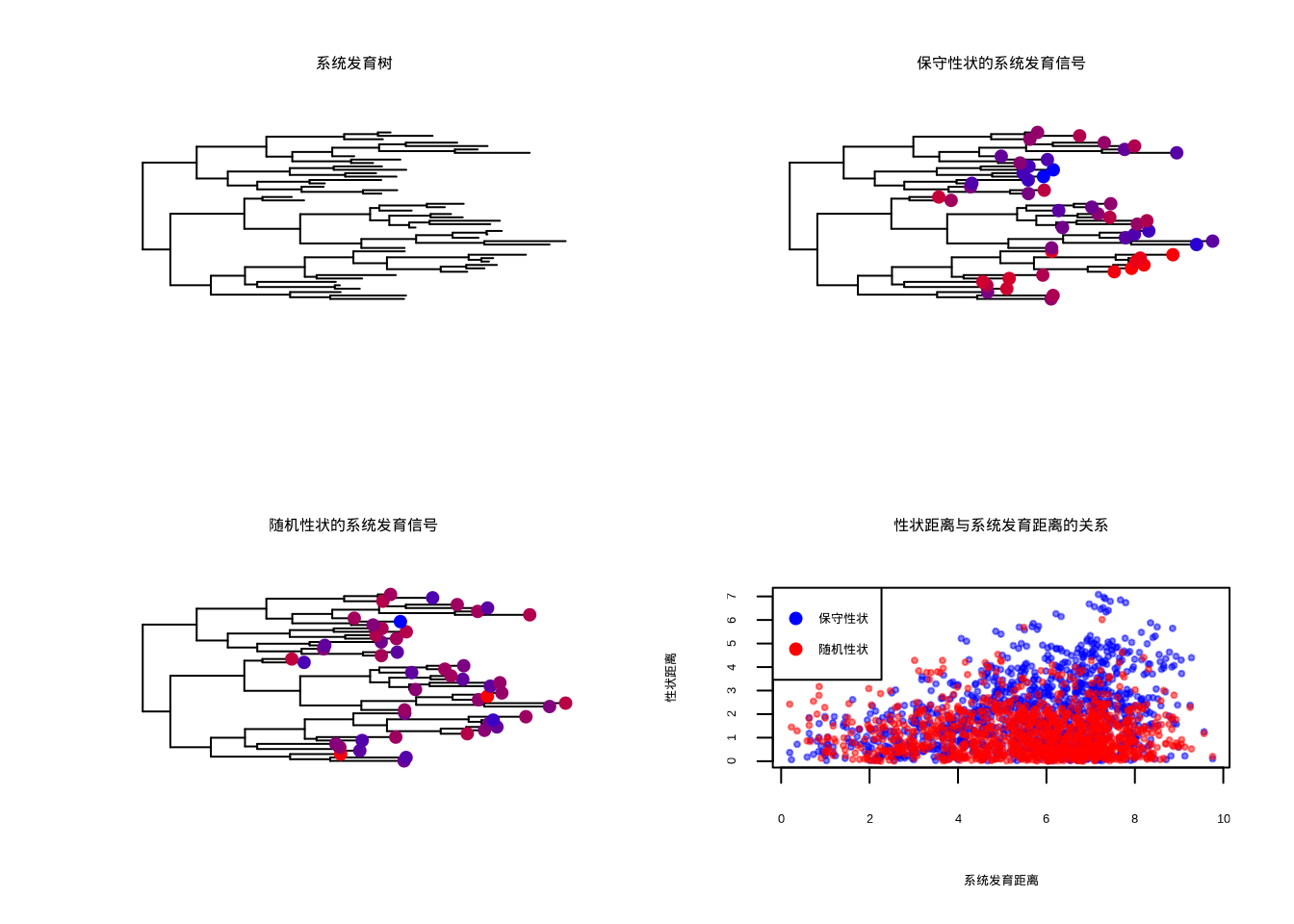
图5.38: 植物叶片性状的系统发育信号分析和性状距离关系
图5.38展示了植物叶片性状的系统发育信号分析和性状距离关系。该2×2组合图系统比较了保守性状和随机性状的系统发育模式:左上角显示系统发育树结构,右上角展示保守性状在系统发育树上的分布(蓝色到红色的颜色梯度表示性状值大小),左下角展示随机性状在系统发育树上的分布,右下角通过散点图比较性状距离与系统发育距离的关系(蓝色点表示保守性状,红色点表示随机性状)。保守性状显示明显的系统发育信号,亲缘关系近的物种具有相似的性状值;而随机性状在系统发育树上呈现随机分布模式。这种可视化方法对于理解性状的进化保守性、识别适应性进化的证据以及构建考虑系统发育关系的生态学模型具有重要价值。
##
## Mantel检验结果:
## 保守性状的Mantel r:0.337
## 保守性状的p值:0.001
## 随机性状的Mantel r:-0.021
## 随机性状的p值:0.659| 性状类型 | Bl | mberg_K| Pa | el_lambda| Ma | tel_r| |
|---|---|---|---|
| 保守性状 | | 1.104| | 1| | 0.337| |
| 随机性状 | | 0.168| | 0| | 0.021| |
表5.7比较了三种常用的系统发育信号度量方法(Blomberg’s K、Pagel’s λ和Mantel检验)在保守性状和随机性状上的表现。生态学意义:系统发育信号分析在生态学中广泛应用于检验性状的系统发育保守性,理解功能性状的进化动态,以及确保生态关系的统计检验不受系统发育非独立性的影响。
5.6.2 系统发育独立对比:去除系统发育影响的性状比较
在研究植物叶片氮含量与光合速率的关系时,我们需要考虑物种间的系统发育关系,因为亲缘关系较近的物种可能共享相似的性状值,这种系统发育非独立性可能使传统的相关性分析产生偏差。
系统发育独立对比(PIC)是Felsenstein于1985年提出的一种创新方法。它通过将系统发育树转化为一组独立的对比来消除系统发育非独立性对统计分析的影响。PIC的核心思想是:在系统发育树的每个节点,计算从该节点分化出的两个支系之间的性状差异。这些差异构成了系统发育独立对比。由于每个对比代表系统发育树上的一个独立进化事件,这些对比在统计上是独立的,因此可以安全地用于传统的统计检验,而不会受到系统发育非独立性的影响。
PIC的计算过程可以分为以下几个步骤:首先,从系统发育树的末端开始,逐步向树的根部计算每个节点的性状对比值;其次,对每个对比值进行标准化处理,以校正分支长度对结果的影响;最后,将这些标准化后的对比值用于回归分析、相关性分析或其他统计检验。一棵具有\(n\)个物种的系统发育树将生成\(n-1\)个独立的对比值。需要注意的是,PIC方法的一个重要假设是性状的进化过程符合布朗运动模型,即性状在系统发育树上的变化是随机的、无方向性的,因此两个物种间性状的差异与距离他们共同祖先的分化时间相关。
在生态学研究中,PIC方法具有极其重要的应用价值。它使得我们能够在控制系统发育关系的情况下,检验性状间的生态关系、评估环境对性状的影响、以及比较不同类群的进化速率。例如,在使用PIC分析叶片氮含量与光合速率的关系时,如果去除系统发育影响后两者仍然显著相关,说明这种关系具有普遍的生态意义,而不仅仅是系统发育历史的产物。PIC方法还广泛应用于比较生物学、进化生态学和功能生态学的研究中。
然而,PIC方法也存在一些局限性和注意事项。首先,它假设性状的进化过程符合布朗运动模型,这一假设可能无法适用于其他进化模型。其次,对于高度不平衡的系统发育树,PIC方法的表现可能不够理想。此外,PIC方法仅适用于连续性状的分析,无法直接处理分类性状。近年来,随着系统发育比较方法的不断发展,出现了更为先进的分析方法,例如系统发育广义最小二乘法(PGLS)。这些新方法在一定程度上克服了PIC的局限性,但PIC方法仍然是理解系统发育非独立性影响的基础工具。
数学原理:对于系统发育树上的一个节点,其两个子节点\(i\)和\(j\)的性状对比为:
\[contrast = \frac{x_i - x_j}{\sqrt{v_i + v_j}}\]
其中\(x_i\)和\(x_j\)是性状值,\(v_i\)和\(v_j\)是分支长度。这个标准化过程确保了所有对比值具有相同的尺度,并且理论上彼此独立且服从均值为0、标准差为1的正态分布(即布朗运动模型)。
R代码实现:
load("data/trait_data.RData")
# 传统相关性分析(忽略系统发育)
cor_traditional <- cor(trait_data[, 2:4])
knitr::kable(round(cor_traditional, 3),
caption = "传统相关性分析结果(忽略系统发育)",
booktabs = TRUE) %>%
kableExtra::kable_styling(latex_options = c("hold_position"))| nitrogen | photosynthesis | sla | |
|---|---|---|---|
| nitrogen | 1.000 | 0.497 | -0.967 |
| photosynthesis | 0.497 | 1.000 | -0.368 |
| sla | -0.967 | -0.368 | 1.000 |
# 进行相关性检验
cor_test_np <- cor.test(trait_data$nitrogen, trait_data$photosynthesis)
cor_test_ns <- cor.test(trait_data$nitrogen, trait_data$sla)##
## 传统相关性检验:
## 氮含量 vs 光合速率:r =0.497, p =0.00519
## 氮含量 vs 比叶重:r =-0.967, p =<2e-16# 计算PIC
pic_nitrogen <- pic(trait_nitrogen, phy_tree)
pic_photosynthesis <- pic(trait_photosynthesis, phy_tree)
pic_sla <- pic(trait_sla, phy_tree)
# PIC相关性分析
pic_cor_np <- cor.test(pic_nitrogen, pic_photosynthesis)
pic_cor_ns <- cor.test(pic_nitrogen, pic_sla)## PIC相关性检验:
## 氮含量 vs 光合速率:r =0.597, p =0.000635
## 氮含量 vs 比叶重:r =-0.92, p =1.78e-12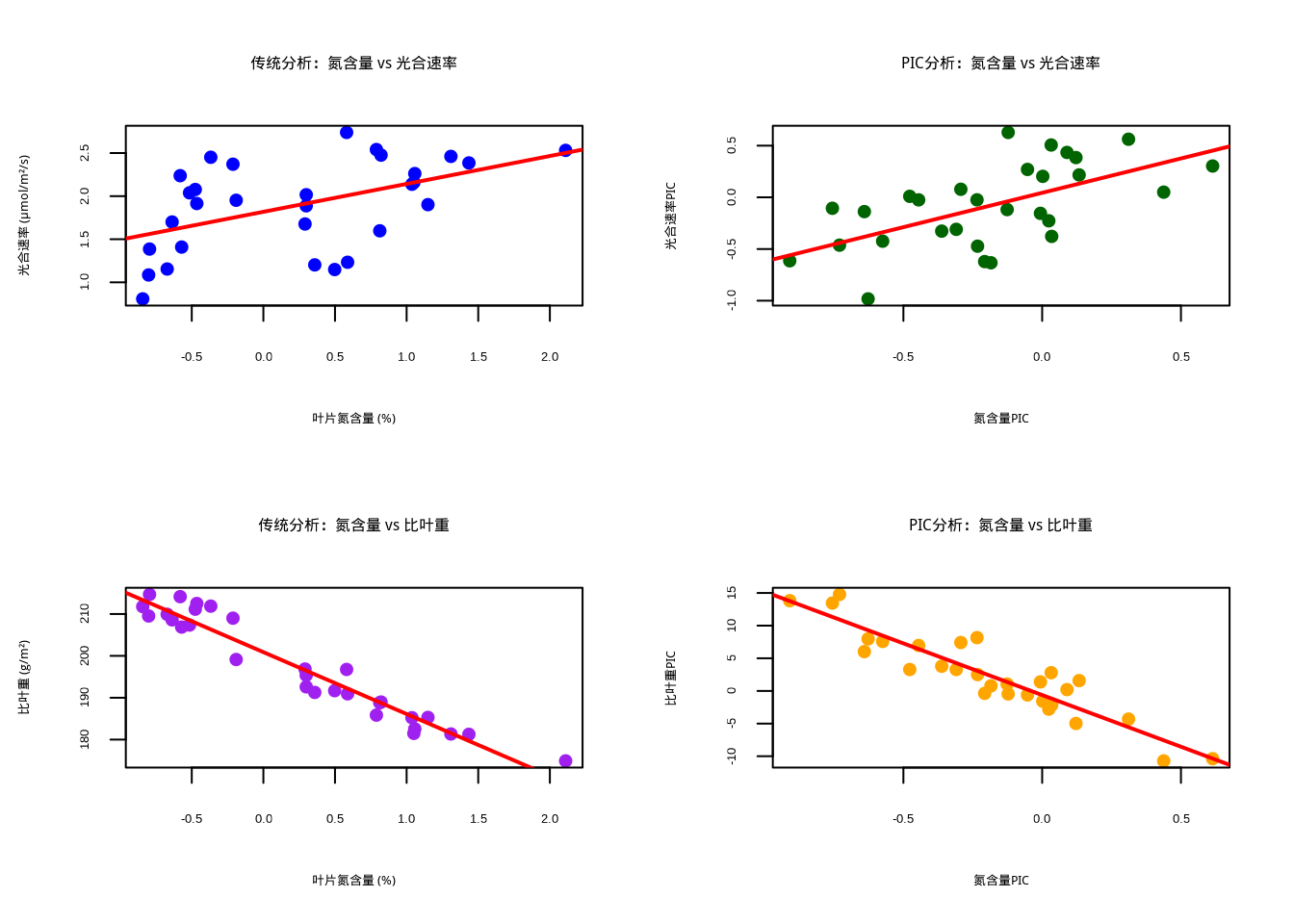
图5.39: 植物叶片性状的系统发育独立对比分析和性状关系
图5.39展示了植物叶片性状的系统发育独立对比分析和性状关系。该2×2组合图系统比较了传统分析和PIC分析在两种性状关系上的差异:第一行比较氮含量与光合速率的关系,第二行比较氮含量与比叶重的关系。左侧子图显示传统分析结果(蓝色和紫色散点),右侧子图显示PIC分析结果(深绿色和橙色散点),红色直线表示线性回归拟合。PIC分析通过去除系统发育非独立性,能够更准确地评估性状间的进化相关性,避免因物种间亲缘关系导致的统计偏差。这种对比可视化方法对于理解性状关系的进化基础、识别真正的功能权衡以及构建考虑系统发育历史的生态学模型具有重要价值。
## 关系 传统_r 传统_p PIC_r PIC_p
## 1 氮含量-光合速率 0.4971 0.0052 0.5966 6e-04
## 2 氮含量-比叶重 -0.9670 0.0000 -0.9197 0e+00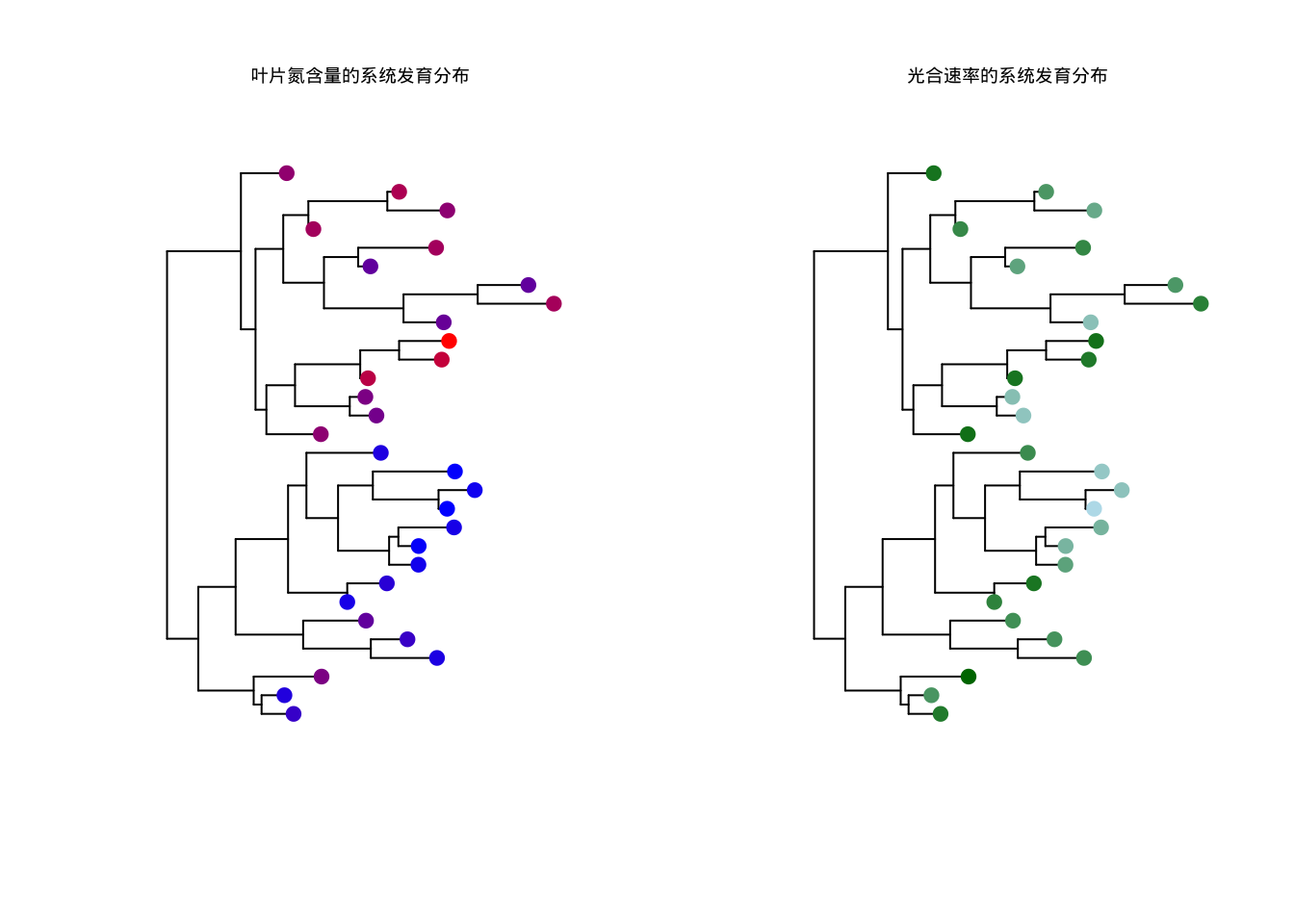
图5.40: 植物叶片性状的系统发育分布
图5.40展示了植物叶片性状的系统发育分布。该代码首先比较了传统分析和PIC分析的结果,然后通过双面板系统发育树可视化展示了氮含量和光合速率在物种间的分布模式。左侧子图显示叶片氮含量的系统发育分布(蓝色到红色颜色梯度),右侧子图显示光合速率的系统发育分布(浅蓝色到深绿色颜色梯度)。这种可视化方法能够直观地展示性状在系统发育树上的保守性模式,亲缘关系近的物种如果具有相似的颜色,表明该性状具有较强的系统发育信号。同时,代码还提供了PGLS分析的示例说明,为读者进一步探索系统发育广义最小二乘法提供了参考。这种综合分析方法对于理解植物功能性状的进化保守性、识别适应性进化事件以及构建准确的系统发育生态学模型具有重要价值。
生态学意义:系统发育独立对比分析在生态学中至关重要,它确保了性状间生态关系的统计检验不受系统发育非独立性的影响,为正确理解性状的进化关系和生态功能提供了可靠的方法。
5.6.3 群落系统发育结构:聚集与分散
在生态学中,尤其是群落生态学中,我们不仅关心单个性状在系统发育上的保守性,也关心群落中物种的系统发育关系——即群落中共存物种在系统发育上是“亲缘较近”还是“亲缘较远”。这种系统发育层面的群落结构被称为群落的系统发育结构。
如果群落中的物种在系统发育上与零模型的随机化结果(即保持物种丰富度但随机替换不同群落的物种)相比亲缘关系更近,我们称该群落表现出系统发育聚集;相反,如果群落中的物种与随机化结果相比亲缘关系更远,则表现为系统发育分散。这两种模式通常分别反映不同的生态过程:
- 系统发育聚集:可能由环境过滤导致,即某些生境条件筛选出具有相似生态适应(往往系统发育相关)的物种;
- 系统发育分散:可能由竞争排除导致,即系统发育较近、生态位相似的物种难以共存。
数学原理: 群落系统发育结构常通过两个距离型指标描述,包括群落中所有物种间平均系统发育距离(MPD)和每个物种到其系统发育上最近的亲缘物种的平均距离(MNTD)。通常计算这两个指标的标准化形式(NRI和NTI),即观测值与多个随机群落的结果比较:
\[ \mathrm{NRI} = -\frac{(MPD_{obs} - MPD_{random})}{SD(MPD_{random})} \]
\[ \mathrm{NTI} = -\frac{(MNTD_{obs} - MNTD_{random})}{SD(MNTD_{random})} \]
其中:
- \(MPD_{obs}\)和\(MNTD_{obs}\) 为观测群落的平均系统发育距离;
- \(MPD_{random}\)和\(MNTD_{random}\) 是随机群落的两个指标的期望值(即零模型均值);
- \(SD\):零模型中随机化结果的标准差。
若NRI或NTI为正,即群落内的物种亲缘关系比随机化结果更相近,表示群落系统发育的聚集格局;若为负,即群落内的物种亲缘关系比随机化结果更远,表示群落系统发育的分散格局。
R代码实现:
library(picante)
library(ape)
load(file = "data/phy_comm.Rdata")
# 计算群落的系统发育结构的标准化指标
mpd_values <- ses.mpd(comm, cophenetic(phy_tree),
null.model = "taxa.labels", runs = 999)
mntd_values <- ses.mntd(comm, cophenetic(phy_tree),
null.model = "taxa.labels", runs = 999)
# 整理输出结果
result <- data.frame(
Site = rownames(comm),
NRI = -mpd_values$mpd.obs.z,
NTI = -mntd_values$mntd.obs.z
)
print(result)## Site NRI NTI
## 1 Site1 1.02630492 0.5759223
## 2 Site2 0.69010548 1.4726145
## 3 Site3 0.50793073 1.3863466
## 4 Site4 -0.72467623 0.5160018
## 5 Site5 -0.55059304 -0.6980107
## 6 Site6 0.07059204 0.9496677
## 7 Site7 -0.67408678 -1.2842739
## 8 Site8 -0.80224246 1.0089508
## 9 Site9 3.05853943 2.8528234
## 10 Site10 1.46826954 -0.5272649生态学意义:通过分析系统发育聚集与分散,研究者能够推断群落形成的主导机制,理解生态位分化与共存模式,为生物多样性维持和生态系统功能研究提供重要的进化视角。同样的分析思路可延伸至功能性状数据,通过揭示性状的聚集与发散,直接验证驱动群落组装的生态过程。
5.7 生态相似性与距离度量
在前面的小节中,我们主要讨论了变量间的数值相关性——无论是线性相关、非线性相关,还是时间或空间上的自相关。这些分析关注的是变量间关系的强度和方向。现在,我们将转向一个相关但不同的概念:相似性与距离。
相似性分析的核心是量化不同样本、群落或个体之间的相似程度或差异大小。与相关性分析不同,相似性分析更关注分类、比较和排序,而非变量间的函数关系。在生态学中,相似性分析广泛应用于群落分类、物种分布格局研究、功能性状比较以及生态区划等场景。
相似性分析与相关性分析既有联系又有区别:相关性通常度量变量间的协变关系,而相似性则度量样本间的整体差异;相关性分析通常基于连续变量的数值计算,而相似性分析可以处理二元数据、分类数据和数量数据;相关性分析的结果是相关系数,而相似性分析的结果是相似性系数或距离矩阵。
本小节将从基础到应用,系统介绍生态学中常用的相似性系数和距离度量方法,包括二元数据相似性、数量数据相似性、功能性状相关性、种内和种间相关性,以及群落相似性分析的综合方法。
5.7.1 常用相似性系数
在生态学研究中,群落相似性分析是理解物种分布格局、群落构建机制以及环境梯度影响的关键工具。生态学家经常面临如何量化不同样地或群落之间相似程度的问题,这需要根据数据类型和研究目的选择合适的相似性系数。
二元数据相似性:当生态数据仅记录物种存在与否时(如植物名录、动物分布记录),二元相似性系数是理想的选择。Jaccard系数是最经典的二元相似性度量,它计算两个群落共享物种数量占所有物种数量的比例,特别适用于比较物种组成相似性。其数学定义为:\(J = \frac{a}{a+b+c}\),其中\(a\)为两个群落共有的物种数,\(b\)和\(c\)分别为各自特有的物种数。Sørensen系数则对物种丰富度更为敏感,其定义为:\(S = \frac{2a}{2a+b+c}\),在生态学调查中广泛用于评估\(\beta\)多样性。这些系数在保护生物学中尤为重要,例如评估不同保护区的物种重叠程度,或者在恢复生态学中监测群落演替过程中的物种组成变化。
数量数据相似性:当生态数据包含物种多度信息时(如个体数量、生物量、盖度等),数量相似性系数能更准确地反映群落结构差异。Bray-Curtis距离是最常用的数量相似性度量,它考虑了物种的相对多度差异,对稀有物种不敏感而对常见物种变化敏感,非常适合分析群落梯度变化。其数学定义为:\(BC = 1 - \frac{2\sum \min(x_i, y_i)}{\sum x_i + \sum y_i}\),其中\(x_i\)和\(y_i\)分别表示两个群落中第\(i\)个物种的多度。Morisita-Horn指数则对优势物种特别敏感,能有效识别群落中的优势种变化模式,在分析人为干扰或环境压力对群落结构的影响时具有独特优势。这些数量相似性系数在环境监测、污染生态学和全球变化生态学研究中广泛应用。
距离度量:除了专门的生态学相似性系数,传统的统计距离度量在多元生态数据分析中也发挥重要作用。欧氏距离是最基础的几何距离,计算样本在多维空间中的直线距离,适用于环境因子数据的比较分析。Mahalanobis距离则考虑了变量间的协方差结构,能更准确地反映多元数据的真实差异,在生态位分析和环境梯度研究中特别有用。这些距离度量为生态学家提供了量化样本间差异的数学工具,支持各种多元统计分析方法如聚类分析、排序分析和判别分析的实施。
在R语言中,这些相似性系数的计算非常便捷。对于二元数据,可以使用vegan包中的vegdist函数计算Jaccard和Sørensen系数:
library(vegan)
# 创建示例二元数据
binary_data <- matrix(c(1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0, 1), nrow = 3)
rownames(binary_data) <- c("样地A", "样地B", "样地C")
colnames(binary_data) <- c("物种1", "物种2", "物种3", "物种4")
# 计算Jaccard相似性
jaccard_dist <- vegdist(binary_data, method = "jaccard", binary = TRUE)
# 计算Sørensen相似性
sorensen_dist <- vegdist(binary_data, method = "bray", binary = TRUE)对于数量数据,Bray-Curtis距离的计算同样使用vegdist函数:
# 创建示例数量数据
abundance_data <- matrix(c(10, 5, 0, 2, 8, 3, 15, 1, 0, 7, 4, 12),
nrow = 3)
rownames(abundance_data) <- c("群落A", "群落B", "群落C")
colnames(abundance_data) <- c("物种1", "物种2", "物种3", "物种4")
# 计算Bray-Curtis距离
bray_curtis_dist <- vegdist(abundance_data, method = "bray")传统距离度量的计算可以使用基础R函数:
# 计算欧氏距离
euclidean_dist <- dist(abundance_data, method = "euclidean")
# 计算Mahalanobis距离(需要协方差矩阵)
cov_matrix <- cov(abundance_data)
# Mahalanobis距离计算较为复杂,通常用于多元统计分析结果解释与生态学意义:理解相似性系数的数值含义对于正确解释生态学结果至关重要。对于相似性系数(如Jaccard、Sørensen),数值范围在0到1之间,数值越大表示群落间相似性越高。通常认为:\(J > 0.75\)表示高度相似,\(0.5 < J \leq 0.75\)表示中等相似,\(J \leq 0.5\)表示低度相似。对于距离系数(如Bray-Curtis、欧氏距离),数值范围也在0到1之间(Bray-Curtis)或0到无穷大(欧氏距离),但数值越大表示差异越大。Bray-Curtis距离\(BC < 0.3\)通常表示群落结构相似,\(0.3 \leq BC < 0.6\)表示中等差异,\(BC \geq 0.6\)表示显著差异。
在实际生态学研究中,相似性系数的解释需要考虑研究背景和生态学预期。例如,在环境梯度研究中,沿着梯度方向相似性系数的规律性变化可能反映了环境过滤的作用;在岛屿生物地理学中,距离主岛越远的岛屿与主岛的相似性越低,可能反映了扩散限制的影响。这些相似性系数和距离度量为生态学家提供了强大的工具来量化群落间的相似性和差异性,支持后续的聚类分析、排序分析等多元统计方法。
5.7.2 功能性状间相关性
功能性状相关性分析是功能生态学的核心内容,旨在揭示植物和其他生物在进化过程中形成的性状组合模式。这些相关模式反映了生物对环境适应的策略性选择,是理解生态位分化、群落构建和生态系统功能的关键。
功能性状相关性:功能性状间的相关性分析主要关注两个重要方面:性状间的权衡关系和协变模式。性状权衡是指生物在资源有限条件下,对多个功能性状进行权衡取舍的进化策略。例如,植物在叶片构建上需要在光合速率和防御能力之间进行权衡,快速生长的物种通常具有较低的防御投资。这种权衡关系可以用负相关关系来表示,其数学表达即为Peason相关系数:\(r_{xy} = \frac{\sum (x_i - \bar{x})(y_i - \bar{y})}{\sqrt{\sum (x_i - \bar{x})^2 \sum (y_i - \bar{y})^2}}\),其中\(x_i\)和\(y_i\)分别表示第\(i\)个个体在两个性状上的测量值。
功能性状的协变模式则描述了多个性状如何协同变化,形成特定的功能综合征。例如,在干旱环境中,植物往往同时表现出深根系、厚角质层和小叶面积等性状组合。这些协变模式可以通过主成分分析或多变量回归等方法进行量化。生态学上,这些相关性反映了生物对不同环境压力的适应机制,如资源获取策略、胁迫耐受策略和竞争策略等。在群落生态学中,功能性状相关性分析有助于理解物种共存机制和生态系统稳定性。
经济型谱:经济型谱理论是功能生态学的重要框架,描述了生物在资源投资和收益之间的权衡关系。叶片经济型谱是最经典的经济型谱,它揭示了叶片性状在全球尺度上的协变规律。具体表现为叶片氮含量、比叶面积与光合速率之间的正相关关系,以及与叶片寿命之间的负相关关系。这种权衡反映了植物在快速资源获取和长期资源保存之间的策略选择,其数学关系可以用线性或非线性回归模型来描述:\(y = \beta_0 + \beta_1x + \epsilon\)。
根系经济型谱则描述了根系功能性状的协变模式,涉及细根直径、根组织密度、根寿命等性状。通常,快速资源获取型的根系具有较细的直径、较低的组织密度和较短的寿命,而资源保存型的根系则相反。这些经济型谱的发现为理解植物功能策略的普遍模式提供了理论基础,在全球变化生态学、生物地理学和生态系统管理中具有重要应用价值。它们帮助我们预测植物群落对气候变化和人为干扰的响应,以及生态系统功能的变化趋势。
在R语言中,功能性状相关性分析可以通过多种统计方法实现。图??展示了功能性状相关性矩阵的可视化和主成分分析结果:
| 比叶面积| 叶片 | 含量| 光合速率| | 叶片寿命| | ||
|---|---|---|---|---|
| 比叶面积 | 1 | 0000000| 0 | 9964051| 0 | 9906672| -0 | 9740756| |
| 叶片氮含量 | 0. | 964051| 1. | 000000| 0. | 821403| -0. | 647267| |
| 光合速率 | 0 | 9906672| 0 | 9821403| 1 | 0000000| -0 | 9951811| |
| 叶片寿命 | -0 | 9740756| -0 | 9647267| -0 | 9951811| 1 | 0000000| |
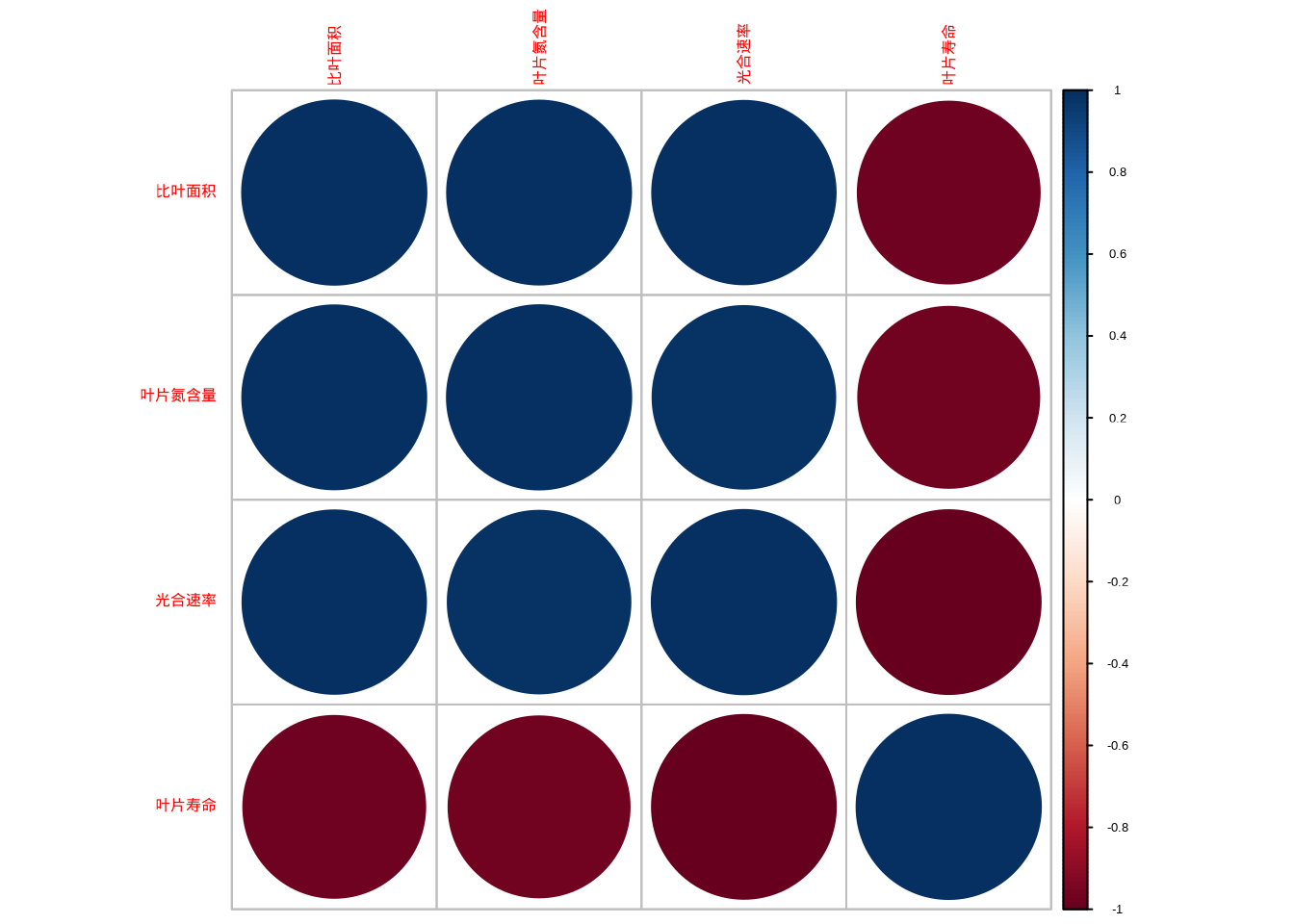
图5.41: 功能性状相关性矩阵图和主成分分析双标图
| 主成分 | 标 | 差| 方差比例 | 累积方差比例| | ||
|---|---|---|---|---|
| PC1 | PC1 | 1.988 | 0.988 | 0.988 |
| PC2 | PC2 | 0.211 | 0.011 | 0.999 |
| PC3 | PC3 | 0.059 | 0.001 | 1.000 |
| PC4 | PC4 | 0.015 | 0.000 | 1.000 |
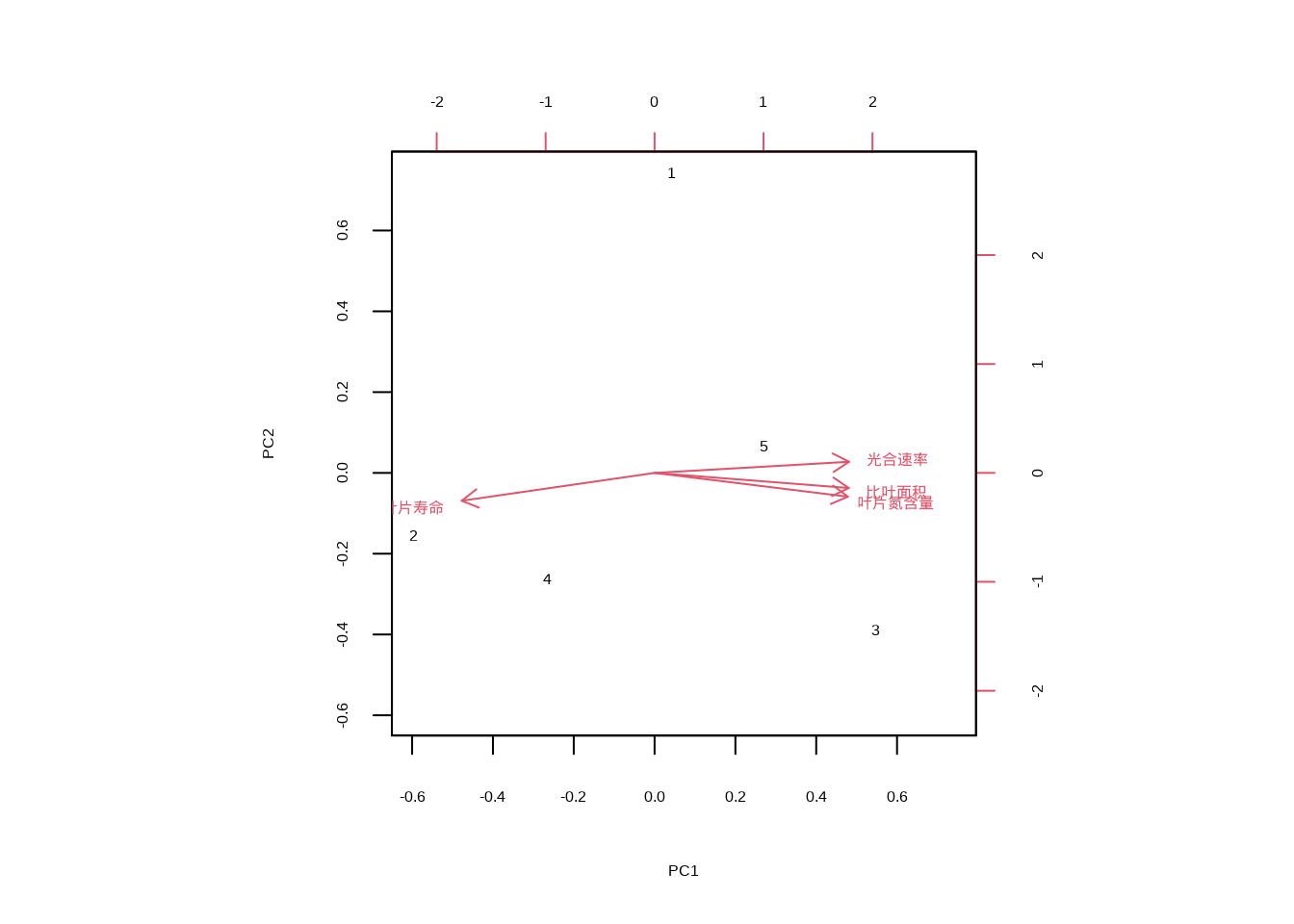
图5.42: 功能性状相关性矩阵图和主成分分析双标图
对于经济型谱分析,可以使用线性模型来检验性状间的权衡关系。图5.43展示了叶片经济型谱关系的散点图:
| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 3.6704042 | 0.6898330 | 5.320714 | 0.0129693 |
| 比叶面积 | 0. | 367956| 0 | 0426408| 12 | 588774| | 0.0010808| |
| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 20.9853325 | 1.6234494 | 12.926385 | 0.0009994 |
| 比叶面积 | -0 | 7484065| 0 | 1003507| -7 | 457912| | 0.0049911| |
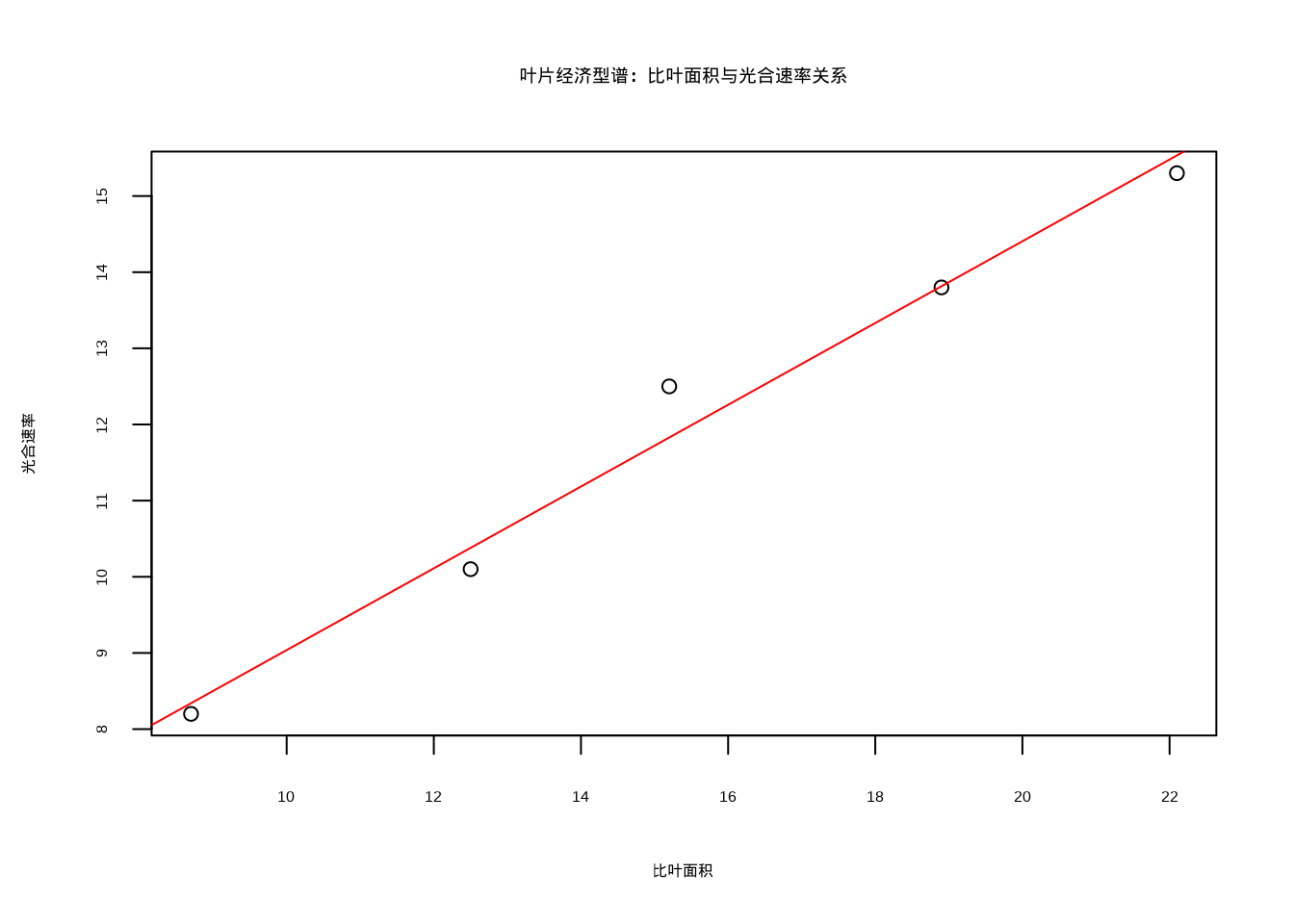
图5.43: 叶片经济型谱关系散点图
结果解释与生态学意义:功能性状相关性分析的结果解释需要结合相关系数的数值大小、显著性水平和生态学背景。相关系数\(r\)的绝对值大小反映了性状间关系的强度:\(|r| > 0.7\)表示强相关,\(0.5 < |r| \leq 0.7\)表示中等相关,\(0.3 < |r| \leq 0.5\)表示弱相关,\(|r| \leq 0.3\)表示无实质性相关。相关系数的正负号指示了关系的方向:正相关表示性状间协同变化,负相关表示性状间存在权衡关系。
在生态学解释中,显著的正相关可能反映了功能综合征的存在,如快速生长策略相关的性状组合;显著的负相关则可能指示资源分配上的权衡,如在防御和生长之间的投资权衡。主成分分析中,前几个主成分的方差贡献率反映了数据的主要变异方向,通常认为累计方差贡献率超过70%的主成分能够较好地代表原始数据的变异结构。这些分析方法为生态学家提供了强大的工具来量化功能性状间的相关模式,揭示生物适应策略的普遍规律。
5.7.3 种内相关性
种内相关性分析关注同一物种个体在空间上的分布模式及其形成机制,是理解种群生态学过程和环境适应策略的重要工具。空间分布模式反映了物种的繁殖特性、扩散能力以及对环境异质性的响应。
空间分布模式:物种的空间分布主要有三种基本模式:聚集分布、随机分布和均匀分布。聚集分布表现为个体在某些区域集中分布,形成斑块状格局,这通常由有限的种子扩散、克隆生长、环境异质性或社会行为等因素导致。其数学描述可以通过空间点过程模型来表示,如泊松聚类过程。随机分布则表现为个体在空间上无规律地分布,符合完全空间随机性假设,数学上可以用齐次泊松过程来描述:\(P(N(A)=k) = \frac{(\lambda|A|)^k e^{-\lambda|A|}}{k!}\),其中\(\lambda\)为强度参数,\(|A|\)为区域面积。均匀分布表现为个体在空间上等距分布,通常由强烈的种内竞争或领地行为导致。
这些分布模式的生态学意义在于它们反映了种内相互作用和环境异质性的综合影响。聚集分布常见于依赖母树扩散的植物物种或具有社会行为的动物种群;随机分布通常出现在环境均质且个体间无相互作用的条件下;均匀分布则多见于资源竞争激烈的环境中。
聚集指数:为了量化空间分布模式,生态学家开发了多种聚集指数。方差均值比是最基础的聚集度检验方法,其定义为:\(I = \frac{s^2}{\bar{x}}\),其中\(s^2\)为样本方差,\(\bar{x}\)为样本均值。当\(I > 1\)时表示聚集分布,\(I = 1\)时表示随机分布,\(I < 1\)时表示均匀分布。Morisita指数是另一种常用的空间聚集度量,其定义为:\(I_\delta = n \frac{\sum x_i(x_i-1)}{N(N-1)}\),其中\(n\)为样方数,\(x_i\)为第\(i\)个样方中的个体数,\(N\)为总个体数。Morisita指数对样本大小不敏感,在生态学调查中应用广泛。
这些聚集指数的生态学意义在于它们能够量化种内空间分布模式,为理解种群动态、资源利用策略和种内竞争提供定量依据。在保护生物学中,聚集指数有助于评估物种的生存状况和制定有效的保护策略。
在R语言中,种内空间分布分析可以通过以下方法实现:
# 创建示例空间分布数据
spatial_data <- c(3, 7, 2, 8, 1, 9, 4, 6, 2, 5) # 10个样方中的个体数
# 计算方差均值比
mean_count <- mean(spatial_data)
variance_count <- var(spatial_data)
variance_mean_ratio <- variance_count / mean_count
print(paste("方差均值比:", variance_mean_ratio))## [1] "方差均值比: 1.60992907801418"# 计算Morisita指数
n_quadrats <- length(spatial_data)
total_individuals <- sum(spatial_data)
numerator <- n_quadrats * sum(spatial_data * (spatial_data - 1))
denominator <- total_individuals * (total_individuals - 1)
morisita_index <- numerator / denominator
print(paste("Morisita指数:", morisita_index))## [1] "Morisita指数: 1.11933395004625"# 判断分布模式
if (variance_mean_ratio > 1.2) {
print("分布模式:聚集分布")
} else if (variance_mean_ratio < 0.8) {
print("分布模式:均匀分布")
} else {
print("分布模式:随机分布")
}## [1] "分布模式:聚集分布"结果解释与生态学意义:空间分布模式的分析结果需要结合聚集指数的数值和统计显著性来解释。方差均值比\(I\)的判断标准为:\(I > 1.2\)表示聚集分布,\(0.8 \leq I \leq 1.2\)表示随机分布,\(I < 0.8\)表示均匀分布。Morisita指数的判断标准类似:\(I_\delta > 1\)表示聚集分布,\(I_\delta = 1\)表示随机分布,\(I_\delta < 1\)表示均匀分布。
在生态学解释中,聚集分布通常指示存在环境异质性、有限的扩散能力或社会行为;随机分布可能出现在环境均质且个体间无相互作用的条件下;均匀分布则通常由强烈的种内竞争导致。这些分布模式的识别对于理解种群动态、设计抽样方案和制定保护策略具有重要意义。例如,对于聚集分布的物种,保护措施需要关注其核心分布区;对于均匀分布的物种,则需要考虑其竞争机制和资源利用策略。这些分析方法为生态学家提供了量化种内空间分布模式的工具,支持种群生态学和保护生物学研究。
5.7.4 种间相关性
种间相关性分析是群落生态学的核心内容,旨在揭示不同物种在空间分布、资源利用和生态功能上的相互关系。这些关系反映了物种间的竞争、互利、捕食等生态过程,是理解群落构建机制和生态系统稳定性的关键。
种间关联:种间关联主要分为三种类型:正相关、负相关和不相关。正相关表现为两个物种在空间上倾向于共同出现,这可能源于互利共生关系、相似的环境需求或共同的扩散限制。数学上可以用相关系数或关联指数来量化:\(\phi = \frac{ad-bc}{\sqrt{(a+b)(c+d)(a+c)(b+d)}}\),其中\(a,b,c,d\)为2×2列联表中的频数。负相关则表现为两个物种在空间上相互排斥,通常由竞争排斥、化感作用或不同的生态位需求导致。不相关则表示两个物种的分布相互独立,没有显著的生态联系。
这些关联模式的生态学意义在于它们反映了物种间相互作用的性质和强度。正相关可能指示物种间的协同进化或生态位重叠,负相关则暗示强烈的竞争或生态位分化。在恢复生态学中,种间关联分析有助于设计合理的物种配置方案;在保护生物学中,它有助于识别关键物种和功能群。
生态网络构建:基于种间相关性可以构建生态网络,从而可视化物种间相互作用的复杂结构。网络构建通常基于相关性矩阵,通过设定阈值将显著的相关关系转化为网络边。网络拓扑特征分析包括度分布、聚类系数、模块性等指标的计算。度分布描述了物种连接数的分布规律,数学上可以用幂律分布\(P(k) \sim k^{-\gamma}\)来拟合。聚类系数衡量了网络中三角形的比例,反映了物种间相互作用的局部聚集性。模块性则量化了网络被划分为相对独立模块的程度。
这些网络特征的生态学意义在于它们揭示了物种间相互作用的结构特性。高度模块化的网络可能反映了生态系统的功能分区,而高聚类系数则暗示了物种间的功能互补。在网络生态学中,这些分析有助于理解生态系统的稳定性和恢复力,预测物种灭绝的级联效应。
在R语言中,种间相关性分析和生态网络构建可以通过以下方法实现:
load(file="data/species_net_data.RData")
# 计算种间关联矩阵
library(vegan)
association_matrix <- cor(t(species_data))
knitr::kable((association_matrix), caption = "种间关联矩阵", booktabs = TRUE) %>%
kableExtra::kable_styling(latex_options = c("hold_position"))| 物种A| | 物种B| | 物种C| | 物种D| | |
|---|---|---|---|---|
| 物种A | | 1.0000000| | 0.4082483| | 0.6666667| | 0.6123724| |
| 物种B | | 0.4082483| | 1.0000000| | 0.4082483| | 0.2500000| |
| 物种C | | 0.6666667| | 0.4082483| | 1.0000000| | 0.4082483| |
| 物种D | | 0.6123724| | 0.2500000| | 0.4082483| | 1.0000000| |
# 构建生态网络
library(igraph)
# 设定相关性阈值
threshold <- 0.3
adj_matrix <- ifelse(abs(association_matrix) > threshold, 1, 0)
diag(adj_matrix) <- 0 # 移除自连接
# 创建网络对象
network <- graph_from_adjacency_matrix(adj_matrix, mode = "undirected")
# 计算网络拓扑特征
degree_dist <- degree(network)
clustering_coef <- transitivity(network, type = "global")
print(paste("平均度:", mean(degree_dist)))## [1] "平均度: 2.5"## [1] "聚类系数: 0.75"# 可视化网络
plot(network,
vertex.size = 15,
vertex.color = "lightblue",
vertex.label.family = "simhei",
vertex.label.color = "black",
edge.color = "gray",
main = "种间关联网络",
main.family = "simhei"
)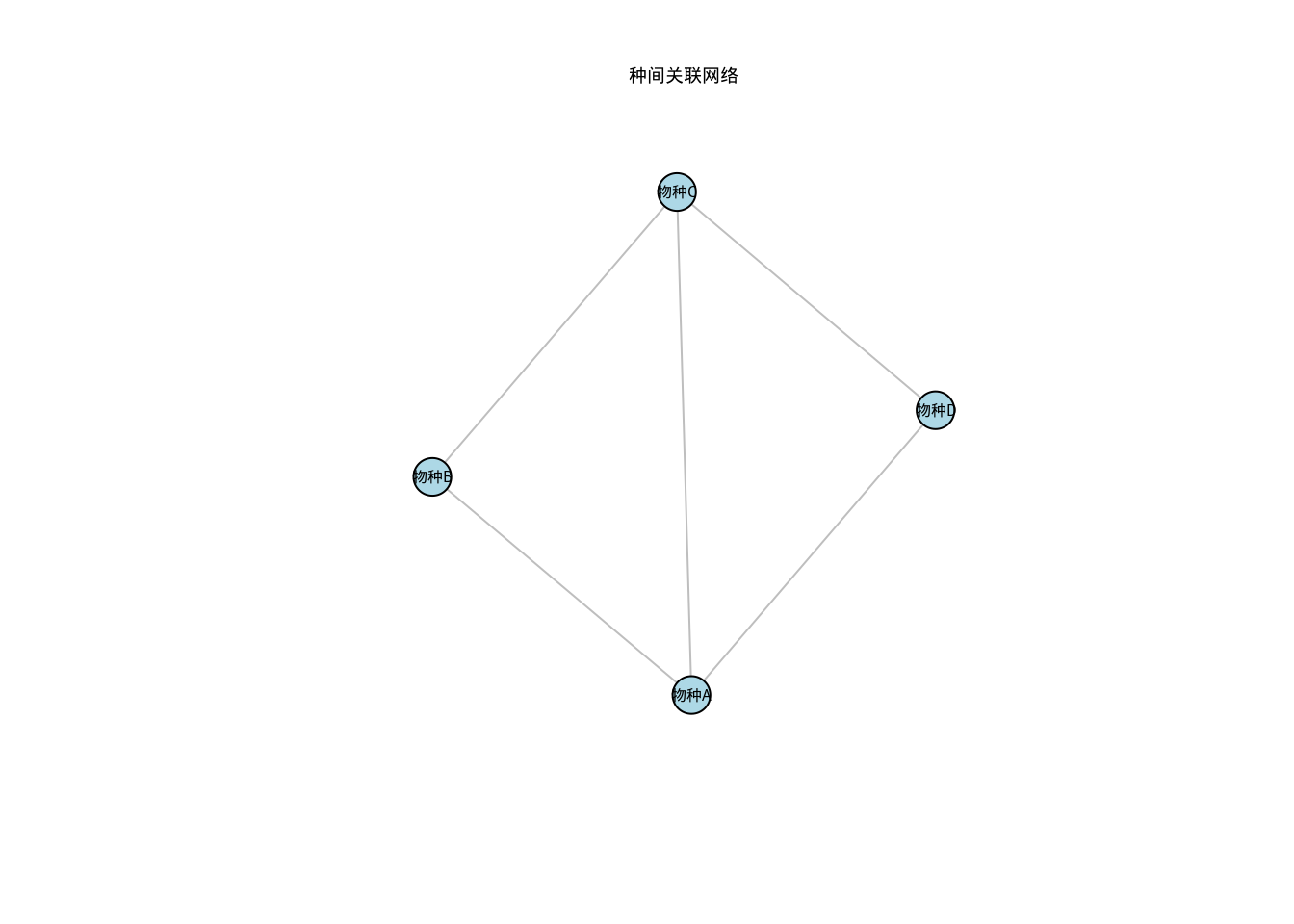
图5.44: 种间关联网络图
结果解释与生态学意义:种间相关性分析的结果解释需要结合相关系数的数值、显著性水平和生态学机制。对于种间关联系数\(\phi\),通常认为:\(|\phi| > 0.3\)表示强关联,\(0.2 < |\phi| \leq 0.3\)表示中等关联,\(|\phi| \leq 0.2\)表示弱关联。正关联\(\phi > 0\)表示物种倾向于共同出现,可能源于互利共生或相似的环境需求;负关联\(\phi < 0\)表示物种相互排斥,可能源于竞争或不同的生态位需求。
在网络分析中,度分布的特征反映了物种在群落中的连接性,幂律分布\(\gamma > 2\)的网络通常具有较好的稳定性。聚类系数\(C > 0.5\)表示网络中三角形结构丰富,可能反映了功能互补的物种组合。模块性\(Q > 0.3\)通常被认为是显著的模块结构,反映了生态系统的功能分区。这些网络特征有助于理解生态系统的稳定性和功能组织,为保护关键物种和维持生态系统功能提供科学依据。这些分析方法为生态学家提供了研究种间相互作用的定量工具,支持群落生态学和生态系统管理研究。
5.7.5 群落相似性
群落相似性分析是生态学中研究群落组成变化和空间格局的核心方法,涉及多种统计技术来量化和可视化群落间的相似性和差异性。这些方法帮助生态学家理解环境梯度、地理距离和历史因素对群落构建的影响。
Mantel检验:Mantel检验是一种用于检验两个距离矩阵相关性的统计方法,在生态学中常用于检验环境距离与群落距离之间的关系。其基本原理是通过置换检验评估两个矩阵元素间的相关性显著性,数学上计算Mantel统计量:\(r_M = \frac{\sum_{i<j}(x_{ij}-\bar{x})(y_{ij}-\bar{y})}{\sqrt{\sum_{i<j}(x_{ij}-\bar{x})^2\sum_{i<j}(y_{ij}-\bar{y})^2}}\),其中\(x_{ij}\)和\(y_{ij}\)分别为两个距离矩阵中的元素。生态学意义在于Mantel检验能够识别环境过滤、扩散限制等生态过程对群落构建的相对贡献,是群落生态学中空间分析的重要工具。
排序分析(ordination):排序分析是一类降维技术,用于在低维空间中可视化高维的群落数据。主成分分析(PCA)适用于线性响应的环境梯度,通过特征值分解找到数据变异的主要方向,数学上求解协方差矩阵的特征向量:\(\Sigma v = \lambda v\)。对应分析(CA)基于卡方距离,更适合物种多度数据,能够同时排序样方和物种。非度量多维标度(NMDS)基于秩次距离,不假设线性关系,对异常值不敏感,通过迭代优化使排序空间中的距离与原始距离矩阵尽可能一致。这些排序方法的生态学意义在于它们能够可视化群落结构和环境梯度,识别主导的生态过程和环境因子。
聚类分析(clustering):聚类分析用于识别群落类型和进行生态区划。层次聚类基于距离矩阵构建树状结构,常用方法包括单连接、完全连接和平均连接法,通过逐层合并最相似的样本形成聚类树。\(k\)均值聚类是一种划分方法,通过迭代优化将样本划分为k个簇,最小化簇内平方和:\(\sum_{i=1}^k\sum_{x\in C_i}||x-\mu_i||^2\)。这些聚类方法的生态学意义在于它们能够识别群落类型和生态区划,为生物多样性保护和生态系统管理提供科学依据。
Beta多样性:Beta多样性量化了群落组成在空间或时间上的变化,反映了物种周转和嵌套性两个组分。基于距离矩阵的方法如Bray-Curtis距离可以直接计算群落差异,而基于组分分解的方法可以将Beta多样性分解为物种周转(物种替换)和嵌套性(物种丢失)两部分:\(\beta_{total} = \beta_{turnover} + \beta_{nestedness}\)。生态学意义在于Beta多样性分析能够揭示生物多样性形成的机制,如环境过滤、扩散限制和生态位过程,是理解生物地理格局和生态系统功能的关键。
在R语言中,群落相似性分析可以通过以下方法实现:
library(vegan)
load(file="data/community_net_data.RData")
# Mantel检验
comm_dist <- vegdist(community_data, method = "bray")
env_dist <- dist(env_data)
mantel_test <- mantel(comm_dist, env_dist)
print(mantel_test)##
## Mantel statistic based on Pearson's product-moment correlation
##
## Call:
## mantel(xdis = comm_dist, ydis = env_dist)
##
## Mantel statistic r: 0.4779
## Significance: 0.013
##
## Upper quantiles of permutations (null model):
## 90% 95% 97.5% 99%
## 0.278 0.358 0.408 0.513
## Permutation: free
## Number of permutations: 999# 排序分析 - PCA
pca_result <- rda(community_data, scale = TRUE)
knitr::kable(summary(pca_result)$cont[[1]],
caption = "群落相似性PCA分析结果",
booktabs = TRUE) %>%
kableExtra::kable_styling(latex_options = c("hold_position"))| PC1 | PC2 | PC3 | PC4 | PC5 | |
|---|---|---|---|---|---|
| Eigenvalue | 2.8024582 | 1.7268720 | 0.3559326 | 0.0857154 | 0.0290218 |
| Proportion Explained | 0.5604916 | 0.3453744 | 0.0711865 | 0.0171431 | 0.0058044 |
| Cumulative Proportion | 0.5604916 | 0.9058660 | 0.9770526 | 0.9941956 | 1.0000000 |
表5.17展示了群落相似性的主成分分析结果,包括各主成分的特征值、方差解释比例和累积方差解释比例,为理解群落组成的多维变异结构提供了量化指标。
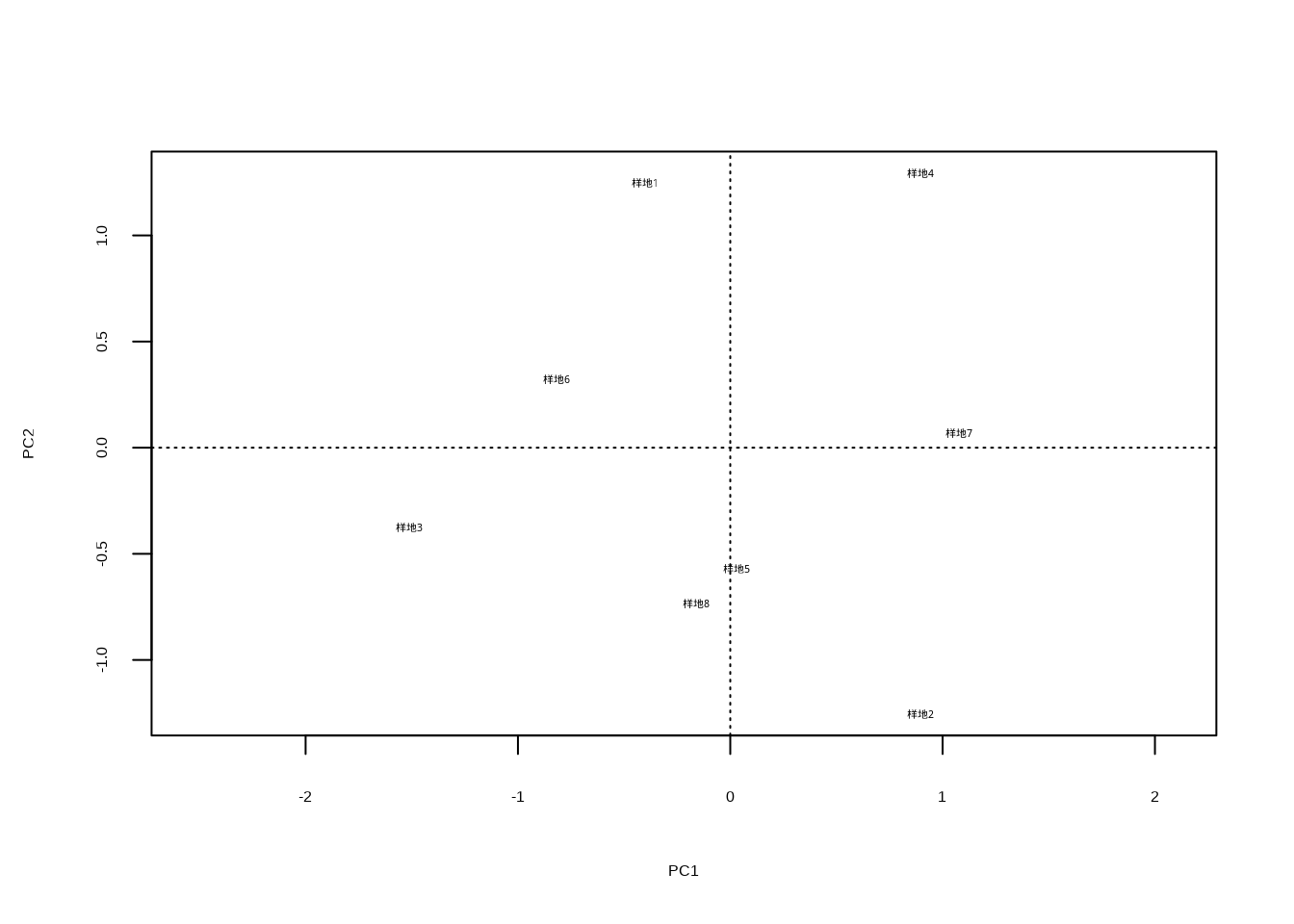
这段代码生成图??,使用plot()函数可视化PCA分析结果,display = "sites"参数指定只显示样方在排序空间中的位置。该散点图展示了不同群落样方在主成分1和主成分2构成的二维空间中的分布,样方间的距离反映了群落组成的相似性,距离越近表示群落组成越相似。这种可视化方法能够直观地展示群落结构的梯度变化、识别群落类型以及发现环境梯度对群落组成的影响模式。
# 排序分析 - NMDS
comm_dist <- vegdist(community_data, method = "bray")
nmds_result <- monoMDS(comm_dist)
plot(nmds_result, type = "t")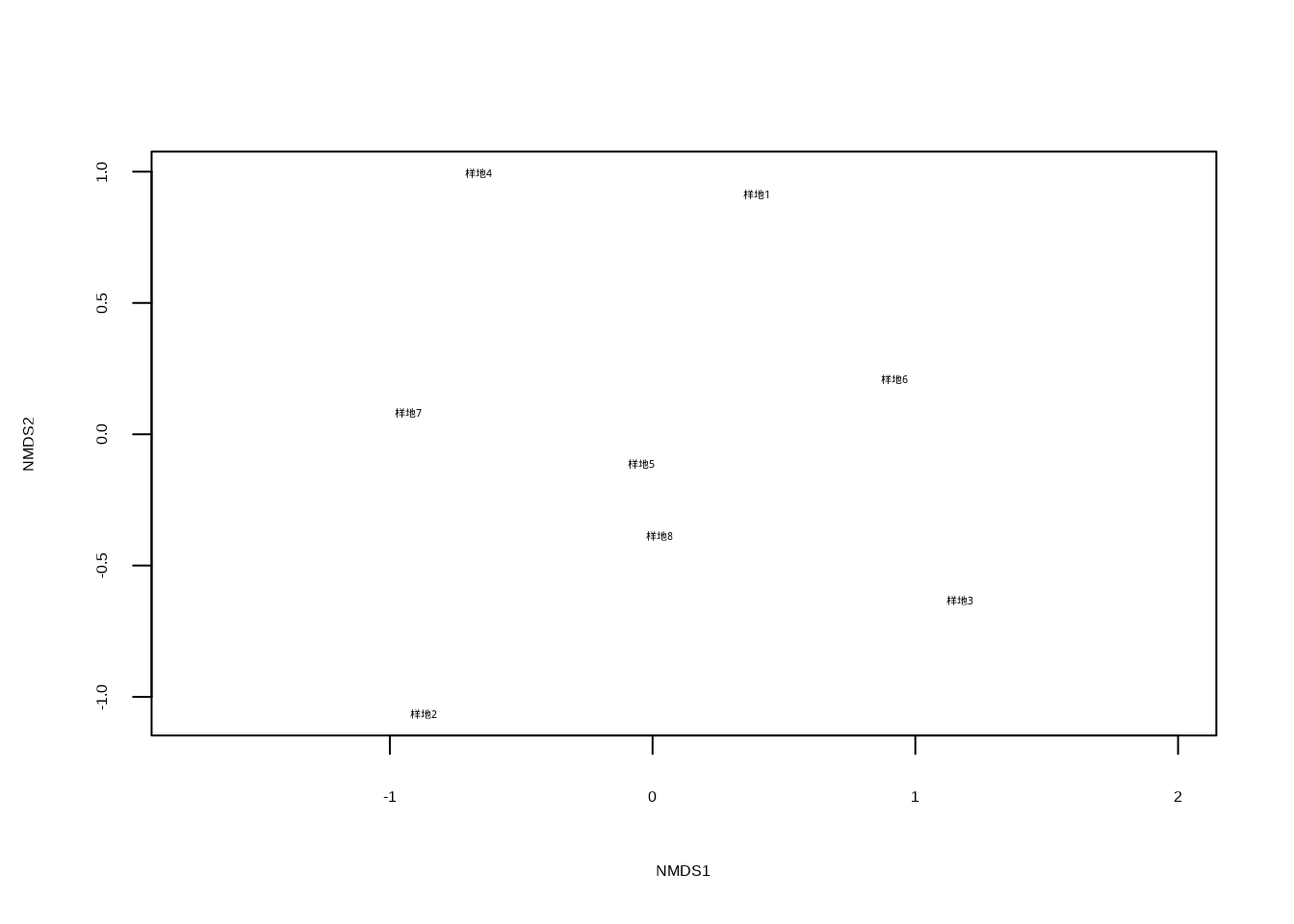
这段代码执行非度量多维尺度分析并生成图??。vegdist()函数使用Bray-Curtis距离计算群落相似性矩阵,monoMDS()函数执行NMDS排序,plot()函数可视化结果,type = "t"参数指定显示样方标签。NMDS是一种非参数排序方法,不依赖线性假设,特别适用于生态学中常见的非线性关系数据。该散点图展示了样方在NMDS排序空间中的分布,样方间距离反映了群落组成的Bray-Curtis相似性,能够更好地处理物种多度数据的非线性关系和零值问题。
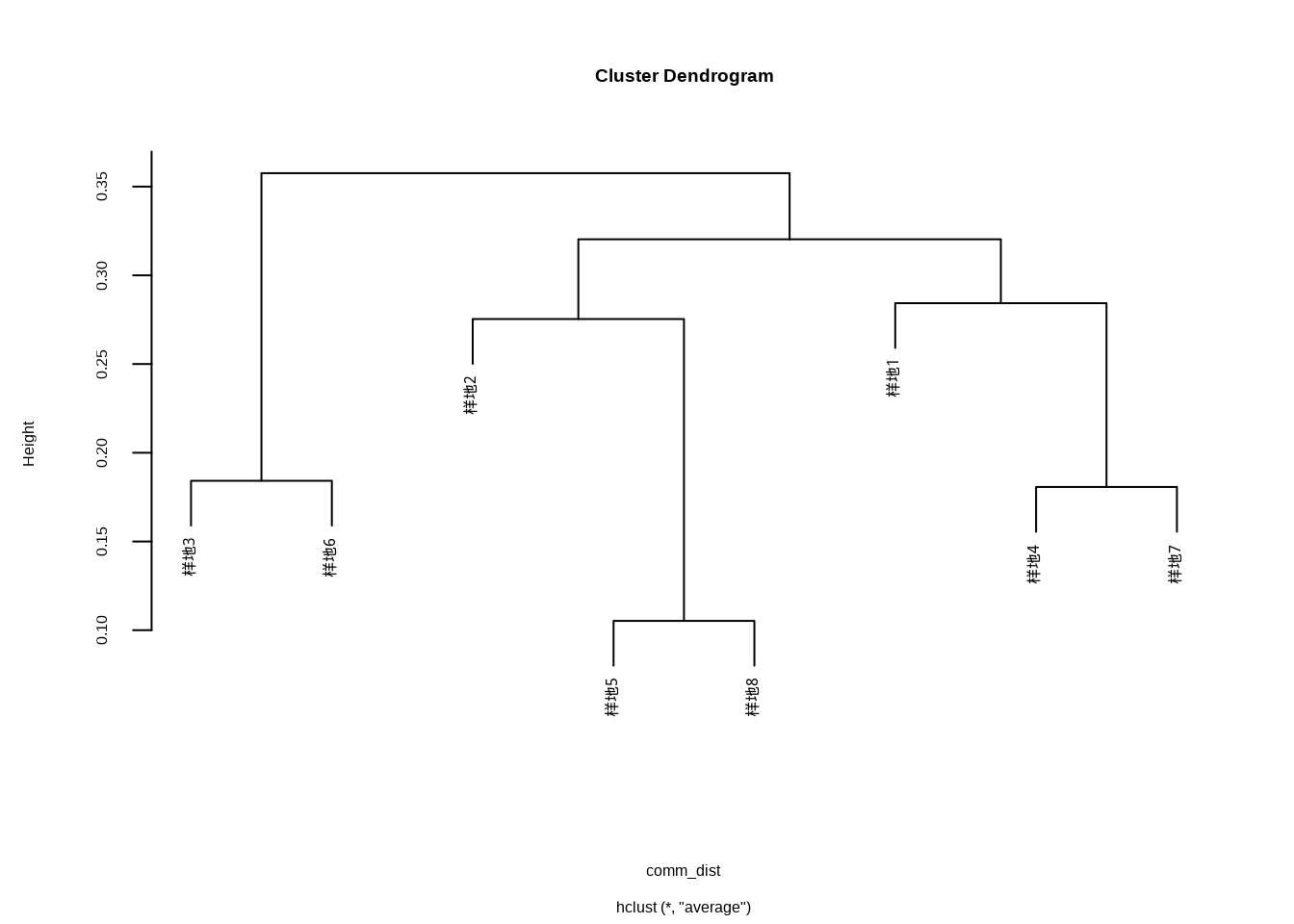
这段代码执行层次聚类分析并生成图??。hclust()函数基于群落Bray-Curtis距离矩阵执行层次聚类,method = "average"参数指定使用平均连接法(UPGMA),plot()函数可视化聚类树状图。层次聚类通过逐步合并最相似的群落样方,构建嵌套的群落分类结构,树状图的高度表示群落间的相异性程度。这种可视化方法能够清晰地展示群落的分类关系、识别群落类型以及确定合适的分类等级,为群落生态学的分类和分区研究提供直观依据。
# Beta多样性计算
beta_div <- betadiver(community_data, method = "w")
knitr::kable(as.matrix(beta_div),
caption = "群落相似性Beta多样性分析结果",
booktabs = TRUE) %>%
kableExtra::kable_styling(latex_options = c("hold_position"))| 样地1| | 样地2| | 样地3| | 地4| 样地 |
样地6| | ||||
|---|---|---|---|---|---|---|---|---|
| 样地1 | | .0000000| | .1111111| | .1111111| | .1111111| | .1111111| | .1111111| | .1111111| | .1111111| |
| 样地2 | | .1111111| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| |
| 样地3 | | .1111111| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| |
| 样地4 | | .1111111| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| |
| 样地5 | | .1111111| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| |
| 样地6 | | .1111111| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| |
| 样地7 | | .1111111| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| |
| 样地8 | | .1111111| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| | .0000000| |
表5.19展示了群落相似性的Beta多样性分析结果,使用Whittaker方法计算群落间的相异性矩阵,为理解群落组成的空间变异模式提供了量化指标。
结果解释与生态学意义:群落相似性分析的结果解释需要结合统计显著性、效应大小和生态学背景。对于Mantel检验,通常认为\(p < 0.05\)表示环境距离与群落距离存在显著相关性,而Mantel统计量\(r_M\)的大小反映了相关性的强度:\(|r_M| > 0.3\)表示强相关,\(0.2 < |r_M| \leq 0.3\)表示中等相关,\(|r_M| \leq 0.2\)表示弱相关。
在排序分析中,前两个排序轴通常能够解释数据的主要变异,累计解释率超过50%通常被认为是可接受的。排序图中样本点的聚集程度反映了群落的相似性,而环境向量的长度和方向指示了环境因子对群落变异的影响强度。在聚类分析中,树状图的切割高度决定了聚类的粒度,通常选择在树状图分支较长的位置进行切割。Beta多样性的解释需要考虑其组分:高周转率\(\beta_{turnover}\)表示物种替换是群落差异的主要机制,而高嵌套性\(\beta_{nestedness}\)表示物种丢失是主要机制。
这些分析结果的生态学解释需要结合具体的研究问题。例如,显著的环境-群落相关性可能支持环境过滤假说;高度的Beta多样性可能反映了强烈的生态位分化或扩散限制。这些分析方法为生态学家提供了全面的工具集来研究群落相似性和多样性格局,支持群落生态学和生物地理学研究。
5.8 总结
本章系统介绍了生态学中相关性与相似性分析的理论基础、方法体系及其在生态学研究中的广泛应用。相关性与相似性分析作为生态统计学的核心内容,为理解生物与环境、物种间以及群落间的复杂关系提供了定量化的工具。
在相关性统计基础部分,我们详细讨论了多种相关性度量方法。Pearson相关系数适用于线性关系的量化,Spearman秩相关和Kendall’s τ则能够处理单调但非线性的关系。偏相关分析通过控制混杂变量的影响,揭示了变量间的直接关系。距离相关和互信息进一步扩展了相关性分析的能力,能够检测复杂的非线性关系和依赖模式。这些方法的选择需要根据数据的分布特征、关系类型以及研究问题的性质来决定。
自相关分析关注数据在时间和空间维度上的依赖性。时间自相关通过自相关函数(ACF)和偏自相关函数(PACF)揭示了时间序列中的周期性、趋势和记忆效应,而平稳性检验则为时间序列分析提供了基础假设验证。空间自相关分析则通过变异函数、全局空间自相关指数(如Moran’s I和Geary’s C)以及局部空间自相关(LISA分析)来量化空间格局,识别空间聚集、离散或随机分布模式。这些分析对于理解种群动态、物种分布和环境梯度的空间结构具有重要意义。
系统发育相关性分析将进化历史纳入生态关系的考量。系统发育信号分析(如Blomberg’s K和Pagel’s λ)评估了性状在系统发育树上的保守性程度,系统发育独立对比(PIC)和系统发育广义最小二乘法(PGLS)则能够去除系统发育非独立性对性状间关系分析的影响,而通过分析系统发育聚集与分散则有助于推断群落形成的主导机制。这些方法为理解生物的进化历史和生态功能提供了进化生态学的视角。
相似性与距离分析构成了群落生态学和功能生态学的核心方法体系。常用相似性系数根据数据类型分为二元数据相似性(Jaccard、Sørensen系数)和数量数据相似性(Bray-Curtis距离、Morisita-Horn指数),而传统距离度量(欧氏距离、Mahalanobis距离)则在多元数据分析中发挥重要作用。功能性状相关性分析揭示了生物在资源分配和生态策略上的权衡关系,经济型谱理论则提供了理解植物功能策略普遍模式的框架。
种内相关性分析通过空间分布模式和聚集指数量化了同一物种个体在空间上的分布特征,反映了种内相互作用和环境异质性的综合影响。种间相关性分析则通过种间关联和生态网络构建揭示了物种间竞争、互利等相互作用的结构特性。群落相似性分析整合了Mantel检验、排序分析、聚类分析和Beta多样性等多种方法,为理解群落构建机制、环境梯度影响以及生物地理格局提供了全面的分析工具。
在结果解释方面,本章为各种统计量提供了明确的数值标准和生态学解释框架。相似性系数的数值范围、相关系数的强度分级、聚集指数的判断标准以及网络拓扑特征的阈值都为生态学家提供了实用的参考依据。这些标准的应用需要结合具体的研究背景和生态学预期,避免机械地套用数值标准而忽视生态学机制的理解。
总之,相关性与相似性分析构成了生态统计学的重要支柱,它们不仅提供了量化生态关系的数学工具,更重要的是为理解生态系统的结构、功能和动态提供了理论框架。随着生态学研究的深入和计算技术的发展,这些方法将继续在生态学理论构建、生态系统管理和生物多样性保护中发挥关键作用。掌握这些分析方法并正确理解其生态学含义,对于开展严谨的生态学研究具有重要意义。
5.9 综合练习
5.9.1 练习一:森林生态系统多变量相关性分析
背景:某生态学研究团队在温带森林中设置了40个固定样地,测量了树木胸径、树高、林分密度、土壤pH值、土壤有机质含量和林下光照强度等变量。
任务:本练习要求你使用Pearson、Spearman和Kendall’s τ三种方法分析树木胸径与树高的相关性,比较不同方法的结果并解释差异原因。进行偏相关分析,在控制林分密度的影响后,重新评估树木胸径与树高的关系。使用距离相关分析检验土壤pH值与土壤有机质含量之间的关系,判断是否存在非线性关系。构建环境因子(土壤pH、有机质、光照)与林分特征(胸径、树高、密度)的互信息网络,识别关键的环境驱动因子。
要求:提供完整的R代码实现,对每种相关性方法的结果进行生态学解释,讨论不同方法在生态学应用中的优缺点。
5.9.2 练习二:鸟类种群时间序列与空间格局分析
背景:某自然保护区对10种常见鸟类进行了为期15年的种群监测,同时在保护区内设置了50个固定观测点记录鸟类丰富度。
任务:本练习要求你选择3种具有不同生态习性的鸟类,分析其种群数量的时间自相关模式(ACF和PACF)。检验这些鸟类种群时间序列的平稳性,如发现非平稳性,进行适当的差分处理。使用变异函数分析鸟类丰富度的空间分布格局,估计块金值、基台值和变程。进行局部空间自相关分析(LISA和Getis-Ord Gi*),识别鸟类丰富度的热点和冷点区域。使用克里金插值生成保护区鸟类丰富度的空间分布预测图。
要求:提供时间序列图和空间分布图,解释时间自相关和空间自相关的生态学含义,讨论空间插值结果在保护管理中的应用价值。
5.9.3 练习三:植物功能性状与系统发育相关性分析
背景:某植物生态学研究调查了30种木本植物的功能性状,并构建了这些物种的系统发育树。测量的性状包括比叶面积、叶片氮含量、光合速率、木材密度和最大树高等。
任务:本练习要求你计算各功能性状间的Pearson相关系数矩阵,识别显著的相关关系。使用Blomberg’s K和Pagel’s λ检验各性状的系统发育信号强度。对具有显著系统发育信号的性状,使用系统发育独立对比(PIC)重新分析性状间关系。构建功能性状的经济型谱,分析比叶面积、叶片氮含量和光合速率之间的权衡关系。使用主成分分析探索功能性状的多维协变模式。
要求:提供系统发育树与性状分布的可视化,比较传统相关分析与PIC分析的结果差异,讨论功能性状相关性的生态适应意义。